







1.Numpy的优势
学习目标
- 目标
- 了解Numpy运算速度上的优势
- 知道Numpy的数组内存块风格
- 知道Numpy的并行化运算
- 应用
- 无
一、为什么学习Numpy
在这里我们通过一段带运行来体会到Numpy的好处
import random
import time
import numpy as np
a = []
for i in range(100000000):
a.append(random.random())
t1 = time.time()
sum1=sum(a)
t2=time.time()
b=np.array(a)
t4=time.time()
sum3=np.sum(b)
t5=time.time()
print(t2-t1, t5-t4)
t2-t1为使用python自带的求和函数消耗的时间,t5-t4为使用numpy求和消耗的时间,结果为:

从中我们看到numpy的计算速度要快很多,节约了时间。
那么,机器学习的最大特点就是大量的数据运算,那么如果没有一个快速的解决方案,那可能现在python也在机器学习领域达不到好的效果。
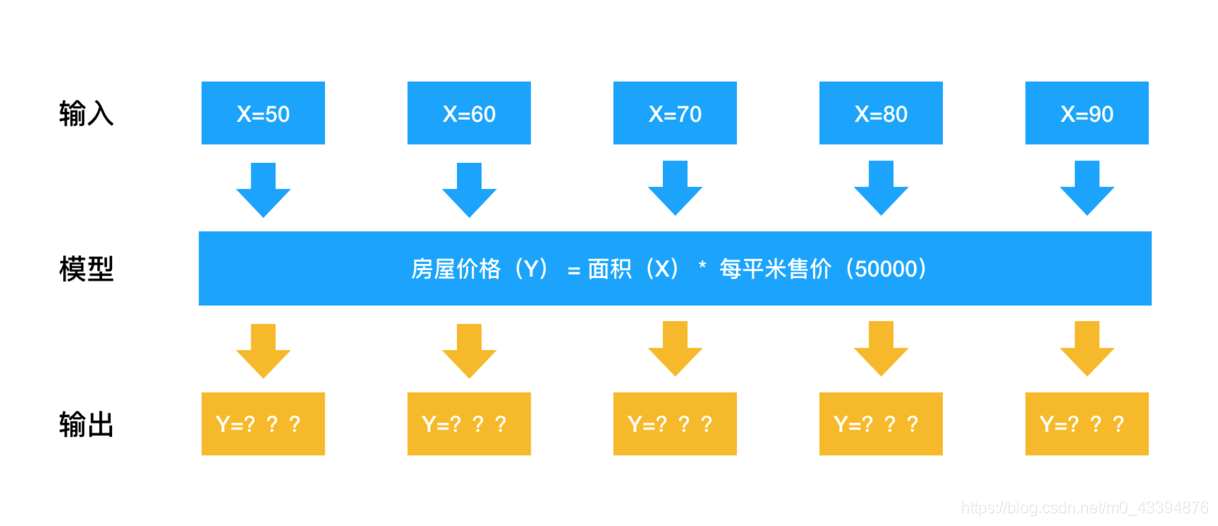
二、Numpy介绍

- 一个强大的N维数组对象
- 支持大量的数据运算
- 集成C / C++和Fortran代码的工具
- 众多机器学习框架的基础库(Scipy/Pandas/scikit-learn/Tensorflow)
三、Numpy的特点
最大的特点就是运行速度快。
为什么Numpy会快?
我们都知道Python作为一个动态语言一大特点就是慢,语言本身的特点我们可以抛开不说,**并且CPython还带有GIL锁,发挥不了多核的优势,但是我们前面学过那么多也没怎么体会到速度慢呢???**那是因为前面的django、flask或者scrapy这些框架,其实都是一些基于网络的操作(主要是IO操作)。这里给大家思考题了,为什么网络操作其实并不怎么会受到GIL的影响?快快快思考,如果不知道,我在这里给一张图,就不过多解释了,注意大小顺序按照开销排序

但是,如果是我们机器学习怎么办,充满大量的计算。没有解决这个问题,会消耗大量的时间运算,**如果还是使用原来的Python函数或者工具,那么估计在机器学习领域就没有Python什么事情了!**但是有的Numpy就好多了,接下来我们了解了解Numpy到底好在哪?
