






【1】离散的概率分布律:p(x=k)=pk。这样可以一目了然的看出x所可能的取值和对应的概率。
【2】对于连续随机变量来说,p(x=k)=(x为k的个数/总个数),因为总个数无穷个,概率趋向于0。所以我们引入概率密度函数,一目了然看出落在x的某一值附近的概率大小(两方面理解:1.连续不说某一值的概率,而是区间。2.概率的大小是积分,而当积分区域无限小,就可以看成一条直线,即y值)
所以在连续随机变量上引入密度函数可以得到和离散的概率分布一样的效果!也就是说概率密度函数也就是概率!
【3】似然函数:
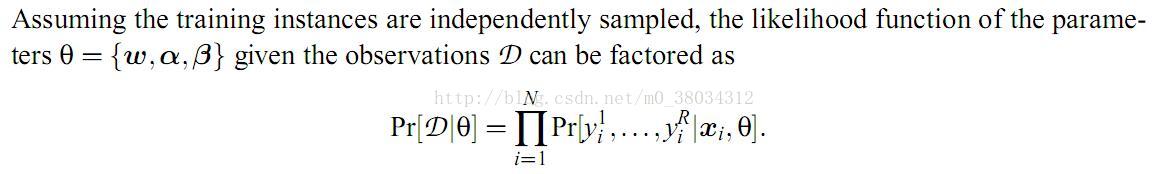
1、有两个问题:问题一:似然函数不是概率密度函数么 解释一下:概率密度函数的本质就是概率,见上面分析 问题二:似然函数的具体是用来形容什么的?一种解释是观测值出现的概率,即样本点的联合分布函数
2、常说的概率指的是给定参数后,即将发生的事件的可能性。
而似然函数真好相反,我们不再关注事件的发生概率,而是已知发生了某些事件,我们希望知道参数是多少?
所以总结一下:似然函数其实是关于观测值出现的概率函数,我们求得使似然函数最大的参数,得到希望知道的分布。
似然函数实质就是概率密度函数。只是似然函数中已知x求参数,而概率密度函数是已知参数来求x发生的概率值的
这种相同又不同的关系才产生了以下小故事:在英语语境里,likelihood 和 probability (也就是概率的英文)的日常使用是可以互换的,都表示对机会 (chance) 的同义替代。但在数学中,probability 这一指代是有严格的定义的,即符合柯尔莫果洛夫公理 (Kolmogorov axioms) 的一种
数学对象(换句话说,
不是所有的可以用0到1之间的数所表示的对象都能称为概率),而 likelihood (function) 这一概念是由Fisher提出,他采用这个词,也是为了凸显他所要表述的
数学对象既和 probability 有千丝万缕的联系,但又不完全一样的这一感觉。中文把它们一个翻译为
概率一个翻译为
似然也是独具匠心。














 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









