







目录
一、Spring MVC和Spring boot有啥区别
1.Spring MVC和Spring Boot都是Spring的一部分,且两者都是由IOC提供了依赖注入的容器,由AOP解决面相切面编程(IOC和AOP后续会讲到),然后在此二者基础上衍生的高级功能。SpringMVC的配置比Springboot的配置要复杂得多,各种xml和properties配置文件,处理起来比较繁琐;Springboot他遵循约定优于配置,啥意思呢,就是全都是用默认的配置,这样极大地降低了Spring使用的门槛。
2.Springboot的涉及面比SpringMVC要广,Springboot不仅可以集成Spring MVC,还可以集成JPA Security等,如下图所示: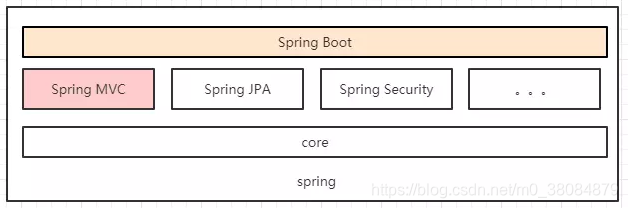
3.SpringMVC和Sringboot都属于Spring,SpringMVC是基于Spring的一个MVC框架,Springboot是基于Spring的一套快速开发整合包。
总结:Spring 最初利用“工厂模式”( DI )和“代理模式”( AOP )解耦应用组件。大家觉得挺好用,于是按照这种模式搞了一个 MVC 框架(一些用 Spring 解耦的组件),用开发 web 应用( SpringMVC )。然后有发现每次开发都要搞很多依赖,写很多样板代码很麻烦,于是搞了一些懒人整合包( starter ),这套就是 Spring Boot 。
二、session和cookie的区别
1.session是存在服务器端的,cookie是存在浏览器端。
2.cookie相对于session是不安全的。因为cookie是存在浏览器端,别人可以通过分析本地的cookie进行cookie欺骗,如果考虑安全问题,应该使用session。
