







8. 全卷积网络(FCN)
上一节介绍了,可以基于语义分割对图像中的每个像素进行类别预测。
全卷积网络(fully convolutional network,FCN)采用卷积神经网络实现了从图像像素到像素类别的变换。
与之前介绍的卷积神经网络有所不同,全卷积网络通过转置卷积(transposed convolution)层将中间层特征图的高和宽变换回输入图像的尺寸,从而令预测结果与输入图像在空间维(高和宽)上一一对应:
给定空间维上的位置,通道维的输出即该位置对应像素的类别预测。
import sys
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers, initializers, applications
from tqdm import tqdm
import d2lzh_tensorflow2 as d2lzh
sys.path.append("..")
8.1 转置卷积层
顾名思义,转置卷积层得名于矩阵的转置操作。
事实上,卷积运算还可以通过矩阵乘法来实现。
8.1.1 卷积运算
定义高和宽分别为4的输入X,以及高和宽分别为3的卷积核K。
打印二维卷积运算的输出以及卷积核。
X = np.arange(1, 17).reshape((1, 4, 4, 1))
X = tf.convert_to_tensor(X, dtype=tf.float32)
K = np.arange(1, 10).reshape((1, 3, 3, 1))
K = initializers.Constant(K)
conv = layers.Conv2D(filters=1, kernel_size=3, kernel_initializer=K)
conv(X), K.value
(<tf.Tensor: id=24, shape=(1, 2, 2, 1), dtype=float32, numpy=
array([[[[348.],
[393.]],
[[528.],
[573.]]]], dtype=float32)>,
array([[[[1],
[2],
[3]],
[[4],
[5],
[6]],
[[7],
[8],
[9]]]]))
由此可见,输出的高和宽分别为2。
8.1.2 矩阵乘法实现卷积运算
将卷积核K改写为含有大量零元素的稀疏矩阵W,即权重矩阵。
权重矩阵的形状为(4, 16),其中,非零元素来自卷积核K中的元素。
将输入X逐行连结,得到长度为16的向量。
然后将W与向量化的X做矩阵乘法,得到长度为4的向量。
对其变形后,可以得到与上文卷积运算相同的结果:
W, k = np.zeros((4, 16)), np.zeros(11)
k[:3], k[4:7], k[8:] = K.value[0, 0, :, 0], K.value[0, 1, :, 0], K.value[0, 2, :, 0]
W[0, 0:11], W[1, 1:12], W[2, 4:15], W[3, 5:16] = k, k, k, k
tf.matmul(tf.convert_to_tensor(W, dtype=tf.float32), tf.reshape(X, (-1, 1))), W
(<tf.Tensor: id=32, shape=(4, 1), dtype=float32, numpy=
array([[348.],
[393.],
[528.],
[573.]], dtype=float32)>,
array([[1., 2., 3., 0., 4., 5., 6., 0., 7., 8., 9., 0., 0., 0., 0., 0.],
[0., 1., 2., 3., 0., 4., 5., 6., 0., 7., 8., 9., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 2., 3., 0., 4., 5., 6., 0., 7., 8., 9., 0.],
[0., 0., 0., 0., 0., 1., 2., 3., 0., 4., 5., 6., 0., 7., 8., 9.]]))