1、Numpy的数组内存块风格
在numpy当中一个核心就是ndarray(这个稍后会详细介绍),那么这个称之为数组的东西到底跟原本的python列表有什么不同呢,请看一张图:
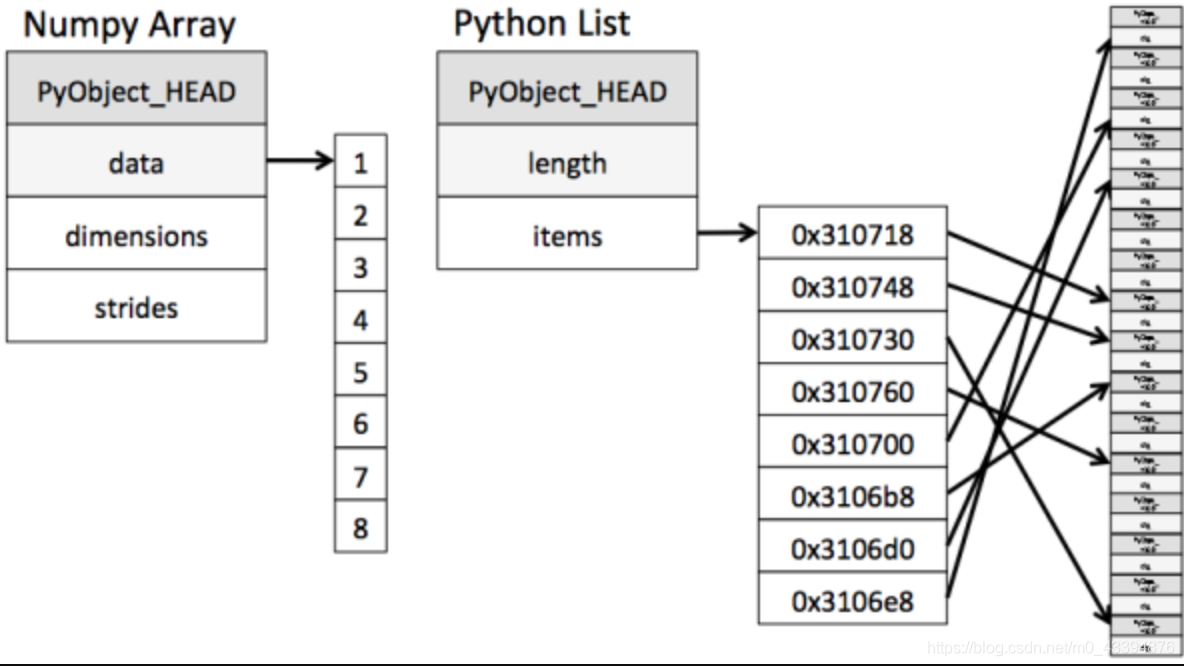
从图中我们看出来numpy其实在存储数据的时候,数据与数据的地址都是连续的,这样就给我们操作带来了好处,处理速度快。在计算机内存里是存储在一个连续空间上的,而对于这个连续空间,我们如果创建 Array 的方式不同,在这个连续空间上的排列顺序也有不同。
-
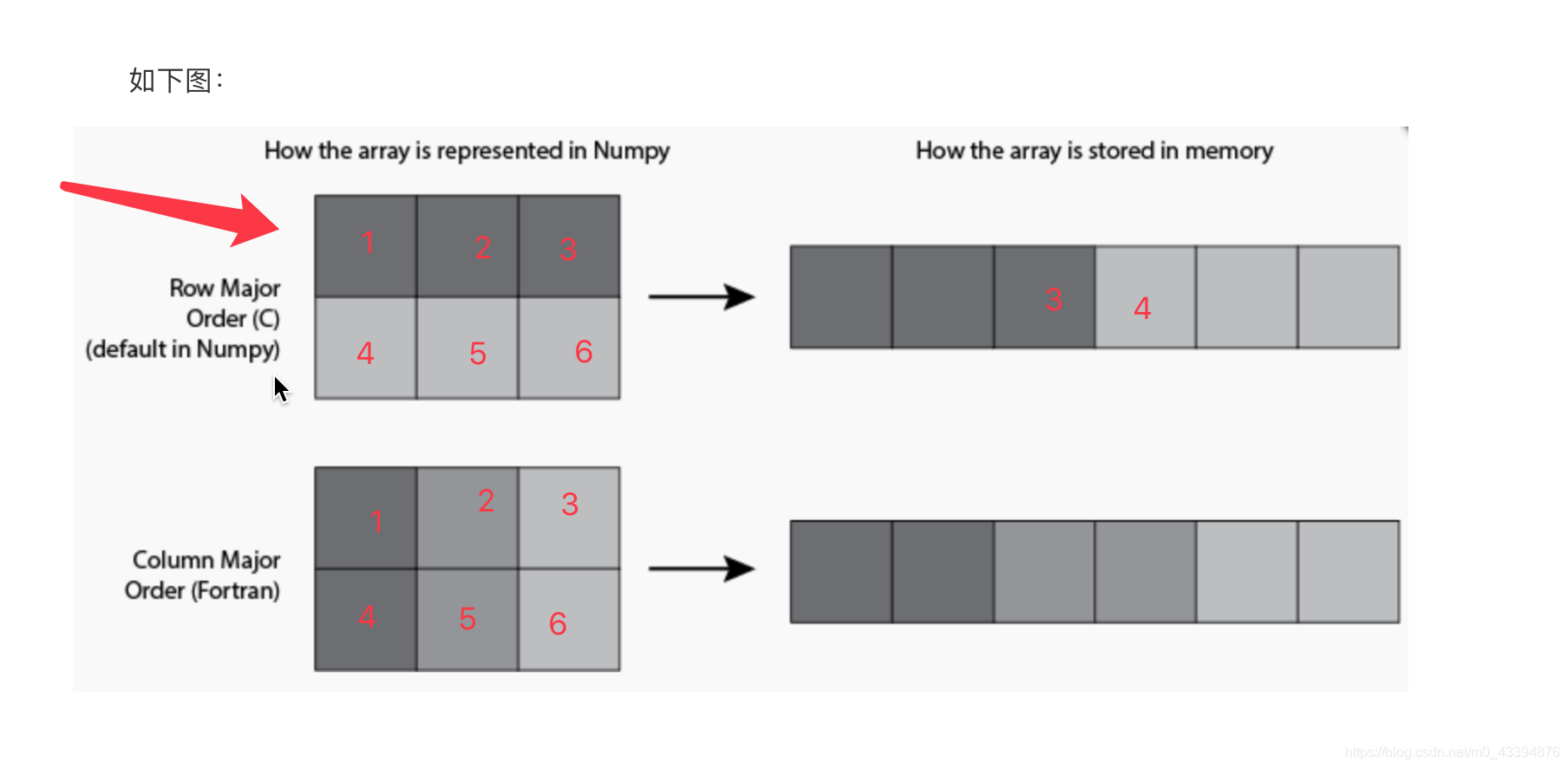
创建array的默认方式是 “C-type” 以 row 为主在内存中排列
-
如果是 “Fortran” 的方式创建的,就是以 column 为主在内存中排列
如下图:
2、Numpy的并行化运算
那么numpy的第二个特点就是,支持并行化运算,也叫向量化运算。当然向量是数学当中的概念,我们不过多解释,只需要知道他的优势即可。
numpy的许多函数不仅是用C实现了,还使用了BLAS(一般Windows下link到MKL的,下link到OpenBLAS)。基本上那些BLAS实现在每种操作上都进行了高度优化,例如使用AVX向量指令集,甚至能比你自己用C实现快上许多,更不要说和用Python实现的比。
也就是说numpy底层使用BLAS做向量,矩阵运算。比如我们刚才提到的房子面积到价格的运算,很容易使用multi-threading或者vectorization来加速。
2.Numpy属性
一、ndarray
NumPy provides an N-dimensional array type, the ndarray, which describes a collection of “items” of the same type.