3.session会在一定时间内存储在服务器上。如果用户量较大,会影响服务器性能,考虑到服务器性能因素,可以使用cookie。
4.一般单个cookie不能超过4k。很多浏览器设置最多保存20个cookie,而session是无限量的。
三、复合索引生效失效场景
复合索引又叫联合索引,是由表中的几个列联合组成的。
复合索引生效需要满足最左前缀原则:(一定要从左到右连续才生效)
即如果复合索引列为a,b,c三列,那么查询条件为a、a,b、a,b,c时,索引生效,b,c、a,c、b、c等不生效(这里的顺序不是where条件后面的先后顺序,而是where条件中是否存在这些列,如果where中只存在a,c列,则索引不生效)
四、JDK、JRE、JVM的联系与区别
JDK,java development kit,java开发工具包;
JRE,java runtime enviroment,java运行环境;
JVM,java virtual machine,java虚拟机;
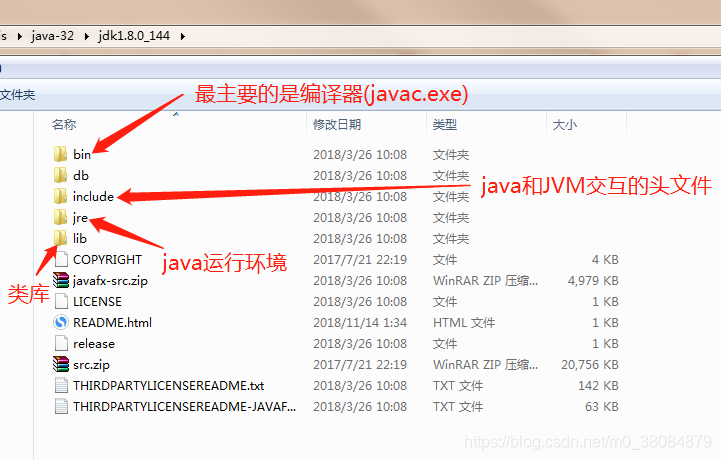
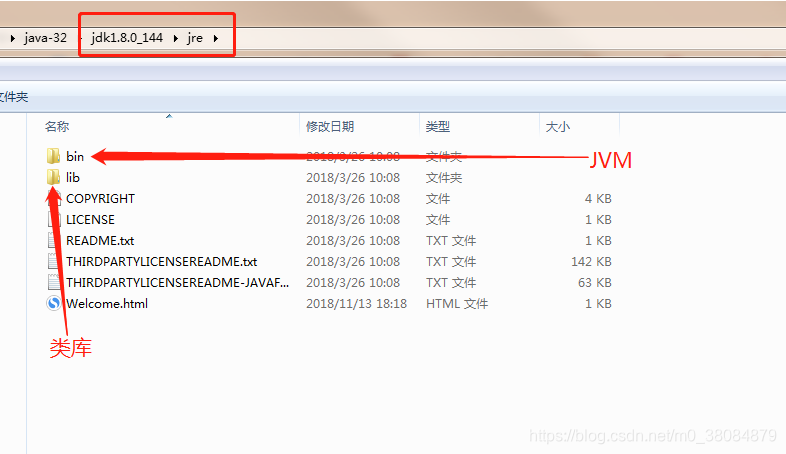
在JDK安装目录下有一个jre目录,jre目录下面有bin和lib两个文件夹,我们可以认为bin里面就是jvm,lib就是jvm运行所需的类库,jvm和lib结合起来就是jre。
【JDK目录结构】
【JDK-->JRE目录结构】
下面我们由下图来描述一下三者关系:
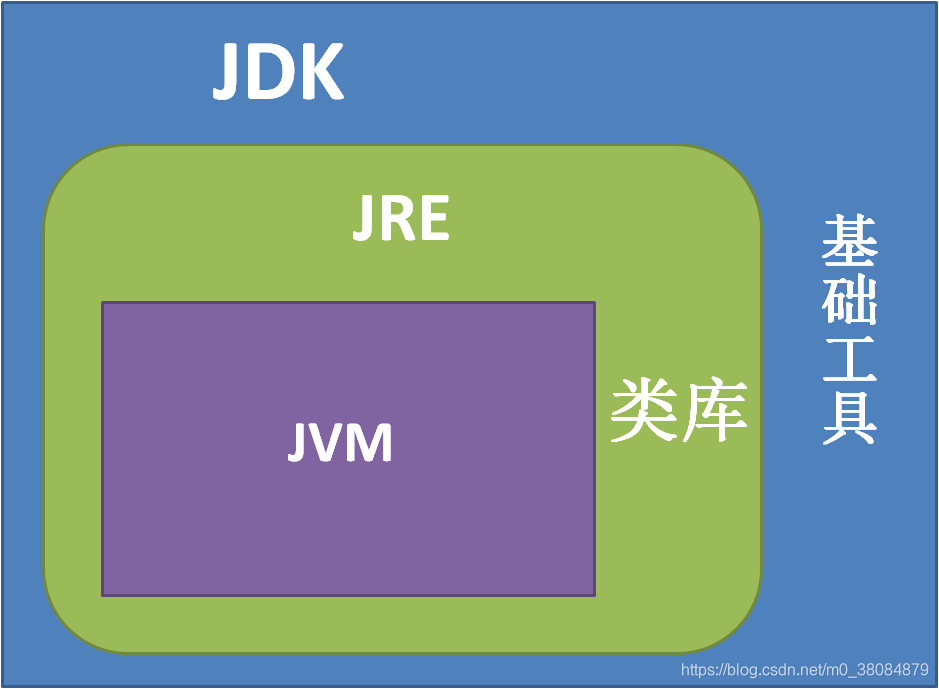
1.JDK提供开发工具包,编译都是在JDK中进行的(由.java编译为.class),但运行不是在JDK中进行;
2.JRE由JVM和类库组成,
3.JVM借助jre提供的类库,运行.Java程序,java做到跨平台的特性,就是由于不同的平台拥有不同的JVM或JDK,才得以实现。
五、如果main方法被声明为private会怎样?
