







Fast-RCNN
RCNN存在的问题:
1、一张图像上有大量的重叠框,所以这些候选框送入神经网络时候,提取特征会有冗余!
2、训练的空间需求大。因为RCNN中,独立的分类器和回归器需要很多的特征作为训练。RCNN中提取候选框,提取特征和分类回归是分开的,可独立。
Fast-RCNN相对于RCNN的改进:
Fast-RCNN主要贡献在于对RCNN进行加速,快是我们一直追求的目标(更快、更准、更鲁棒),相比于RCNN,Fast-RCNN在以下方面得到改进:
1)借鉴SPP思路,提出简化版的ROI池化层(注意,没用金字塔),同时加入了候选框映射功能,使得网络能够反向传播,解决了SPP的整体网络训练问题;
2)多任务Loss层
A)SoftmaxLoss代替了SVM,证明了softmax比SVM更好的效果;
B)SmoothL1Loss取代Bouding box回归。
将分类和边框回归进行合并(又一个开创性的思路),通过多任务Loss层进一步整合深度网络,统一了训练过程,从而提高了算法准确度。
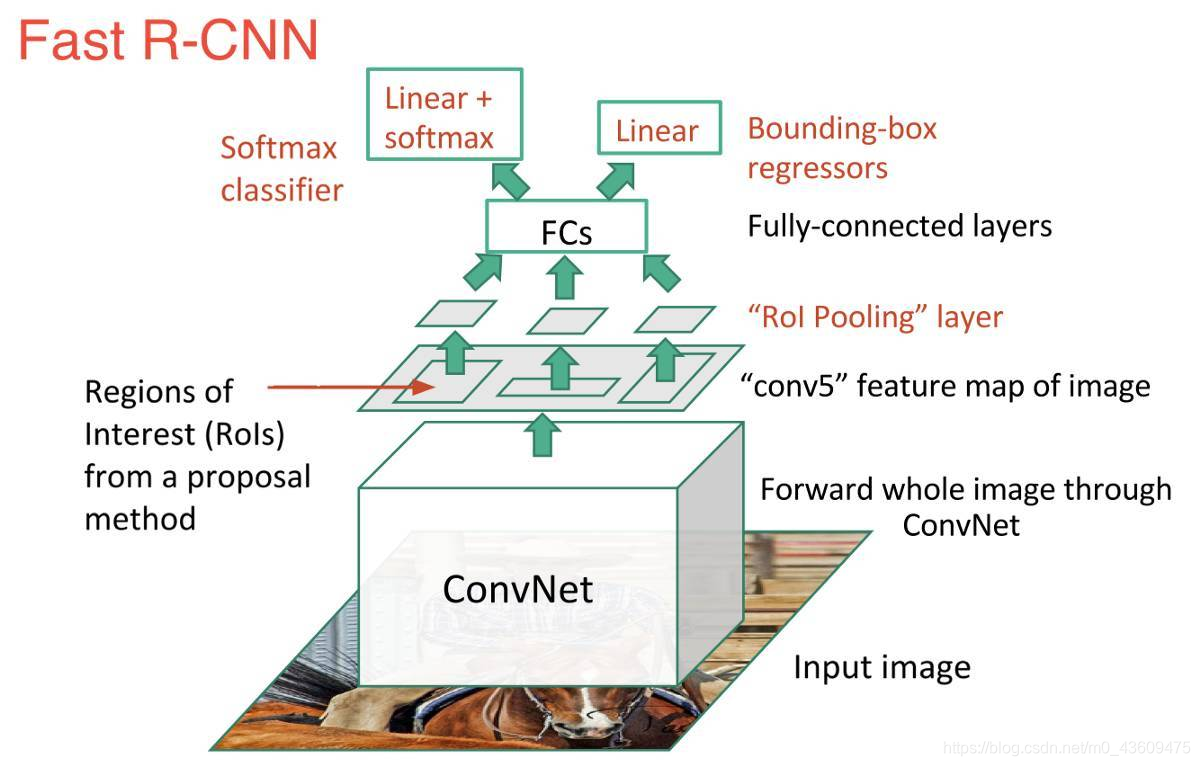
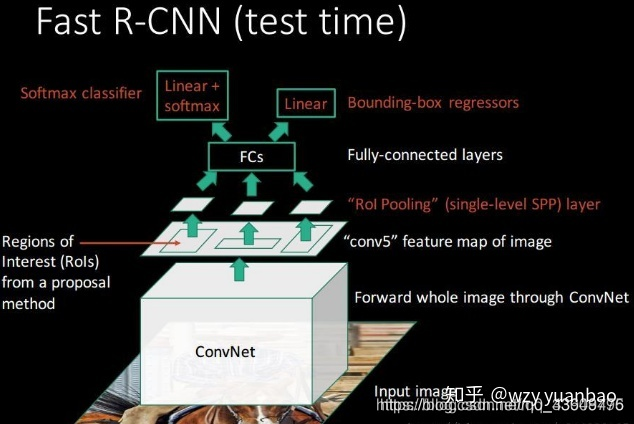
Fast-RCNN的检测流程
(1)首先输入一张自然图像,统一到固定大小,得到统一图;
(2)使用Selective Search,在统一图上提取大约2000个候选区域(proposal);
(3)将统一图输入到CNN中获取到特征图,记录统一图到特征图的映射(缩放倍数);
(4)将2000个候选区域(proposal)按照步骤(3)的映射关系分别映射到特征图上,获取到2000个特征图;
(5)使用ROI Pooling将特征图统一到固定大小,以便能过输入到全连接层。
(6)将2000个特征图的ROI Pooling结果输入到全连接层获取到2000个特征向量;
(7)使用softmax对提取的特征向量进行分类。