NumPy提供了一个N维数组类型ndarray,它描述了相同类型的“items”的集合。
1、特点
- 每个item都占用相同大小的内存块(比如88,89占用内存大小一样)
- 每个item是由单独的数据类型对象指定的,除了基本类型(整数,浮点数 等)之外,数据类型对象还可以表示数据结构。
2、属性
数组属性反映了数组本身固有的信息。
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 几维数组(打印结果为几个元素就是几维) |
| ndarray.flags | 有关阵列内存布局的信息 |
| ndarray.ndim | 数组维数(维度,二维还是三维) |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组的大小(单位:字节) |
| ndarray.nbytes | 所有数组元素消耗的总字节数 |
首先创建一些数组,关于创建数组后详细介绍。
import numpy as np
a = np.array([1, 2, 3])
b = np.array([[1, 2, 3], [11, 22, 33]])
c = np.array([[[1, 2, 3], [11, 22, 33]], [[41, 52, 63], [71, 82, 93]]])
# 数组形状
print("数组形状")
print(a.shape)
print(b.shape)
print(c.shape)
# 阵列内存布局的信息
print("阵列内存布局的信息")
print(a.flags)
print("*" * 30)
print(b.flags)
print("*" * 30)
print(c.flags)
# 数组维数
print("数组维数")
print(a.ndim)
print(b.ndim)
print(c.ndim)
# 数组中的元素数量
print("数组中的元素数量")
print(a.size)
print(b.size)
print(c.size)
# 一个数组元素的长度(字节)
print("一个数组元素的长度(字节)")
print(a.itemsize)
print(b.itemsize)
print(c.itemsize)
# 数组元素消耗的总字节数
print("数组元素消耗的总字节数")
print(a.nbytes)
print(b.nbytes)
print(c.nbytes)
打印出属性的值:
数组形状
(3,) #一维数组,3个元素
(2, 3) #二维数组,6个元素
(2, 2, 3) #三维数组,12个元素
阵列内存布局的信息
C_CONTIGUOUS : True
F_CONTIGUOUS : True
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
******************************
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
