







0、前言
RNN网络因为使用了单词的序列信息,所以准确率要比前向传递神经网络要高。
网络结构:
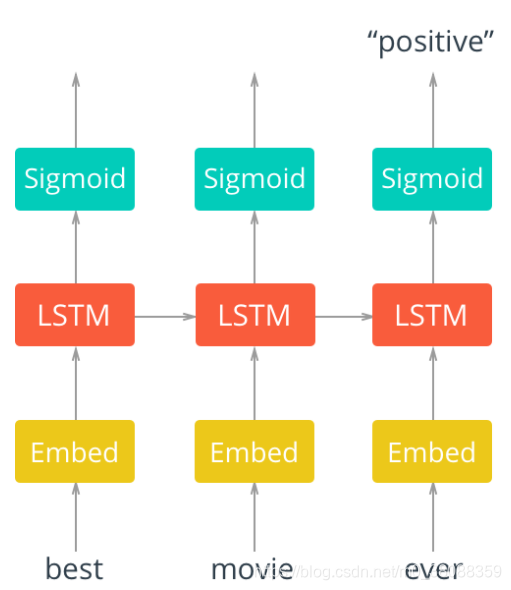
首先,将单词传入 embedding层,之所以使用嵌入层,是因为单词数量太多,使用嵌入式词向量来表示单词更有效率。在这里我们使用word2vec方式来实现,而且特别神奇的是,我们只需要加入嵌入层即可,网络会自主学习嵌入矩阵。
通过embedding 层, 新的单词表示传入 LSTM cells。这将是一个递归链接网络,所以单词的序列信息会在网络之间传递。最后, LSTM cells连接一个sigmoid output layer 。 使用sigmoid可以预测该文本是 积极的 还是 消极的 情感。输出层只有一个单元节点(使用sigmoid激活)。
只需要关注最后一个sigmoid的输出,损失只计算最后一步的输出和标签的差异。
文件说明:
(1)reviews.txt 是原始文本文件,共25000条,一行是一篇英文电影影评文本
(2)labels.txt 是标签文件,共25000条,一行是一个标签,positive 或者 negative
1、Data preprocessing
建任何模型的第一步,永远是数据清洗。 因为使用embedding 层,需要将单词编码成整数。
我们要去除标点符号。 同时,去除不同文本之间有分隔符号 \n,我们先把\n当成分隔符号,分割所有评论。 然后在将所有评论再次连接成为一个大的文本。
import numpy as np
import tensorflow as tf
with open('./data/reviews.txt', 'r') as f:
reviews = f.read()
with open('./data/labels.txt', 'r') as f:
labels = f.read()
from string import punctuation
#移除所有标点符号
all_text = ''.join([c for c in reviews if c not in punctuation])
print(all_text[:1000])
# 以'\n'为分隔符,拆分文本
reviews = all_text.split('\n')
all_text = ' '.join(reviews)
# 文本拆分为单独的单词列表
words = all_text.split()
处理结果示例:

2、Encoding the words
embedding lookup要求输入的网络数据是整数。最简单的方法就是创建数据字典:{单词:整数}。然后将评论全部一一对应转换成整数,传入网络。
from collections import Counter
count = Counter(words)
#按技术进行排序
vocab = sorted(count,key=count.get,reverse=True)
# 生成字典:{单词:整数}
vocab_to_int = {word:i for i,word in enumerate(vocab,1)}
# 将文本列表 转换为 整数列表same shape ==reviews list
reviews_ints = []
for each in reviews:
reviews_ints.append([vocab_to_int[word] for word in each.split()])
补充enumerate函数用法:
在enumerate函数内写上int整型数字,则以该整型数字作为起始去迭代生成结果。
a = {"a":4,"b":3}
for i,e in enumerate(a,1):
print(i,e)
输出:
1 a
2 b
3、Encoding the labels
将标签 “positive” or "negative"转换为数值。
# 将标签转换为数值:positive==1 和 negative ==0
labels = labels.split('\n')
labels = np.array([1 if each=='positive' else 0 for each in labels])
统计已经转乘词id的句子的长度:
from collections import Counter
review_lens = Counter([len(x) for x in reviews_ints])
print("Zero-length reviews: {}".format(review_lens[0]))
print("Maximum review length: {}".format(max(review_lens)))
输出:
Zero-length reviews: 1
Maximum review length: 2514
将所以句子统一长度为200个单词:
1、评论长度小于200的,我们对其左边填充0
2、对于大于200的,我们只截取其前200个单词
但发现这些评论里面有一个评论长度为0,则在做以上处理前先将这评论移除。
# 从 reviews_ints列表中移除0长度的评论
non_zero_idx = [i for i,review in enumerate(reviews_ints) if len(review)>0]
#len(non_zero_idx)
#为了防止出现bug,此处用了in的判断来去除空值,当然还有别的方法可以用,此处不讨论。
reviews_ints = [reviews_ints[i] for i in non_zero_idx]
labels = [labels[i] for i in non_zero_idx]
#选择每个句子长为200
seq_len = 200