我们想一下,如果如果类中没有main方法,会怎么样?当然是没啥问题!
如果将修饰符改为private,其实也没啥问题。
如果将修饰符改为private,就相当于我们自己定义了一个方法,名字叫main,当我们运行这个类的时候,会提示我们“找不到main方法,请将main方法定义为public static void main(String[] args)”,因为这里只有我们自定义的一个private main方法,而没有系统默认的public main方法。
如果这时我们再写一个public static void main(String[] args),这时候也会报错,因为已经存在了一个private static void main(String[] args),同一个类中不能存在方法名和参数相同的两个方法,因为重载的定义为“方法名相同,参数不同的两个方法叫重载”,所以和修饰符无关。
六、&和&&有啥区别
1.&是位运算符,按二进制进行运算;
比如5 & 4就是将5和4分别转换为二进制5(00000101)和二进制4(00000100)进行“与”运算。我们顺便提一下&(与)、“~”(非)、“|”(或)、“^”(异或)四种运算符规则:
【均需要转换成二进制】
| 运算符 | 运算方式 |
| &(与) | 两个数转换为二进制,然后从高位开始比较,如果所比较的两个数都是1则为1,否则为0 |
| |(或) | 两个数转换为二进制,然后从高位开始比较,如果所比较的两个数有一个是1则为1,否则为0 |
| ~(非) | 如果该为为0,结果是1;如果该为是1,结果为0 |
| ^(异或) | 两个数转换为二进制,然后从高位开始比较,两个数相同为0,不同 |
例: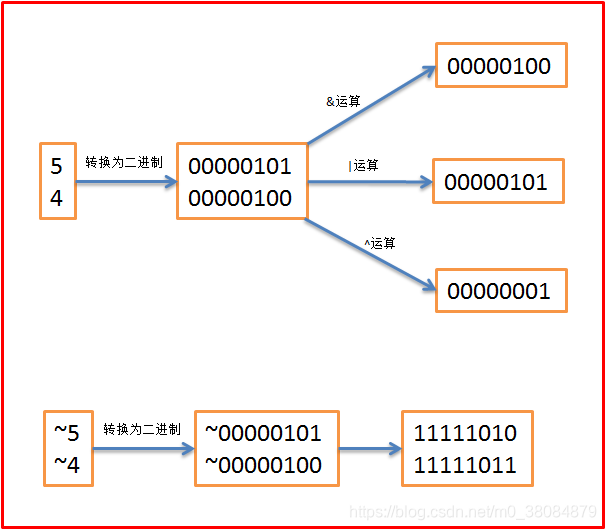
2.&&是逻辑运算符,比较两个Boolean表达式。
&&运算符对两个Boolean表达式进行比较,当比较的两个均为true时,结果才是true,有一个false,结果就是false。
并且&&运算符具有短路功能,如果比较的前者为false,&&后面将不会运行,如果为true,将会继续运行&&后面的代码;
||运算符同样具有短路功能。
七、char类型的变量能不能存储一个中文?为什么
答案是可以的,但是两个中文不行。因为char占两个字节,一个中文也占两个字节,所以是可以存储的。
八、a=a+b和a+=b的区别
a=a+b是先进行“+”运算,然后进行赋值运算,如果当a(short)与b(int)的类型不同时,会报错,若进行强转,可能会导致精度丢失。
a+=b中,“+=”是一个运算符,而不是两个,所以在运算时 会进行自动类型转换。
总结一下,在两个变量的数据类型一样时:a+=b 和a=a+b 是没有区别的。
但是当两个变量的数据类型不同时,就需要考虑一下数据类型自动转换的问题了。
也就是涉及到精度了。
这里顺便提一下,如何解决浮点型精度丢失的问题。
使用BigDecimal即可,具体使用方法可参考这个链接使用BigDecimal进行精确运算 - chenssy - 博客园
九、sql查询出重复值系列
1、查找多余的重复记录,重复记录是根据字段username进行判断:
SELECT
*
FROM
student
WHERE
username IN (
SELECT
username
FROM
student
GROUP BY
username
HAVING
count(username) > 1
)查询结果如下:

2、删除表中多余的重复记录,重复记录是根据单个字段username进行判断,并且只保留rowid最小的记录:
十、雪花算法的id由哪些部分组成?