******************************
C_CONTIGUOUS : True
F_CONTIGUOUS : False
OWNDATA : True
WRITEABLE : True
ALIGNED : True
WRITEBACKIFCOPY : False
UPDATEIFCOPY : False
数组维数
1
2
3
数组中的元素数量
3
6
12
一个数组元素的长度(字节)
4
4
4
数组元素消耗的总字节数
12
24
48
3、数组的形状
从刚才打印的形状看到numpy数组的形状表示,那个形状怎么理解。我们可以通过图示的方式表示:
零维数组:
就是数字: 比如1,2,3,4
一维数组:
就是一个数组: 比如:[1,2,3,4,5]
二维数组:
比如:[[1,2,3,4,5],[1,2,3,4,5]]
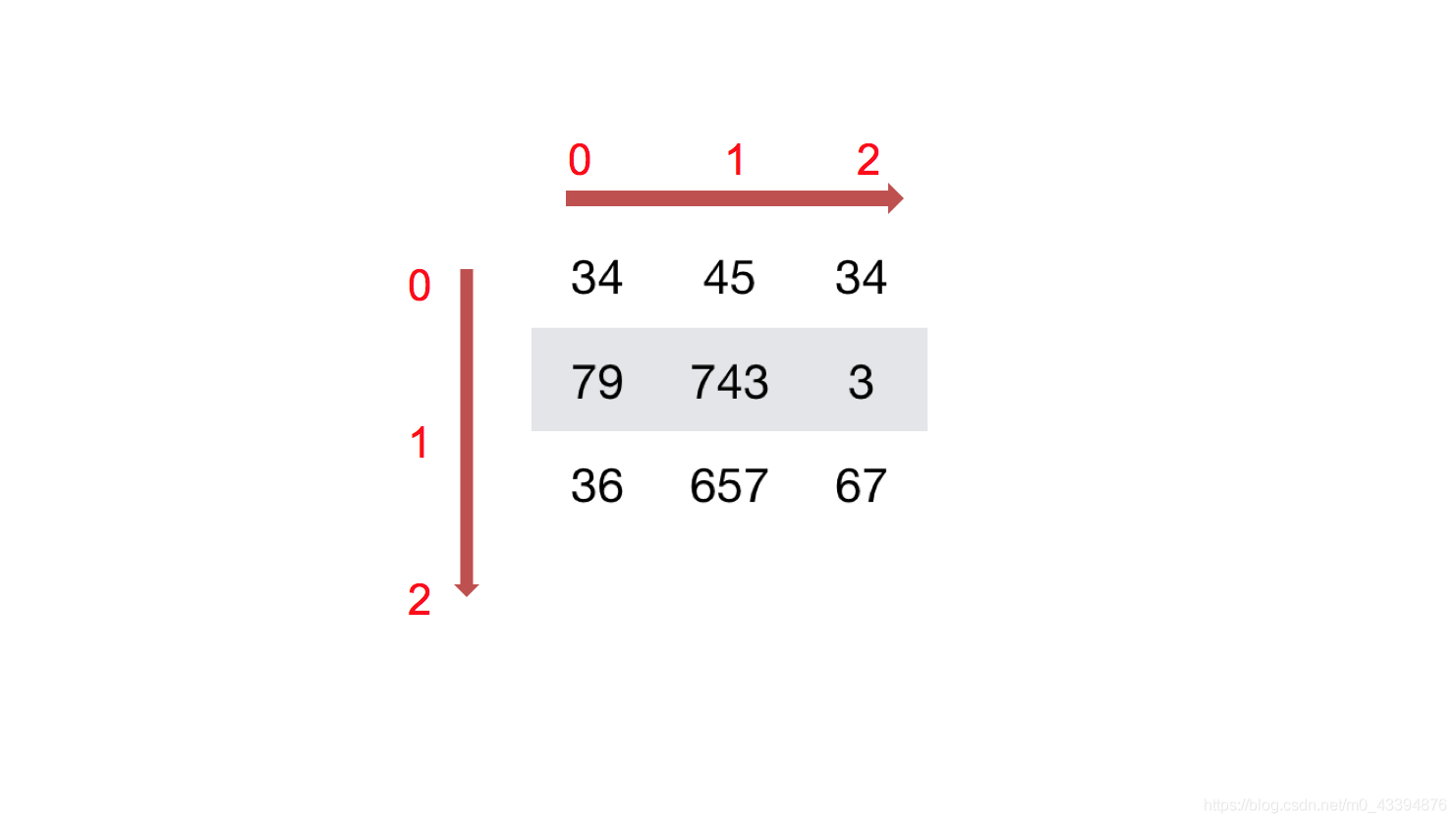
三维数组:
比如:[ [ [1,2,3,4,5],[1,2,3,4,5]],[[1,2,3,4,5],[1,2,3,4,5] ] ]
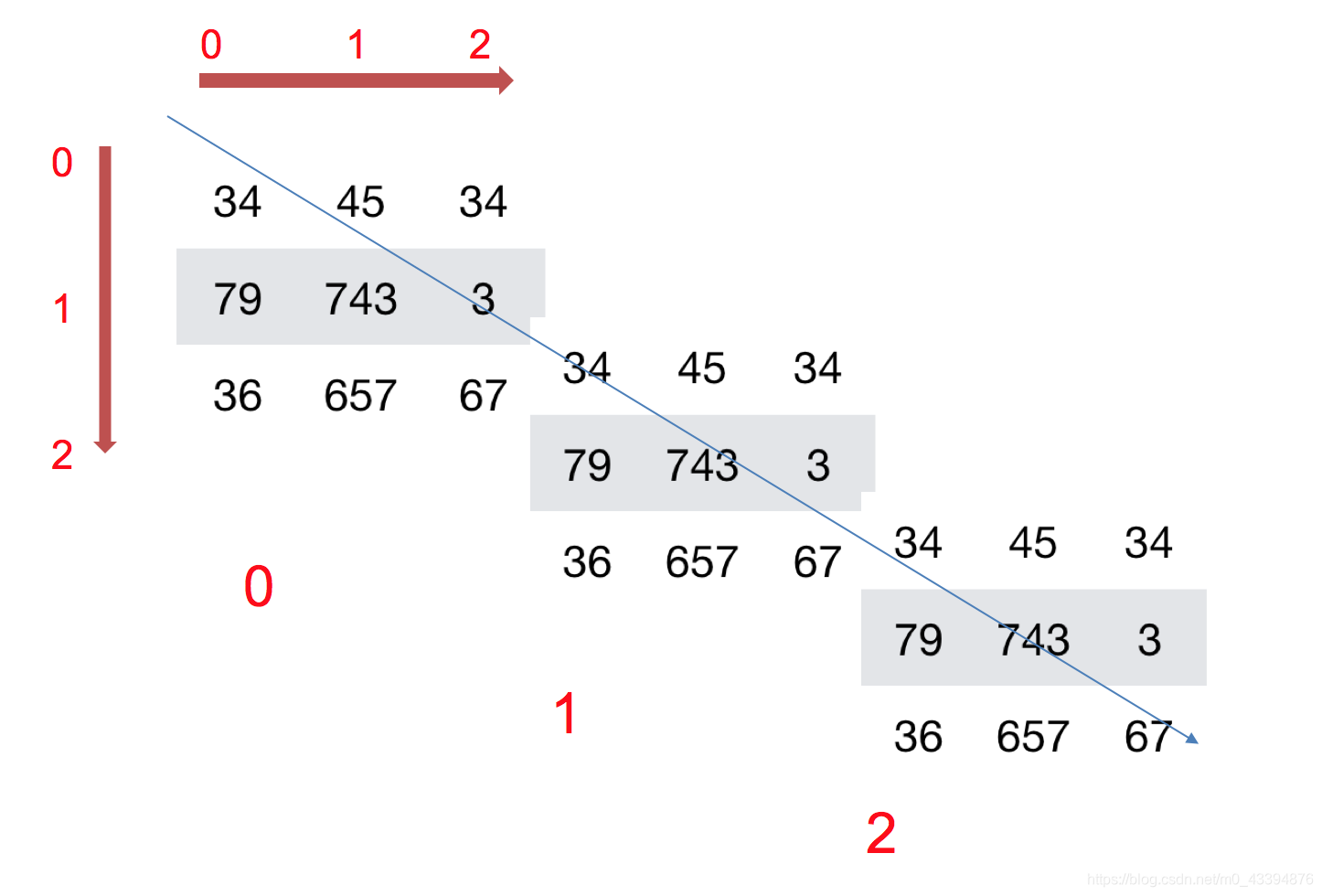
4、数组的类型
In [1]: import numpy as np
In [2]: x = np.array([[0, 1],
...: [2, 3]])
In [3]: x
Out[3]:
array([[0, 1],
[2, 3]])
In [4]: x.dtype
Out[4]: dtype('int32')
In [5]: type(x.dtype)
Out[5]: numpy.dtype
dtype是numpy.dtype类型,先看看对于数组来说都有哪些类型
| 名称 | 描述 | 简写 |
|---|---|---|
| np.bool | 用一个字节存储的布尔类型(True或False) | ‘b’ |
| np.int8 | 一个字节大小,-128 至 127 | ‘i’ |
| np.int16 | 整数,-32768 至 32767 | ‘i2’ |
| np.int32 | 整数,-2 ** 31 至 2 ** 32 -1 | ‘i4’ |
| np.int64 | 整数,-2 ** 63 至 2 ** 63 - 1 | ‘i8’ |
| np.uint8 | 无符号整数,0 至 255 | ‘u’ |
| np.uint16 | 无符号整数,0 至 65535 | ‘u2’ |
| np.uint32 | 无符号整数,0 至 2 ** 32 - 1 | ‘u4’ |
| np.uint64 | 无符号整数,0 至 2 ** 64 - 1 | ‘u8’ |
| np.float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | ‘f2’ |
