







消息队列MQ基础篇一
一.MQ概念部分
1.什么是MQ
- MQ(Message Queue),字面意思上是个队列,支持先进先出,队列存放内容是message
- 一种跨进程的通信机制,用于上下游传递消息,使用后,消息发送上游只需要依赖MQ,不用依赖其他服务
2.为什么用MQ
-
用于流量消峰
产生问题:例如一个订单系统最多只能处理一万次订单,正常情况下满足需求绰绰有余,但如果碰上像购物节类似的高峰期,同时下单的数量就可能会超过一万次,造成系统宕机
解决问题:用MQ作为一个缓冲区,当订单请求发送过来时,首先经过MQ,再发送给系统处理。MQ会把请求message进行排队,先来先出队,给系统处理,防止了大量请求同时涌入系统 -
用于应用解耦
产生问题:例如电商应用的订单创建后,如果耦合多个子系统,就会出现如果其中任一个系统出现故障,都会造成下单操作失败,示意图如下:

解决问题:关系转变为基于消息队列的方式后,如果一个系统发生故障需要维修,那么,在修复的时间内,故障的系统要处理的内存会被缓存到消息队列中,用户下单操作可以正常完成。即通过MQ将订单系统与多个子系统的执行关系解耦了,而用MQ来接手处理故障信息,示意图如下:

-
用于异步处理
产生问题:例如A服务调用B服务,B服务执行完成时间太长,MQ之前提高效率的方法是A间隔一段时间再去调用B
解决问题:为了让A服务不去等待B服务而降低效率,可以增加MQ作为中间人,当B完成任务后,通知MQ,MQ再通知A,而完全不需要A来一直盯着B,示意图如下:

3.MQ的分类
-
ActiveMQ
优点:单机吞吐量万级,时效性ms级,可用性高,基于主从架构实现高可用性,不易丢失数据
缺点:官方对ActiveMQ5.x维护减少,高吞吐量场景较少使用 -
Kafka:主要应用于大数据
优点:吞吐量高,时效性ms级,可用性高,分布式的,主要支持简单的MQ功能
缺点:单机超过64个队列/分区,Load会发生明显飙高现象,实时性取决于轮询间隔时间,消费失败不支持重试,支持消息顺序 -
RocketMQ:阿里巴巴产品,java语言实现,参照kafka并改进
优点:单机吞吐量十万级,可用性非常高,分布式架构,消息0丢失,支持10亿级别消息堆积,可定制化
缺点:支持客户端应用不多,目前是java和c++ -
RabbitMQ:一个在AMQP(高级消息队列协议)基础上完成的,可复用的企业消息系统
优点:由于erlang语言的高并发特性,性能较好;吞吐量到万级,支持多种语言,社区活跃度高
缺点:学习成本高
4.MQ的选择
- kafka:适合产生大量数据的互联网服务的数据收集业务。大型公司建议选用,如果有日志采集功能,首选kafka
- RocketMQ:天生为金融互联网领域而生,对于电商订单交易高峰期等并发场景,建议选用
- RabbitMQ:性能好,时效性微秒级,社区活跃度高,如果数据量不太大,中小型公司优先选择
二.RabbitMQ
1.概念
- 定义:用于接收并转发消息的消息中间件
- 类比:可看作快递站,负责接收包裹,再由快递员取走包裹送到收件人手中。与快递站的区别在于,不处理快件而只是接收,存储和转发消息数
2.四大核心概念
-
生产者:产生数据,发送消息的程序
-
交换机(MQ组成部分):一方面接收来自生产者的消息,另一方面将信息推送到队列中,处理信息方法如下:
1.将信息推送到特定队列或多个队列
2.将信息丢弃 -
队列(MQ组成部分):尽管信息流经RabbitMQ和应用程序,但它们只能存储在队列中。使用方法:
1.许多生产者将信息发送到一个队列
2.许多消费者尝试从一个队列接收数据 -
消费者:大多时候是等待接收消息的程序。同一个应用程序既可以是生产者又可以是消费者
-
以上概念关系图如下:

图解:
1.交换机可以绑定n多个队列
2.队列与消费者的关系可以是一对一,也可以一对多,但如果是后者,根据之前把MQ当作快递站的类比,一个队列相当于一个包裹,上面就算写了多个消费者的名字,但最终也只能由一个消费者接收到
3.简单测试(基于java)