(8)使用根据特征向量对先验框进行坐标回归(使用回归器精细修正候选框位置)。
ROI Pooling 层的原理
在讲解ROI Pooling之前,先了解一下:SPP空间金字塔池化(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition) SPP的作用:不管输入的尺寸大小,输出都是固定的。
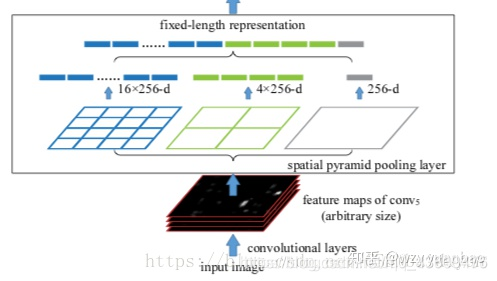 我们从上面网络结构图可以看出:最右边的不管输入是什么尺寸,每个特征图只输出一个值;中间的是不管输入什么尺寸,将特征图分为2*2个矩阵,每个矩阵取出一个值,一共有4个值;同理,最左边输出有16个值。所以不管输入特征图的大小,每一个特征图经过SPP以后都会产生16维的特征向量。
我们从上面网络结构图可以看出:最右边的不管输入是什么尺寸,每个特征图只输出一个值;中间的是不管输入什么尺寸,将特征图分为2*2个矩阵,每个矩阵取出一个值,一共有4个值;同理,最左边输出有16个值。所以不管输入特征图的大小,每一个特征图经过SPP以后都会产生16维的特征向量。
其中矩阵取值方式一般为取最大值或者平均值
类似于SPP, ROI Pooling的作用有两点:
1、把图片上Selective Search 选出的候选框映射到特征图上对应的位置,这个映射是根据输入图片缩小的尺寸来的;
2、将映射到特征图 上面的 ROI区域 (候选框区域)输出成统一大小的特征,因为这些框的特征区域大小不一样。
ROI pooling具体操作如下:
(1)根据输入image,将ROI映射到feature map对应位置;
(2)将映射后的区域划分为相同大小的sections(矩阵格子(划分 4x4、划分2x2、划分1x1 组成金字塔)这里未使用金字塔池化,而是只使用一个划分池化即只使用如(4x4) 而非(4x4、2x2、1x1))(sections数量与输出的维度相同);
