






在这篇文章里,我将分享我实现这篇论文的方法。
- 问题描述
- 数据集
- 关于数据
- 使用的损失函数
- 准备检测数据
- 准备识别数据
- 训练检测模型和识别模型
- 代码整合
- 显示结果
- 引用
问题描述
我们需要从任何图像(包含文本)检测文本区域,这个图像可以是任何具有不同背景的东西。在检测到图像后,我们也必须识别它。
FOTS的完整形式是快速定向文本点亮。可以在任何自然场景中检测和识别任何文本。

在上面的图像中,FOTS给出了结果,它检测到“间隙”文本区域和图像(场景)中的所有文本区域,并识别出它是“间隙”、“50”和“GAP”等。这就是我们在这篇文章中要做的。
现在这个任务可以用两个不同的部分检测和识别来完成。在检测部分检测场景中的文本区域,在识别部分识别文本,什么是文本?(见上图)所以对于检测,我们使用CNN,对于识别,我们将在每个检测区域上使用一些序列解码器。
数据集
对于这个问题,我们将使用ICDAR 2015数据集。我们也将使用一个合成的文本图像数据集。
这里我们将使用ICDAR 2015数据集。其中有三种类型的数据。
训练集图像-
我们有1000个图像用于检测文本目的。
训练集定位和转录目标标注-
我们有1000个带有角坐标和标签(文本)的文本文件。假设在一个文本文件中,我们有5行,这意味着我们在相应的图像中有5个文本多边形。在每一行,我们有8个坐标(x1, y1, x2, y2…)和一个标签。
训练集文字图像,文本标注-
提供了与单词的轴向包围框相对应的~4468个切出的单词图像,并提供了单个文本文件,其中包含每个单词图像内包围形状的相对坐标。在一个单一的文本文件中提供的真实值。
同时也有测试图像来进行识别和检测。
但是对于训练识别模型,我使用了数据的增广,从合成的文本数据中提取了近15万幅文本图像。
在合成数据中,我们有文本图像,而在图像中写入的文本就是图像的名称,因此我们可以从图像的名称中提取图像名称。
损失函数
我们将使用在实际论文中建议的损失函数。对于score-map,我们将使用交叉熵损失。
在这一损失中,我们正在计算score-map中的预测概率与实际概率的差异
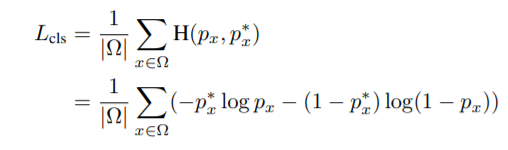
对于边框,我们使用IOU,对于旋转,我们使用λθ(1−cos(θx, θ∗x)旋转角损失。
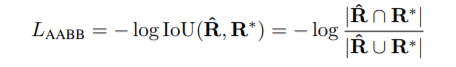
这里R_cap是预测的边界框,R*是实际的边界框,所以这里log中的分子项是预测和实际之间的交叉区域,而标记项是这两个区域的并集。现在我们用这个来求截面积
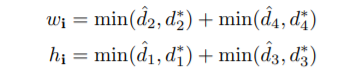
其中d1、d2、d3、d4为一个像素到上、右、下、左边界的距离。这里w_i和h_i是截面积的宽度和高度,现在我们可以通过两者相乘得到截面积。
现在联合区域将是- area_real+area_pred-intersected_area
对于角度,我们用-
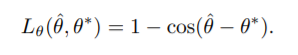
其中,ta_cap是预测的角度,而ta_*是实际的角度。
现在合并这两个损失的最后损失的方位是-
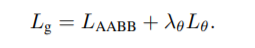
现在检测的全部损失是-
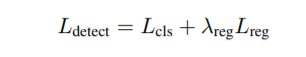
这里的L_reg和L_g是一样的。
对于识别部分,使用的损失是CTC loss-
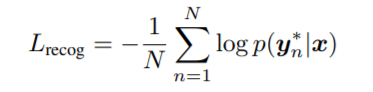
准备检测数据
我们必须转换数据以便我们可以将其输入我们的模型并对输出计算损失。对于输入,我们只会在一次输入一批图像和输出score-map(代表文本在哪里,不是0和1)和geo-map(这有5通道与图片相同的高度和宽度,前四个分别是 上下左右,最后一个是角度)。基于这两个输出,我们的模型通过损失计算和优化将会收敛,我们也将返回一个训练掩码,以便在计算损失时,我们将不考虑那些非常小的文本区域,标签文本没有给出。
对于每个图像,输入的形状是(512,512,3),输出的形状是(512,512,6),这里有6个通道,一个是score map,四个是top, right, bottom, and left的距离,还有一个是training mask。
如果我们的批大小是32,那么输入形状将是(32,512,512,3),输出形状将是(32,512,512,6)。
现在来看geo-map的样子,因为我们知道它的通道与一个真正的文本矩形只有像素的距离,这个矩形的文本有上方、右侧、底部和左侧。你可以看这个图像更清楚-
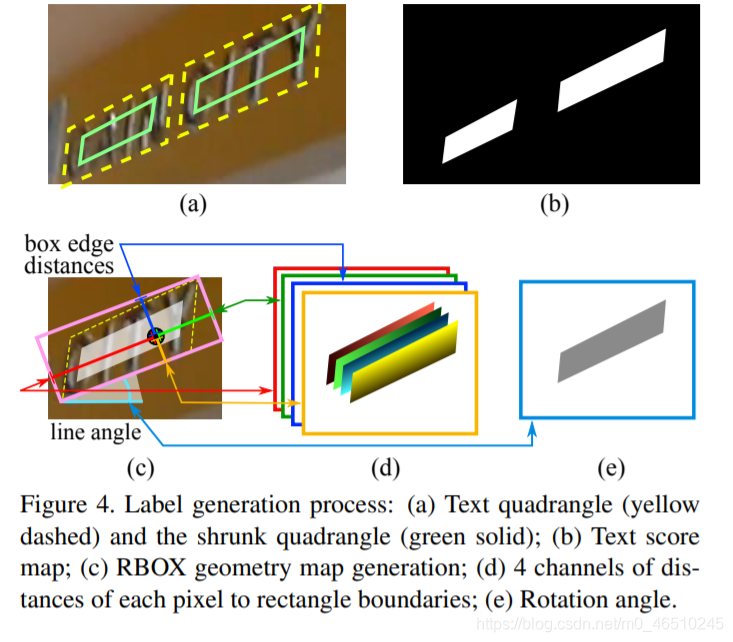
我也根据论文画了图,看起来像这样