说明:根据此图逻辑可帮助理解以下消费者和生产者的代码逻辑
- 添加依赖
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>com.rabbitmq</groupId>
<artifactId>amqp-client</artifactId>
<version>5.8.0</version>
</dependency>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
</dependencies>
- 创建生产者
public class producer {
public static final String QUEUE_NAME = "hello";
/**
* @param args
* @throws ExecutionException
* @throws InterruptedException
* @throws IOException
* @throws TimeoutException
*/
public static void main(String[] args) throws ExecutionException, InterruptedException, IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.121.130");
factory.setUsername("admin");
factory.setPassword("123456");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
/**
* 1.队列名称
* 2.队列里的消息是否持久化,默认存储到内存中
* 3.该队列是否只供一个消费者进行消费
*/
channel.queueDeclare(QUEUE_NAMQ, false, false, false, null);
String message = "hello world";
/**
* 1.发送到哪个交换机
* 2.路由的key值,本次是队列名
* 3.其他参数
* 4.发送消息的消息体
*/
channel.basicPublish("", QUEUE_NAMQ, null, message.getBytes());
System.out.println("发送成功");
}
}
- 创建消费者
public class consumer {
public static final String QUEUE_NAME = "hello";
public static void main(String[] args) throws IOException, TimeoutException {
ConnectionFactory factory = new ConnectionFactory();
factory.setHost("192.168.121.130");
factory.setUsername("admin");
factory.setPassword("123456");
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
DeliverCallback deliverCallback = (var1, var2) ->{
System.out.println(new String(var2.getBody()));
};
CancelCallback cancelCallback = var ->{
System.out.println("消费消息被中断");
};
/**
* 1.消费哪个队列
* 2.消费成功之后是否要自动应答
* 3.消费者未成功消费的回调
* 4.消费者取消消费的回调
*/
channel.basicConsume(QUEUE_NAME, true, deliverCallback, cancelCallback);
}
}
- 注意点
1.先启动producer,再启动consumer,启动producer后,Rabbitmq管理平台上会显示发送的一个消息,此时如果关闭producer程序,消息还是会存储在rabbitmq上,即consumer此时还是能接收到消息
4.工作队列(Work Queues)
- 主要思想:避免立即执行资源密集型任务,而不得不等待它完成,相反我们安排任务在之后执行
- 方法:封装任务为消息并将其发送到队列,通过后台运行的工作进程弹出任务并最终执行
1.轮询分发机制

图解:当遇到消息大量同时发送时,将消息在队列中排好队,多个工作线程依次执行从队列中弹出的消息任务,一个消息只能被处理一次(一个线程不能连续接收两次消息),对于上图的意思就是通过轮询三个线程(顺序不定)的方式达到这种效果:
| consumer1 | consumer2 | producer |
|---|---|---|
| 接收a | 无接收 | 发送a |
| 无接收 | 接收b | 发送b |
| 接收a | 无接收 | 发送a |
| 无接收 | 接收b | 发送b |
2.消息应答机制
-
问题产生:消费者花费很长时间处理一个任务,中途突然挂了。而RabbitMq一旦向消费者发送一条消息后,就立即标记此消息为删除,则会丢失正在处理的消息,即同时没有了rabbitmq的消息和正在处理的消息。
-
概念:消费者在接收到消息并处理该消息之后,才告诉rabbitmq它已经处理了,这是rabbitmq才可以把该消息删除
-
分类
自动应答
1.概念:消息发送后立即被认为已经传送成功
2.难点:需要在高吞吐量和数据传输安全性方面做权衡
3.适用:消费者可以高效并以某种速率处理消息的情况
手动应答
1.方法:
channel.basicAck(用于肯定确认)
(Rabbitmq已经知道该消息并且成功的处理消息,可以丢弃了)
channel.basicNack(用于否定确认)
channel.basicReject(用于否定确认)
2.multiple解释(专属于手动应答)
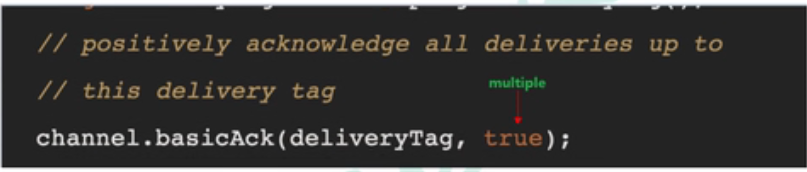
–》值为true时,代表批量应答channel上未应答的消息,示例如下:
从正常应答顺序上看,当前本来只有tag被确认收到消息应答,但由于开启了批量应答,这之后的5到7这些还未应答的消息都会被确认收到应答,即已在队列中的消息都会被确认应答

–》(推荐使用)值为false时,代表单个应答channel上未应答的消息,示例如下:好处是只应答当前处理完的消息,后面还未处理的消息不予以应答,减少消息丢失的可能