由此可见,可以使用矩阵乘法实现卷积运算。
8.1.3 转置卷积层
从矩阵乘法的角度来描述卷积运算。
设输入向量为 x \boldsymbol{x} x,权重矩阵为 W \boldsymbol{W} W,卷积的前向计算函数的实现可以看作,将函数输入乘以权重矩阵,并输出向量 y = W x \boldsymbol{y} = \boldsymbol{W}\boldsymbol{x} y=Wx。
由于 ∇ x y = W ⊤ \nabla_{\boldsymbol{x}} \boldsymbol{y} = \boldsymbol{W}^\top ∇xy=W⊤,依据链式法则,卷积的反向传播函数的实现可以看作,将函数输入乘以转置后的权重矩阵 W ⊤ \boldsymbol{W}^\top W⊤。
而转置卷积层正好交换了卷积层的前向计算函数与反向传播函数:
转置卷积层的这两个函数可以看作将函数输入向量分别乘以
W
⊤
\boldsymbol{W}^\top
W⊤和
W
\boldsymbol{W}
W。
由此,转置卷积层可以用来交换卷积层输入和输出的形状。
设权重矩阵是形状为 4 × 16 4\times16 4×16的矩阵,对于长度为16的输入向量,卷积前向计算输出长度为4的向量。
假如输入向量的长度为4,转置权重矩阵的形状为 16 × 4 16\times4 16×4,那么转置卷积层将输出长度为16的向量。
在模型设计中,转置卷积层常用于将较小的特征图变换为更大的特征图。
在全卷积网络中,当输入是高和宽较小的特征图时,转置卷积层可以用来将高和宽放大到输入图像的尺寸。
具体示例如下:
构造一个卷积层conv,并设输入X的形状为(1, 64, 64, 3)。
卷积输出Y的通道数增加到10,但高和宽分别缩小了一半。
conv = layers.Conv2D(10, 4, padding='same', strides=2)
x = np.random.uniform(size=(1, 64, 64, 3))
x = tf.convert_to_tensor(x, dtype=tf.float32)
y = conv(x)
y.shape
TensorShape([1, 32, 32, 10])
通过创建Conv2DTranspose实例来构造转置卷积层conv_trans。
设conv_trans的卷积核形状、填充以及步幅与conv中的相同,并设输出通道数为3。
当输入为卷积层conv的输出Y时,转置卷积层输出与卷积层输入的高和宽相同:
转置卷积层将特征图的高和宽分别放大了2倍。
conv_trans = layers.Convolution2DTranspose(filters=3,
kernel_size=4,
padding='same',
strides=2)
conv_trans(y).shape
TensorShape([1, 64, 64, 3])
8.2 构造模型
全卷积网络模型的基本设计如下:
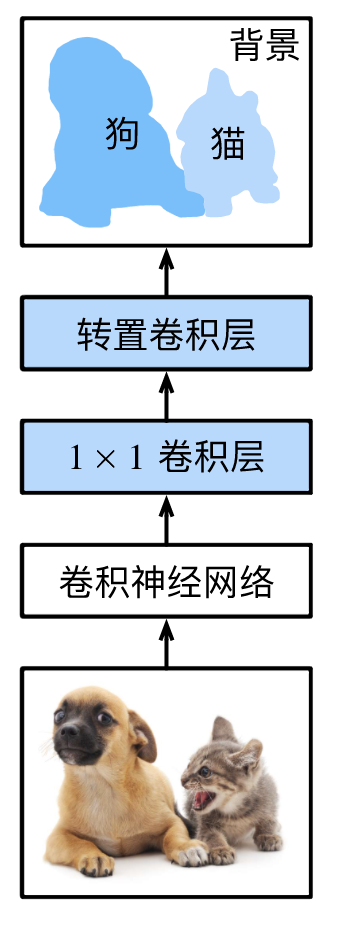
全卷积网络先使用卷积神经网络抽取图像特征,然后通过 1 × 1 1\times 1 1×1卷积层将通道数变换为类别个数,最后通过转置卷积层将特征图的高和宽变换为输入图像的尺寸。
模型输出与输入图像的高和宽相同,并在空间位置上一一对应:
最终输出的通道包含了该空间位置像素的类别预测。
具体示例如下:
使用一个基于ImageNet数据集预训练的ResNet-50模型来抽取图像特征,并将该网络实例记为pretrained_net。
pretrained_net = applications.ResNet50V2(include_top=False, weights='imagenet', input_shape=(320, 480, 3))
pretrained_net.layers[-4:], pretrained_net.output
Downloading data from https://github.com/keras-team/keras-applications/releases/download/resnet/resnet50v2_weights_tf_dim_ordering_tf_kernels_notop.h5
94674944/94668760 [==============================] - 33s 0us/step
([<tensorflow.python.keras.layers.convolutional.Conv2D at 0x147b7bb50>,
<tensorflow.python.keras.layers.merge.Add at 0x14722c590>,
<tensorflow.python.keras.layers.normalization.BatchNormalization at 0x13df96750>,
<tensorflow.python.keras.layers.core.Activation at 0x147bac650>],
<tf.Tensor 'post_relu/Identity:0' shape=(None, 10, 15, 2048) dtype=float32>)