1.符号位,占用1位
2.时间戳,占用41位
3.机器id,占用10位
4.序列号,占用12位

十一、Spring事务什么时候会失效?
- bean对象没有被spring容器管理
- 方法的访问修饰符不是public
- 自身调用问题
- 数据源没有配置事务管理器
- 数据库不支持事务
- 异常被捕获
- 异常类型错误或者配置错误
十二、Spring事务的隔离级别有哪些?
Spring事务隔离级别比数据库事务隔离级别多一个default
1) DEFAULT (默认)
这是一个PlatfromTransactionManager默认的隔离级别,使用数据库默认的事务隔离级别。另外四个与JDBC的隔离级别相对应。
2) READ_UNCOMMITTED (读未提交)
这是事务最低的隔离级别,它允许另外一个事务可以看到这个事务未提交的数据。这种隔离级别会产生脏读,不可重复读和幻像读。
3) READ_COMMITTED (读已提交)
保证一个事务修改的数据提交后才能被另外一个事务读取,另外一个事务不能读取该事务未提交的数据。这种事务隔离级别可以避免脏读出现,但是可能会出现不可重复读和幻像读。
4) REPEATABLE_READ (可重复读)
保证在一个事务内,同样的查询语句读到的数据是一样的,不会受到其他事务的update语句影响,可以理解为事务开启那一刻,产生了数据库的快照,读取的数据都是快照中的数据,所以,可重复读又称快照读。这种事务隔离级别可以防止脏读、不可重复读,但是可能出现幻像读(insert、delete)。它除了保证一个事务不能读取另一个事务未提交的数据外,还保证了不可重复读。
5) SERIALIZABLE(串行化)
这是花费最高代价但是最可靠的事务隔离级别,事务被处理为顺序执行。除了防止脏读、不可重复读外,还避免了幻像读。
不可重复读针对同一条数据进行操作,幻读针对的是一批数据进行操作。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
十三、B树和B+树的区别
B树:
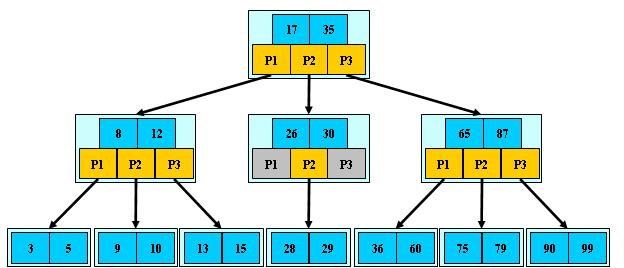
- 关键字几何分布在整棵树中,即叶子结点和非叶子结点都存放数据。
- 搜索有可能在非叶子结点结束。
B+树:
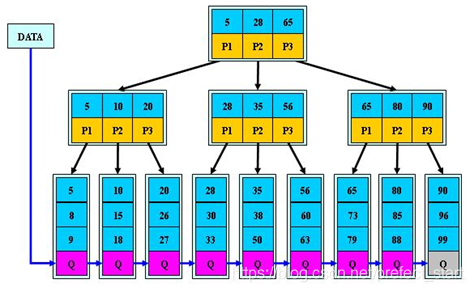
- B+树的非叶子结点不保存关键字记录的指针,只进行数据索引,这样使得B+树每个非叶子结点所能保存的关键字大大增加;
- B+树叶子结点保存了父节点的所有关键字记录的指针,所有数据地址必须要到叶子节点才能获取到,所以每次数据查询的次数都一样的;
- B+树叶子节点的关键字从小到大有序排列,左边结尾数据都会保存右边节点开始数据的指针。
十四、简述java代理模式
提供了对对象的另外的访问方式,即通过代理对象访问目标对象,这样做的好处就是,可以在目标对象实现的基础上,增强额外的功能操作。代理模式分为静态代理和动态代理。
- 静态代理做到不修改目标对象功能的前提下,对目标功能进行扩展;但因为代理对象需要与目标对象实现一样的接口,所以会有很多代理类,类太多的时候,一旦接口增加方法,目标对象与代理对象都要维护。
- JDK的动态代理不需要实现接口,但是目标对象一定要实现节课,否则不能使用动态代理,如果目标对象没有实现接口,就需要使用CGlib。