-
解决消息丢失问题:消息自动重新入队
步骤一:有两个消费者c1和c2分别处理消息1和消息2 步骤二:处理过程中,突然c1失去连接,queue立即知道c1失去连接,就不会确认消息1应答,即不会删除queue中的c1消息
步骤二:处理过程中,突然c1失去连接,queue立即知道c1失去连接,就不会确认消息1应答,即不会删除queue中的c1消息 步骤三:此时虽然c1失去连接了,但同时c2可以处理完它的消息后,再处理消息1
步骤三:此时虽然c1失去连接了,但同时c2可以处理完它的消息后,再处理消息1 步骤四:最终c2来替c1完成处理消息1的任务
步骤四:最终c2来替c1完成处理消息1的任务
-
简单测试
public class producer {
public static final String QUEUE_NAME = "hello";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMqUtils.getChannel();
channel.queueDeclare(QUEUE_NAME, false, false, false,null);
Scanner scanner = new Scanner(System.in);
while (scanner.hasNext()){
String next = scanner.next();
channel.basicPublish("",QUEUE_NAME,null,next.getBytes("UTF-8"));
System.out.println("生产者发出消息:" + next);
}
}
}
public class consumer1 {
public static final String QUEUE_NAME = "hello";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMqUtils.getChannel();
System.out.println("c1等待接收消息处理时间较短");
DeliverCallback deliverCallback = (var1,var2) ->{
SleepUtils.sleep(1);//通过自定义SleepUtils的sleep表示处理消息时间
System.out.println("接收到消息:" + new String(var2.getBody(), "UTF-8"));
/**
* 1.消息的标记 tag
* 2.是否批量应答false:不批量应答消息, true:批量应答
*/
channel.basicAck(var2.getEnvelope().getDeliveryTag(),false);
};
channel.basicConsume(QUEUE_NAME,false, deliverCallback, (consumerTag -> {
System.out.println(consumerTag + "消费者取消消费接口回调");
}));
}
}
public class consumer2 {
public static final String QUEUE_NAME = "hello";
public static void main(String[] args) throws IOException, TimeoutException {
Channel channel = RabbitMqUtils.getChannel();
System.out.println("c2等待接收消息处理时间较长");
DeliverCallback deliverCallback = (var1,var2)->{
SleepUtils.sleep(15);//通过自定义SleepUtils的sleep表示处理消息时间
System.out.println("接收到消息:" + new String(var2.getBody(), "UTF-8"));
channel.basicAck(var2.getEnvelope().getDeliveryTag(), false);
};
channel.basicConsume(QUEUE_NAME, false, deliverCallback, (valiable ->{
System.out.println(valiable + "消费者取消消息回调");
}));
}
}
3.Rabbitmq持久化
- 概念:为了保证rabbitmq崩溃或退出时,消息不会丢失,需要将队列和消息都标记为持久化
1.队列与消息持久化
- 实现队列持久化代码
boolean durable = true;
channel.queueDeclare(QUEUE_NAME, durable, false, false,null);
-
队列持久化注意点:如果之前已经存在的队列不是持久化的,就需要将它们先删除或重新创建一个持久化队列,不然会报如下错:
Caused by: com.rabbitmq.client.ShutdownSignalException: channel error; protocol method: #method<channel.close>(reply-code=406, reply-text=PRECONDITION_FAILED - inequivalent arg 'durable' for queue 'hello' in vhost '/': received 'true' but current is 'false', class-id=50, method-id=10)
即不能把原本存在的队列从非持久化的状态设置为持久化 -
删除队列指南:点击以下第一张图的队列名hello,进入第二张图界面,拉到页面底部便是第二张图,点击delete queue即可删除


-
持久化标识图:重新创建持久化后的hello队列,注意D是持久化标识

-
消息持久化:添加参数MessageProperties.PERSISTENT_TEXT_PLAIN,设置将消息保存到磁盘上
channel.basicPublish("",QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,next.getBytes("UTF-8"));
2.不公平分发
- 示例问题:消费者1处理任务很快,消费者2相对较慢,如果采用轮询分发,就会出现消费者2还在处理中,而消费者1已经处理完在等待消费者2,即开始处于空闲状态
- 概念:根据处理任务的效率决定处理任务的多少,即能者多劳
- 解决方法:设置参数channel.basicQos(1)(默认值为0),注意所有将要工作中的消费者都要设置这个参数
3.预取值
- 概念:定义通道上允许的未确认消息的最大数量,例如总共发送7条消息,由两个消费者c1和c2来处理,指定c1的预取值为2,指定c2的预取值为5,则c1就会处理2条消息,c2处理5条
注意: 只有出现通道上堆积消息的时候才能明显看出效果,因为如果消费者(预取值为2)处理速度太快,就会出现发完一条消息后,再发一条消息,此时消费者已经处理完第一条信息,则此时通道上其实还未达到预取值2,而是1,即会多处理一条消息 - 设置预取值:将不公平分发参数改为大于1的其他数值














 521
521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