创建全卷积网络实例net,复制pretrained_net实例的所有层以及预训练得到的模型参数。
net = keras.Sequential()
net.add(pretrained_net)
给定高和宽分别为320和480的输入,net的前向计算将输入的高和宽减小至原来的 1/32 ,即10和15。
x = np.random.uniform(size=(1, 320, 480, 3))
x = tf.convert_to_tensor(x, dtype=tf.float32)
net(x).shape
TensorShape([1, 10, 15, 2048])
通过 1 × 1 1\times 1 1×1卷积层将输出通道数变换为Pascal VOC2012数据集的类别个数21。
num_classes = 21
net.add(keras.layers.Conv2D(num_classes, kernel_size=1, activation='relu'))
print(net(x).shape)
(1, 10, 15, 21)
最后,需要将特征图的高和宽放大32倍,从而变回输入图像的高和宽。
结合 “填充和步幅” 一节中描述的卷积层输出形状的计算方法。
由于
(
320
−
64
+
16
×
2
+
32
)
/
32
=
10
(320-64+16\times2+32)/32=10
(320−64+16×2+32)/32=10,且
(
480
−
64
+
16
×
2
+
32
)
/
32
=
15
(480-64+16\times2+32)/32=15
(480−64+16×2+32)/32=15,
构造一个步幅为32的转置卷积层,并将卷积核的高和宽设为64、填充设为16。
由此可见,若步幅为 s s s、填充为 s / 2 s/2 s/2(假设 s / 2 s/2 s/2为整数)、卷积核的高和宽为 2 s 2s 2s,转置卷积核将输入的高和宽分别放大 s s s倍。
net.add(keras.layers.Conv2DTranspose(num_classes,
kernel_size=64,
padding='same',
strides=32))
print(net(x).shape)
(1, 320, 480, 21)
8.3 初始化转置卷积层
由上文可知,转置卷积层可以放大特征图。
在图像处理中,有时需要将图像放大,即上采样(upsample)。
上采样存在多种方法,常用的有双线性插值(bilinear interpolation):
简单来说,为了得到输出图像在坐标 ( x , y ) (x,y) (x,y)上的像素,先将该坐标映射到输入图像的坐标 ( x ′ , y ′ ) (x',y') (x′,y′)。例如,根据输入与输出的尺寸之比来映射。映射后的 x ′ x' x′和 y ′ y' y′通常是实数。
然后,在输入图像上找到与坐标 ( x ′ , y ′ ) (x',y') (x′,y′)最近的4个像素。
最后,依据输入图像上这4个像素及其与
(
x
′
,
y
′
)
(x',y')
(x′,y′)的相对距离来计算,输出图像在坐标
(
x
,
y
)
(x,y)
(x,y)上的像素。
详见:三十分钟理解:线性插值,双线性插值Bilinear Interpolation算法
双线性插值的上采样可以通过以下bilinear_kernel函数构造的卷积核的转置卷积层来实现:
# 不懂
def bilinear_kernel(in_channels, out_channels, kernel_size):
factor = (kernel_size + 1) // 2
if kernel_size % 2 == 1:
center = factor - 1
else:
center = factor - 0.5
og = np.ogrid[:kernel_size, :kernel_size]
filt = (1-abs(og[0]-center)/factor) * (1-abs(og[1]-center)/factor)
weight = np.zeros((kernel_size, kernel_size, in_channels, out_channels), dtype='float32')
weight[:, :, range(in_channels), range(out_channels)] = filt.reshape((kernel_size,kernel_size,1))
return weight
构造一个将输入的高和宽放大2倍的转置卷积层,并将其卷积核用bilinear_kernel函数初始化,从而用转置卷积层实现的双线性插值的上采样:
init_param = initializers.Constant(bilinear_kernel(3,3,4))
conv_trans = layers.Conv2DTranspose(3,
kernel_size=4,
padding='same',
strides=2,
kernel_initializer=init_param)
img_org = plt.imread("catdog.jpg")
img = tf.cast(img_org, tf.float32)/255.