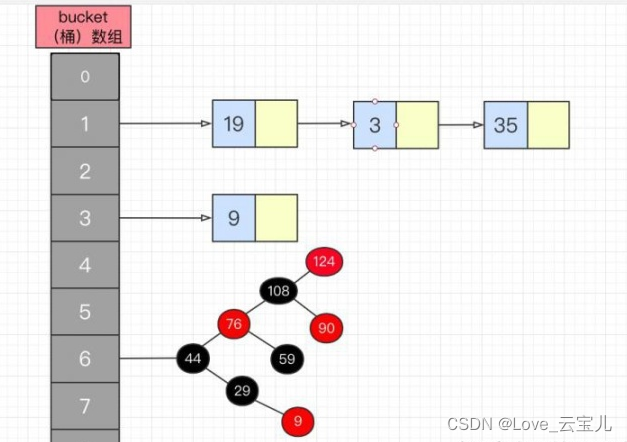
十五、简述HashMap的put与get的过程
map.put(k,v)实现原理
1.首先将k,v封装到Node节点当中
2.然后通过哈希算法计算出当前key的hash值
3.再利用哈希函数计算出当前hash值对应的数组索引下标
如果下标没有任何元素,就把这个node添加到这个位置上;如果下标位置有链表,然后在用k和链表上的每一个k进行equals操作;如果所有equals都返回false,就将这个node追加到末尾,如果有一个返回了true,就替换该节点;
jdk1.8以后,如果链表的长度超过了8,那么链表将会转换为红黑树进行存储,以免遍历节点的时候浪费太多时间。
map.get(k)实现原理
1.先调用k的hashCode方法获取k的hash值,然后通过哈希算法获取到数组索引下标;
2.通过下标定位到数组对应的位置上
如果该位置啥也没有,返回null;
如果该位置上有链表或者红黑树,将node的k与链表的k进行equals比较如果有true,则返回该节点的。如果均为false,则返回null。
十六、什么是数据库回表?如何避免数据库回表
当mysql查询时,使用二级索引查到相应的叶子节点获取主键值,然后通过主键索引再查询到相应的数据行信息。其中,找到主键后,通过主键索引找到相应数据行的过程叫做回表。
如何避免回表的几种方式:
- 覆盖索引:将我们查询的字段设置为二级索引,这样我们通过二级索引就可以获得我们想要的值而不用回表。多字段的话需要遵循最佳左缀原则(参考第三条 复合索引失效场景);count(*)时,如果正好存在一个辅助索引,则会通过查询辅助索引统计数量,减少I/O
- 直接使用主键查询
十七、redis持久化方案有哪些?
- RDB:将redis在内存中的数据库记录定时dump到磁盘上的RDB持久化
- AOF:将Redis的操作日志以追加的方式写入文件
二者区别:
RDB持久化是指在指定的时间间隔内,将内存中的数据集快照写入磁盘,实际操作过程是fork()一个子进程(fork完以后,父进程和子进程有相同的数据段和代码段),先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
RDB优缺点:
优点:
- 容灾备份非常方便,整个redis数据库只有一个文件,转移方便
- 性能比AOF好,因为他是有子进程fork进行持久化的,避免服务进程进行IO操作
缺点:
- 如果系统在持久化之前宕机,那么此前没来得及写入磁盘的数据都将会丢失
- 当数据集较大时,fork子进程时,耗时较大,可能会延迟服务反应时间
AOF优缺点:
优点:
- 这种机制可以每秒同步一次,甚至每次写入删除都可以同步一次,这样即便服务宕机,也不会造成数据丢失
- 该机制才用的是append模式,即便是在写入过程中宕机,也不会破坏日志中已存在的内容;如果是写入了一半儿就宕机了,在下一次启动之前,我们可以通过redis-check-aof工具解决数据一致性问题。
- 它包含了一个清晰的数据操作日志,也可以通过这种操作日志恢复数据
缺点:
- 数据量大于RDB,因为它包含了全部操作日志
- 每次都要做IO,效率慢于RDB
十八、redis主从复制集群是如何保障数据的一致性的呢?