| np.float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | ‘f4’ |
| np.float64 | 双精度浮点数:64位,正负号1位,指数11位,精度52位 | ‘f8’ |
| np.complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | ‘c8’ |
| np.complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | ‘c16’ |
| np.object_ | python对象 | ‘O’ |
| np.string_ | 字符串 | ‘S’ |
| np.unicode_ | unicode类型 | ‘U’ |
4.1创建数组的时候指定类型
In [1]: import numpy as np
In [2]: a = np.array([[1,2,3],[4,5,6]], dtype=np.float32)
In [3]: a.dtype
Out[3]: dtype('float32')
In [4]: arr = np.array(['python','tensorflow','scikit-learn','numpy'],dtype = np.string_)
In [5]: arr.dtype
Out[5]: dtype('S12')
4.2拓展-自定义数据结构
通常对于numpy数组来说,存储的都是同一类型的数据。但其实也可以通过np.dtype实现 数据类型对象表示数据结构。
假设我们现在要存储若干个学生的姓名和身高,那么需要自己定义数据结构实现
拓展内容:
In [1]: import numpy as np
In [2]: mytype = np.dtype([('name', np.string_, 10), ('height', np.float64)])
In [3]: mytype
Out[3]: dtype([('name', 'S10'), ('height', '<f8')])
In [4]: arr = np.array([('Sarah', (8.0)), ('John', (6.0))], dtype=mytype)
In [5]: arr
Out[5]:
array([(b'Sarah', 8.), (b'John', 6.)],
dtype=[('name', 'S10'), ('height', '<f8')])
In [6]: arr[0]['name']
Out[6]: b'Sarah'
对于存储复杂关系的数据,我们其实会选择Pandas更加方便的工具,后面我们详细介绍!
二、总结
知道数组的基本属性,不同形状的维度表示以及数组的类型














 1268
1268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