(3)对每个sections进行max pooling操作; 这样我们就可以从不同大小的方框得到固定大小的相应的映射特征图。输出的映射特征图的大小不取决于ROI(先验框)和卷积feature maps大小,取决于人为设定大小。
(4)将ROI pooling得到的大小一致的映射特征图拉平后就可以输入到全连接层了
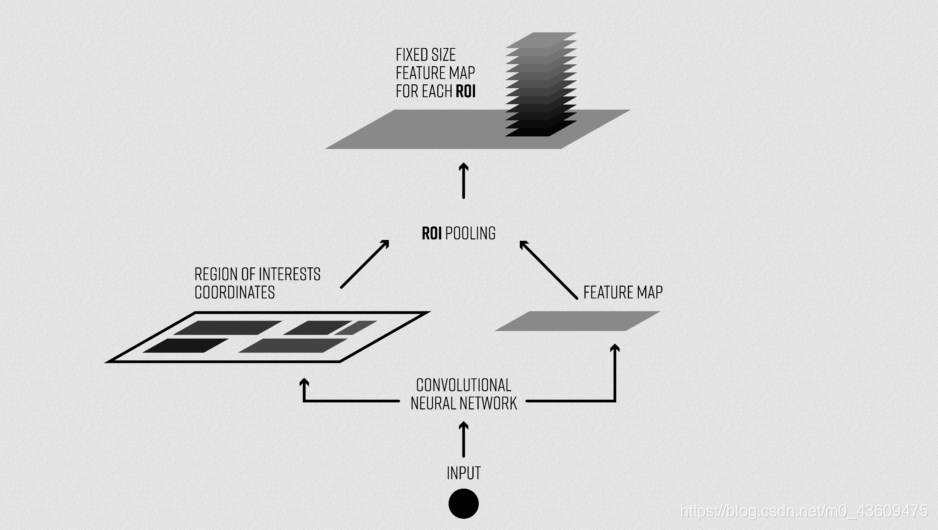
注释
ROI pooling层的输入是,ROI(先验框)的坐标(x,y,w,h)(中心宽高坐标)和某一层的特征图
ROI pooling目的是提取输出特征图上该先验框ROI 坐标所对应的特征。Selective Search 选出的先验框ROI 坐标是针对输入图像大小的,所以首先需要将先验框ROI 坐标缩小到输出特征对应的大小。
假设输出特征尺寸是输入图像的1/16,那么先将ROI坐标除以16并取整(第一次量化),然后将取整后的ROI划分成W×H(W和H是人为给定的)个块,因为划分过程得到的块的坐标是浮点值,所以这里还要将块的坐标也做一个量化,具体而言对于左上角坐标采用向下取整,对于右下角坐标采用向上取整,最后采用最大池化操作处理每个块,也就是用每个块中的最大值作为该块的值,每个块都通过这样的方式得到值,最终输出大小为 W×H的ROI(先验框) 特征。从这里的介绍可以看出ROI Pools 有两次量化操作,这两步量化操作会引入误差。
关于损失函数的计算
经过ROI Pooling后,每个先验框都会得到一个同样大小的feature,该feature被用来分类和坐标回归。分类和回归损失加在了一起,作为网络的总损失。
因为Fast RCNN将分类与回归做到了一个网络里面,因此损失函数必定是多任务的:
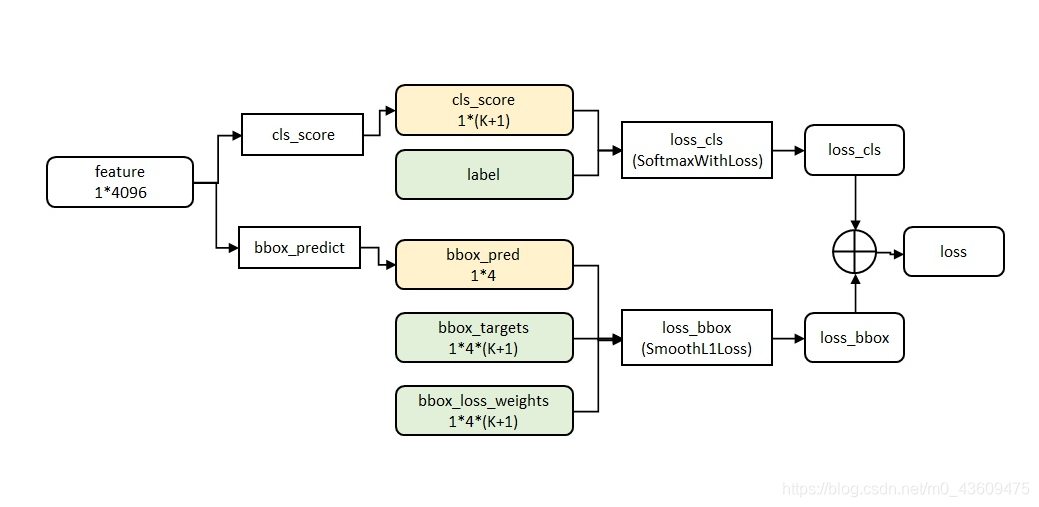
Fast RCNN的损失函数可以写为:
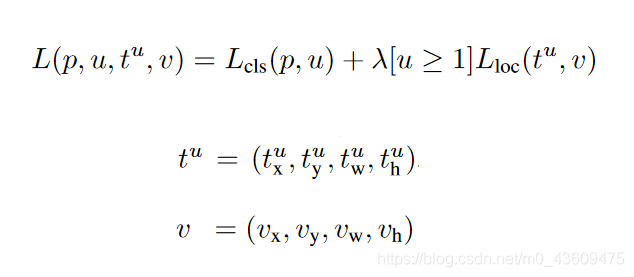
其中P是分类预测值,u是分类真实值(one-hot);tu是坐标回归值,就是上一篇笔记中的d’(Pi),v就是上一篇笔记中的d(Pi),具体可参考深度学习目标检测:RCNN;[u≥1]表示的是一个函数,叫做艾弗森指示函数,u≥1时[u≥1]=1否则[u≥1]=0。而u的取值是根据先验框是否是正负样本决定的,当先验框是正样本时 u=1.当先验框是负样本时u=0;
分类损失:
分类任务还是我们常用的对数损失,
对数损失, 即对数似然损失(Log-likelihood Loss), 也称逻辑斯谛回归损失(Logistic Loss)或交叉熵损失(cross-entropy Loss), 是在概率估计上定义的.它常用于(multi-nominal, 多项)逻辑斯谛回归和神经网络,以及一些期望极大算法的变体. 可用于评估分类器的概率输出.
对数损失通过惩罚错误的分类,实现对分类器的准确度(Accuracy)的量化. 最小化对数损失基本等价于最大化分类器的准确度.为了计算对数损失, 分类器必须提供对输入的所属的每个类别的概率值, 不只是最可能的类别. 对数损失函数的计算公式如下:
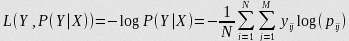
其中, Y 为输出变量, X为输入变量, L 为损失函数. N为输入样本量, M为可能的类别数, yij 是一个二值指标, 表示类别 j 是否是输入实例 xi 的真实类别. pij 为模型或分类器预测输入实例 xi 属于类别 j 的概率.
如果只有两类 {0, 1}, 则对数损失函数的公式简化为
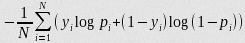
这时, yi 为输入实例 xi 的真实类别, pi 为预测输入实例 xi 属于类别 1 的概率. 对所有样本的对数损失表示对每个样本的对数损失的平均值, 对于完美的分类器, 对数损失为 0 .