print(img.shape)
# 增加维度
y = conv_trans(tf.expand_dims(img, axis=0))
print(y.shape)
(561, 728, 3)
(1, 1122, 1456, 3)
在全卷积网络中,将转置卷积层初始化为双线性插值的上采样:
net.add(keras.layers.Softmax(axis=-1))
net.layers
[<tensorflow.python.keras.engine.training.Model at 0x14872a690>,
<tensorflow.python.keras.layers.convolutional.Conv2D at 0x141413f50>,
<tensorflow.python.keras.layers.convolutional.Conv2DTranspose at 0x14609c590>,
<tensorflow.python.keras.layers.advanced_activations.Softmax at 0x145fc0650>]
bias_weight = net.layers[-2].get_weights()[1]
kernel_size = net.layers[-2].get_config()['kernel_size'][0]
print(bias_weight)
print(len(bias_weight))
print(kernel_size)
print()
# 初始化
net.layers[-2].set_weights([bilinear_kernel(num_classes, num_classes, kernel_size), bias_weight])
for i in range(4):
print(net.layers[i].trainable)
[0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]
21
64
True
True
True
True
8.4 读取数据集
用上一节 语义分割和数据集 中的方法读取数据集。(相关函数封装于d2lzh中)
其中,指定随机裁剪的输出图像的形状为
320
×
480
320\times 480
320×480(高和宽都可以被32整除)。
crop_size = (320, 480)
batch_size = 32
colormap2label = np.zeros(256 ** 3, dtype=np.uint8)
for i, colormap in enumerate(d2lzh.VOC_COLORMAP):
colormap2label[(colormap[0] * 256 + colormap[1]) * 256 + colormap[2]] = i
colormap2label = tf.convert_to_tensor(colormap2label)
voc_dir = "data/VOCdevkit/VOC2012"
voc_train = d2lzh.getVOCSegDataset(True, crop_size, voc_dir, colormap2label)
voc_test = d2lzh.getVOCSegDataset(False, crop_size, voc_dir, colormap2label)
batch_size = 16
voc_train = voc_train.shuffle(buffer_size=1024).batch(batch_size)
voc_test = voc_test.shuffle(buffer_size=1024).batch(batch_size)
1464it [00:09, 153.08it/s]
read 1114 valid examples
1449it [00:09, 152.89it/s]
read 1078 valid examples
8.5 训练模型
net.compile(optimizer=tf.keras.optimizers.Adam(lr=0.001),
loss=keras.losses.sparse_categorical_crossentropy,
metrics=['accuracy'])
net.output
<tf.Tensor 'softmax/Identity:0' shape=(None, 320, 480, 21) dtype=float32>
net.fit(voc_train, epochs=5, validation_data=voc_test)
Epoch 1/5
70/70 [==============================] - 34s 488ms/step - loss: 1.3283 - accuracy: 0.7081 - val_loss: 1.7960 - val_accuracy: 0.5843
Epoch 2/5
70/70 [==============================] - 31s 442ms/step - loss: 0.9921 - accuracy: 0.7498 - val_loss: 1.2259 - val_accuracy: 0.7266
Epoch 3/5
70/70 [==============================] - 31s 439ms/step - loss: 0.8433 - accuracy: 0.7720 - val_loss: 1.3299 - val_accuracy: 0.6618
Epoch 4/5
70/70 [==============================] - 31s 449ms/step - loss: 0.7305 - accuracy: 0.7877 - val_loss: 1.1581 - val_accuracy: 0.6906
Epoch 5/5
70/70 [==============================] - 31s 445ms/step - loss: 0.6499 - accuracy: 0.8084 - val_loss: 0.8737 - val_accuracy: 0.7657
8.6 预测像素类别
预测时,需要将输入图像在各个通道做标准化,并转成卷积神经网络所需的四维输入格式。
def predict(img):
feature = tf.cast(img, tf.float32)
feature = tf.divide(feature, 255.)
# (320, 480, 3) to (1, 320, 480, 3)
x = tf.expand_dims(feature, axis=0)
return net.predict(x)
将预测类别映射回它们在数据集中的标注颜色,以可视化每个像素的预测类别:
def label2image(pred):
colormap = np.array(d2lzh.VOC_COLORMAP, dtype='float32')
# 21 classes: max
x = colormap[tf.argmax(pred, axis=-1)]
return x
测试数据集中的图像大小和形状各异。由于模型使用了步幅为32的转置卷积层,当输入图像的高或宽无法被32整除时,转置卷积层输出的高或宽会与输入图像的尺寸有偏差。
为了解决这个问题,可以在图像中截取多块高和宽为32的整数倍的矩形区域,并分别对这些区域中的像素做前向计算。
这些区域的并集需要完整覆盖输入图像。当一个像素被多个区域所覆盖时,它在不同区域前向计算中转置卷积层输出的平均值可以作为softmax运算的输入,从而预测类别。
简单起见,这里只读取几张较大的测试图像,并从图像的左上角开始截取形状为 320×480 的区域:只有该区域用于预测。
对于输入图像,先打印截取的区域,再打印预测结果,最后打印标注的类别:
n = 10
imgs = []
test_images, test_labels = d2lzh.read_voc_images(root="../input/pascal-voc-2007-and-2012/VOCdevkit/VOC2012", is_train=False, max_num=n)
for i in range(n):
x = tf.image.resize_with_crop_or_pad(test_images[i], 320, 480)
pred = predict(x)
pred = label2image(pred)
pred = tf.cast(pred, tf.uint8)
# len(imgs)==30
imgs += [x, pred, tf.image.resize_with_crop_or_pad(test_labels[i], 320, 480)]
d2lzh.show_images(imgs[::3] + imgs[1::3] + imgs[2::3], num_rows=3, num_cols=n)
















 1482
1482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









