







百度热搜榜python爬虫,仅供学习交流
源码:
import requests
from bs4 import BeautifulSoup
response = requests.get("http://top.baidu.com/buzz?b=1")
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'lxml')
target = soup.find_all(attrs={"class": "keyword"})
for each in target:
text = each.find(attrs={"class": "list-title"}).text
print(text)
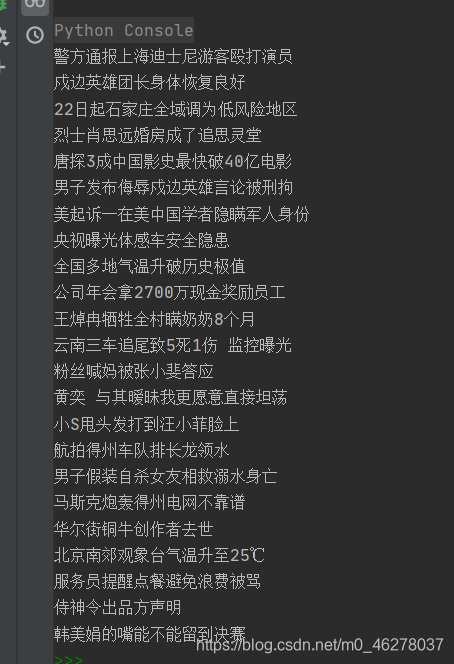
运行:
















 582
582











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