**意义:**对数损失是用于最大似然估计的(以最大概率为标准来判断结果,即叫做极大似然估计)。一组参数在一堆数据下的似然值,等于每一条数据在这组参数下的条件概率之积。而损失函数一般是每条数据的损失之和,为了把积变为和,就取了对数。再加个负号是为了让最大似然值和最小损失对应起来。用来判断实际的输出与期望输出的接近程度,刻画除实际输出概率与期望输出概率的距离,即交叉熵越小,两个概率分布越接近。
回归损失
tu的定义方式与RCNN中一致,为中心区域坐标,以及区域宽度及高度。但是使用的损失函数不同,Fast RCNN使用的损失函数为鲁棒性更佳的L1损失函数,而不是RCNN中使用的L2损失函数,而且训练的过程也简单很多,需要注意的每个区域候选对于每个类都有区域回归训练。
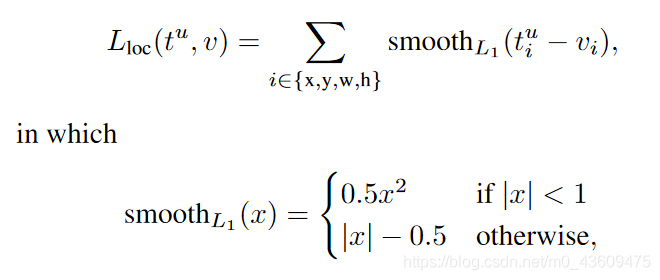
简单的介绍一下l1损失函数和l2损失函数,看这里:
L1是最小绝对值偏差,是鲁棒的,是因为它能处理数据中的异常值。如果需要考虑任一或全部的异常值,那么最小绝对值偏差是更好的选择。
L2范数将误差平方化(如果误差大于1,则误差会放大很多),模型的误差会比L1范数来得大,因此模型会对这个样本更加敏感,这就需要调整模型来最小化误差。如果这个样本是一个异常值,模型就需要调整以适应单个的异常值,这会牺牲许多其它正常的样本,因为这些正常样本的误差比这单个的异常值的误差小。
L2是平方差,L1是绝对差,如果有异常点,前者相当于放大了这种误差,而绝对差没有放大。
具体关于L1和L2可参考文章
最后关于正负样本的选择与使用
Mini-Batch的设置基本上与SPPNet是一致的,不同的在于128副图片中,仅来自于两幅图片。其中25%的样本为正样本,也就是IOU大于0.5的,其他样本为负样本,同样使用了困难负样本挖掘的方法,也就是负样本的IOU区间为[0.1,0.5],负样本的u=0,[u≥1]函数为艾弗森指示函数,意思是如果是背景的话我们就不进行区域回归了。在训练的时候,每个区域候选都有一个正确的标签以及正确的位置作为监督信息。
ROI Pooling的反向传播
不同于SPPNet,ROI Pooling是可以反向传播的,让我们考虑下正常的Pooling层是如何反向传播的,以Max Pooling为例,根据链式法则,对于最大位置的神经元偏导数为1,对于其他神经元偏导数为0。ROI Pooling 不用于常规Pooling,因为很多的区域建议的感受野可能是相同的或者是重叠的,因此在一个Batch_Size内,我们需要对于这些重叠的神经元偏导数进行求和,然后反向传播回去就好啦。
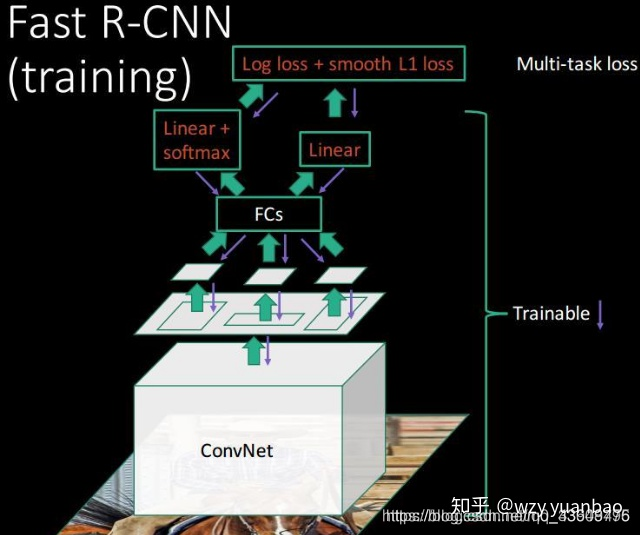
 现在的Fast RCNN模型已经接近完美了,识别检测全部放到了卷积神经网络的框架里面,速度也是相当的快。美中不足的是,区域建议网络还是Selective Search,网络其他部分都能在GPU中运行,而这部分需要在CPU中运行,有点拖后腿啊。接下来的Faster RCNN已经弥补了这个问题
现在的Fast RCNN模型已经接近完美了,识别检测全部放到了卷积神经网络的框架里面,速度也是相当的快。美中不足的是,区域建议网络还是Selective Search,网络其他部分都能在GPU中运行,而这部分需要在CPU中运行,有点拖后腿啊。接下来的Faster RCNN已经弥补了这个问题
参考文章
https://zhuanlan.zhihu.com/p/27582096
https://zhuanlan.zhihu.com/p/61611588














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









