







转自:https://www.cnblogs.com/jiangzhaowei/p/5740913.html
关键内容:
1.
对于不可变对象和可变对象来说,浅复制都是复制的引用,只是因为复制不变对象和复制不变对象的引用是等效的(因为对象不可变,当改变时会新建对象重新赋值)。所以看起来浅复制只复制不可变对象(整数,实数,字符串等),对于可变对象,浅复制其实是创建了一个对于该对象的引用,也就是说只是给同一个对象贴上了另一个标签而已。
举个栗子:
在解释之前应注意到:
-
不可变类型:类似 c++ 的值传递,如 整数、字符串、元组。如fun(a),传递的只是a的值,没有影响a对象本身。比如在 fun(a)内部修改 a 的值,只是修改另一个复制的对象,不会影响 a 本身。
-
可变类型:类似 c++ 的引用传递,如 列表,字典。如 fun(la),则是将 la 真正的传过去,修改后fun外部的la也会受影响
-
另外,不可变的类型可以计算hash值,作为字典的key。可变类型数据对对象操作的时候,不需要再在其他地方申请内存,只需要在此对象后面连续申请(+/-)即可,也就是它的内存地址会保持不变,但区域会变长或者变短。对于可变对象,对象的操作不会重建对象,而对于不可变对象,每一次操作就重建新的对象。
-
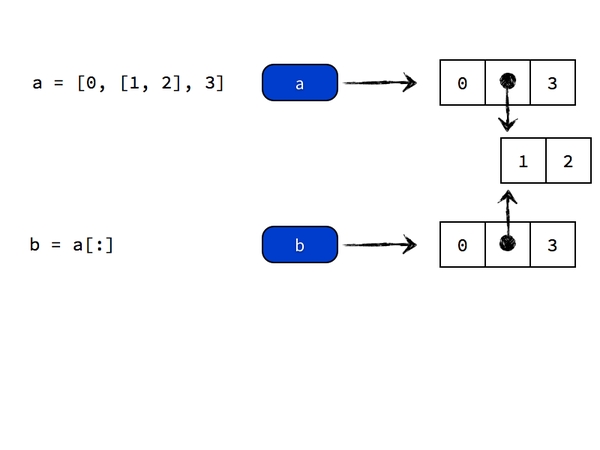
标签a所引用的对象的第一和第三个元素都是整数(不可变类型),而第二个对象是列表(可变类型),因此使用b=[:]进行浅复制的过程中会出现a和b引用的对象的第二个元素指向同一个列表[1,2]的情况。正确的复制嵌套元素的方法是进行「深复制」(deep copy),方法是
a = [0, [1, 2], 3]
b = copy.deepcopy(a)
2. x=x+y和x+=y的区别
+=操作首先调用对象的_iadd_方法,如果没有该方法就调用_add_方法。需要注意的是:不可变对象没有_iadd_方法。
L = [1, 2]
M = L
L = L + [3, 4]
print L, M
print "-------------------"
L = [1, 2]
M = L
L += [3, 4]
print L, M
以上代码的前半部分中,用图表示为:

而_iadd_属于 in-place 操作,即原地操作,并不使用新的内存。用图表示为:

3. 函数值传递
def func_int(a):
a += 4
def func_list(a_list):
a_list[0] = 4
t = 0
func_int(t)
print t
# output: 0
t_list = [1, 2, 3]
func_list(t_list)
print t_list
# output: [4, 2, 3]在函数参数传递的时候,Python其实就是把参数里传入的变量对应的对象的引用依次赋值给对应的函数内部变量。参照上面的例子来说明更容易理解,func_int中的局部变量"a"其实是全部变量"t"所指向对象的另一个引用,由于整数对象是不可变的,所以当func_int对变量"a"进行修改的时候,实际上是将局部变量"a"指向到了整数对象"1"。所以很明显,func_list修改的是一个可变的对象,局部变量"a"和全局变量"t_list"指向的还是同一个对象。
4. 为什么修改字典d的值不用global关键字先声明呢?
s = 'foo'
d = {'a':1}
def f():
s = 'bar'
d['b'] = 2
f()
print s # foo
print d # {'a': 1, 'b': 2}这是因为,在s = 'bar'这句中,它是“有歧义的“,因为它既可以是表示引用全局变量s,也可以是创建一个新的局部变量,所以在python中,默认它的行为是创建局部变量,除非显式声明global,global定义的本地变量会变成其对应全局变量的一个别名,即是同一个变量。
在d['b']=2这句中,它是“明确的”,因为如果把d当作是局部变量的话,它会报KeyError,所以它只能是引用全局的d,故不需要多此一举显式声明global。
上面这两句赋值语句其实是不同的行为,一个是rebinding(不可变对象), 一个是mutation(可变对象).
但是如果是下面这样:
d = {'a':1}
def f():
d = {}
d['b'] = 2
f()
print d # {'a': 1}
在d = {}这句,它是”有歧义的“了,所以它是创建了局部变量d,而不是引用全局变量d,所以d['b']=2也是操作的局部变量。
推而远之,这一切现象的本质就是”它是否是明确的“。
仔细想想,就会发现不止dict不需要global,所有”明确的“东西都不需要global。因为int类型str类型之类的不可变对象,每一次操作就重建新的对象,他们只有一种修改方法,即x = y, 恰好这种修改方法同时也是创建变量的方法,所以产生了歧义,不知道是要修改还是创建。而dict/list/对象等可变对象,操作不会重建对象,可以通过dict['x']=y或list.append()之类的来修改,跟创建变量不冲突,不产生歧义,所以都不用显式global。
5. 可变对象 list 的 = 和 append/extend 差别在哪?
接上面 5.3 的理论,下面咱们再看一例常见的错误:
# coding=utf-8
# 测试utf-8编码
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
list_a = []
def a():
list_a = [1] ## 语句1
a()
print list_a # []
print "======================"
list_b = []
def b():
list_b.append(1) ## 语句2
b()
print list_b # [1]大家可以看到为什么 语句1 不能改变 list_a 的值,而 语句2 却可以?他们的差别在哪呢?
因为 = 创建了局部变量,而 .append() 或者 .extend() 重用了全局变量。
陷阱:使用可变的默认参数
我多次见到过如下的代码:
def foo(a, b, c=[]):
# append to c
# do some more stuff永远不要使用可变的默认参数,可以使用如下的代码代替:
def foo(a, b, c=None):
if c is None:
c = []
# append to c
# do some more stuff与其解释这个问题是什么,不如展示下使用可变默认参数的影响:
In[2]: def foo(a, b, c=[]):
... c.append(a)
... c.append(b)
... print(c)
...
In[3]: foo(1, 1)
[1, 1]
In[4]: foo(1, 1)
[1, 1, 1, 1]
In[5]: foo(1, 1)
[1, 1, 1, 1, 1, 1]同一个变量c在函数调用的每一次都被反复引用。这可能有一些意想不到的后果。















 5748
5748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