from tensorflow.contrib.keras import preprocessing
features = np.zeros((len(reviews_ints),seq_len),dtype=int)
#将reviews_ints值逐行 赋值给features
features = preprocessing.sequence.pad_sequences(reviews_ints,200)
features.shape
输出:
(25000, 200)
4、Training, Test划分
0.2测试数据集,0.8训练集数据
from sklearn.model_selection import ShuffleSplit
ss = ShuffleSplit(n_splits=1,test_size=0.2,random_state=0)
for train_index,test_index in ss.split(np.array(reviews_ints)):
train_x = features[train_index]
train_y = labels[train_index]
test_x = features[test_index]
test_y = labels[test_index]
print("\t\t\tFeature Shapes:")
print("Train set: \t\t{}".format(train_x.shape),
"\nTrain_Y set: \t{}".format(train_y.shape),
"\nTest set: \t\t{}".format(test_x.shape))
5、Build the graph
开始创建模型图,第一步:定义超参数。
lstm_size: 隐藏层 LSTM cells节点的数量。一般来说越大越好:比如: 128, 256, 512。
lstm_layers: 隐藏层 LSTM 层的层数。从1开始,如果效果不好(underfitting)逐渐增加。
batch_size: 每次训练传入评论的数量。只要不内存溢出,一般来说越大越好。
learning_rate:0.001
lstm_size = 256
lstm_layers = 1
batch_size = 128
learning_rate = 0.001
n_words = len(vocab_to_int)
tf.reset_default_graph()
X = tf.placeholder(tf.int32,[None,200],name='inputs')
labels_ = tf.placeholder(tf.int32,[None,1],name='labels')
keep_prob = tf.placeholder(tf.float32,name='keep_prob')
Embedding
添加embedding 层。因为原始单词总量有72000个,直接one-hot编码后输入网络太不效率了,所以我们通过word2vec方法训练一个嵌入权重矩阵。
# 嵌入向量大小embedding vectors(既嵌入层节点数量)
embed_size = 300
embedding = tf.Variable(tf.random_uniform((n_words,embed_size),-1,1))
embed = tf.nn.embedding_lookup(embedding,X)
6、LSTM cell
下面,开始创建 LSTM cells 。 (TensorFlow documentation). 先定义 单元节点的类型( type of cells )。
创建基础的 LSTM cell , 可以使用 tf.contrib.rnn.BasicLSTMCell函数. 文档说明如下:
tf.contrib.rnn.BasicLSTMCell(num_units, forget_bias=1.0, input_size=None, state_is_tuple=True, activation=None)
函数中的参数:num_units(指该层单元节点的个数), 在我们的代码中用 lstm_size 来表示。例子如下:
lstm = tf.contrib.rnn.BasicLSTMCell(num_units)
下面,我们需要对cell添加dropout。使用函数:tf.contrib.rnn.DropoutWrapper。这等于是将单元(cell) 包裹在另一个单元(cell)中, 也等于在输入或者输出中添加了dropout。 代码如下:
drop = tf.contrib.rnn.DropoutWrapper(cell, output_keep_prob=keep_prob)
一般而言,隐藏层越多模型效果越好。隐藏层较多的话,会让网络学习到更多的复杂关系。 创建多个 LSTM 隐藏层,可以使用tf.contrib.rnn.MultiRNNCell:
cell = tf.contrib.rnn.MultiRNNCell([drop] * lstm_layers)
#创建基础的LSTM cell
lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size)
#对cell添加dropout
drop = tf.contrib.rnn.DropoutWrapper(lstm,output_keep_prob=keep_prob)
#堆栈多个LSTM layers
cell = tf.contrib.rnn.MultiRNNCell([drop]*lstm_layers)
## 将所有cell初始化为0状态。
initial_state = cell.zero_state(batch_size,tf.float32)