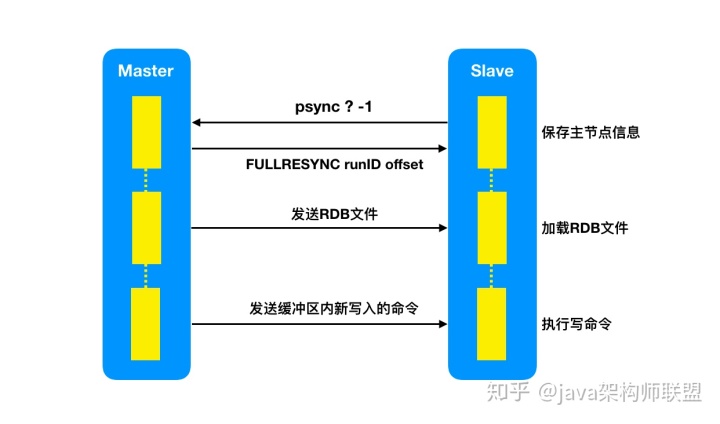
runID:每个redis实例生成的随机且唯一的ID,这里表示的是主节点的ID
offset:复制偏移量。
主从一致性原理:
从节点第一次进行连接时,主节点会生成RDB文件进行全量复制,同时将新写入的命令存入缓冲区,发送给从节点,保障数据一致性。
多从节点的时候,可以选用级联的方式保障数据同步。
网络断开重连后,主从节点通过维护偏移量来同步写命令。
十九、redis是如何实现单线程的
Redis客户端对服务端的每次调用都经历了发送命令、执行命令、返回结果三个过程。其中执行命阶段,所有命令都会进入一个队列中,然后逐个被执行。所以不会出现两条命令同时被执行,不会产生并发问题。
单线程指的是网络请求模块使用了一个线程(所以不需考虑并发安全性),即一个线程处理所有网络请求,其他模块仍用了多个线程。
二十、简述mybatis的一级缓存和二级缓存
一级缓存默认是开启的,缓存范围是以sqlsession会话为一次
二级缓存默认关闭,需要手动开启,它是以mapper的namespace为一个范围,即只要你通过这个namespace查的话,就会缓存,如果你在其他的namespace对这个表进行操作,再通过原来的namespace进行查找的话,查找的仍然是缓存的内容,不会更新;
二十一、ArrayList和LinkedList的区别
ArrayList:基于动态数组,连续内存存储,适合下标访问(随机访问),扩容机制:因为数组长度固定,超出长度存数据时需要新建数组(1.5倍扩容机制),然后将老数组的数据拷贝到新数组,如果不是尾部插入数据还会涉及到元素的移动(往后复制一份,插入新元素),使用尾插法并指定初始容量可以极大提升性能,甚至超过linkedList,因为linkedList需要创建大量node对象。
LinkedList:基于链表,可以存储在分散的内存中,适合做数据插入及删除操作,不适合查询:需要逐一遍历。遍历LinkedList尽量使用iterator,别用for循环,因为for循环体内通过get(i)取得某一元素时都需要对list重新进行遍历,性能消耗极大。另外不要试图使用indexOf等返回元素索引,并利用其进行遍历,使用indexOf对list进行了遍历,当结果为null时会遍历整个列表。














 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