真正的运行 RNN 节点,需要使用函数 tf.nn.dynamic_rnn 。需要传入2个参数:多层LSTM单元(multiple layered LSTM cell),以及输入(inputs)。
outputs, final_state = tf.nn.dynamic_rnn(cell, inputs, initial_state=initial_state)
同时我们将上面定义的 initial_state传给了 RNN网络。这是在隐藏层之间传递的单元状态。 tf.nn.dynamic_rnn 函数帮我们完成了绝大多数工作。并返回每一步的输出和隐藏层最终状态。
outputs,final_state = tf.nn.dynamic_rnn(cell=cell,inputs=embed,initial_state=initial_state)
7、output
在这里我们只关心序列最后一个输出,我们据此来预测情感。
max_pool = tf.reduce_max(outputs,reduction_indices=[1])
predictions = tf.contrib.layers.fully_connected(max_pool, 1, activation_fn=tf.sigmoid)
with tf.name_scope('cost'):
cost = tf.losses.mean_squared_error(labels_, predictions)
tf.summary.scalar('cost',cost)
optimizer = tf.train.AdamOptimizer(learning_rate).minimize(cost)
8、Validation accuracy
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(tf.equal(tf.cast(tf.round(predictions), tf.int32), labels_), tf.float32))
tf.summary.scalar('accuracy',accuracy)
9、Batching
下面定义了一个函数,从数据集中获取batches。1、我们移除了最后一个batch,以便我们的batches是齐整的。 2、迭代 x 和 y 数组,以 [batch_size]为单位,返回上述数组的切片。
def get_batches(x, y, batch_size=100):
n_batches = len(x)//batch_size
x, y = x[:n_batches*batch_size], y[:n_batches*batch_size]
for ii in range(0, len(x), batch_size):
yield x[ii:ii+batch_size], y[ii:ii+batch_size]
merged = tf.summary.merge_all()
direc = 'C:\\Users\\1\\Desktop\\summary'
train_writer = tf.summary.FileWriter(direc+'\\train',graph)
test_writer = tf.summary.FileWriter(direc+'\\test',graph)
10、Training
epochs = 6
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
iteration = 1
for e in range(epochs):
for ii, (x, y) in enumerate(get_batches(train_x, train_y, batch_size), 1):
feed = {X: x,
labels_: y[:,None],
keep_prob:0.6}
loss, _, summary1 = sess.run([cost, optimizer, merged], feed_dict=feed)
if iteration%5==0:
train_writer.add_summary(summary1,iteration)
print("Epoch: {}/{}".format(e+1, epochs),
"Iteration: {}".format(iteration),
"Train loss: {:.3f}".format(loss))
if iteration%25==0:
val_acc = []
for x, y in get_batches(test_x, test_y, batch_size):
feed = {X: x,
labels_: y[:,None],
keep_prob:1.0}
batch_acc, summary2 = sess.run([accuracy, merged], feed_dict=feed)
val_acc.append(batch_acc)
test_writer.add_summary(summary2,iteration)
print("Val acc: {:.3f}".format(np.mean(val_acc)))
iteration +=1
saver.save(sess, "checkpoints/sentiment.ckpt")
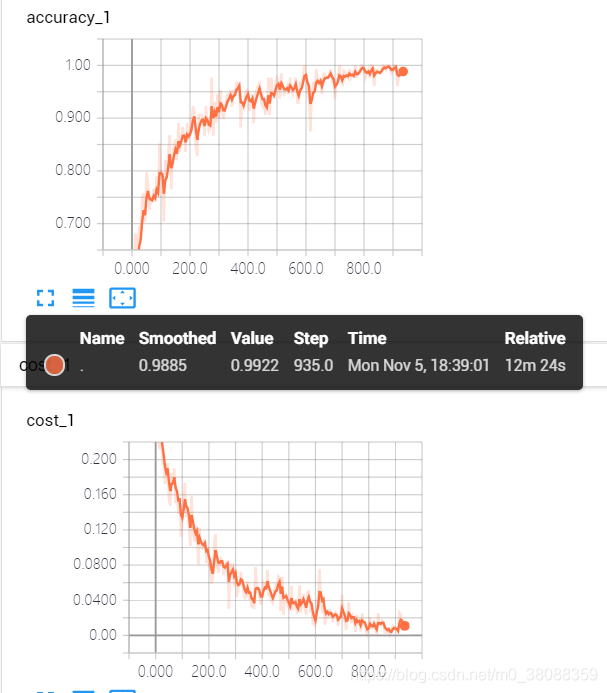
11、结果
输出就不输出了,直接上图参看。
测试集的结果:














 2459
2459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