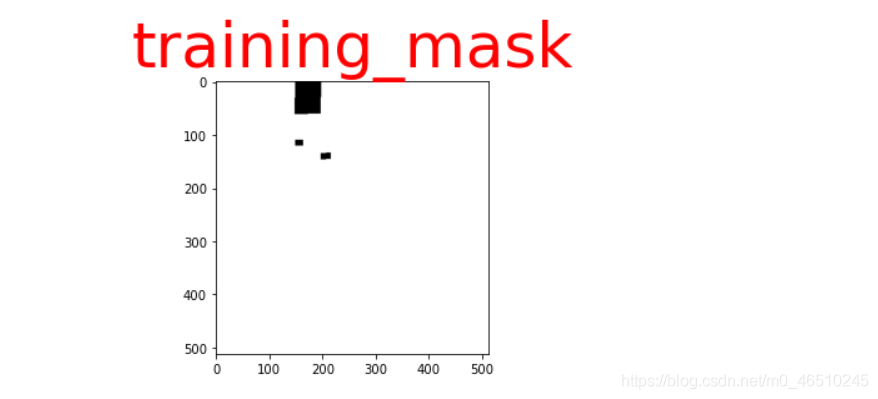
准备识别数据
对于识别任务,我们必须提供文本图像作为输入,以及编码的文本序列(在该图像中)。在给出图像作为输入之前,我们将调整所有图像的高度和宽度。在我的例子中,我将所有图像的大小调整为(15,64,3)。我对所有与图像对应的文本进行了编码,并在Keras预处理库的帮助下依次进行了转换。因此,在编码之后,我们的输出将是(1,15)的形状,这15从哪里来,我将所有编码的文本填充为15个长度。
如果批大小为32,则输入形状为(32,15,64,3),输出形状为(32,1,15)。
训练检测与识别模型
检测模型-
第一篇研究论文是https://arxiv.org/pdf/1801.01671.pdf,它解释了整个工作。在本文“FOTS”中,他们同时进行了检测和识别,这是端到端系统,意思是如果我们给出一个有文本的场景,那么它将返回检测到的文本区域,并对文本进行识别。首先,他们提取特征图,用一些CNN检测文本区域,然后,他们在检测区域的序列解码的帮助下进行识别部分。
首先,他们从图像中提取特征的帮助下共享层的卷积,然后这些特征在文本检测分支(这又是一堆褶积层)然后文本检测分支预测b框(边界框)和边界框的方向,本预测输出和ROI旋转使面向文本区域固定高度和长宽比不变,然后这个转到文本识别分支(也就是RNN)和CTC解码器,它给出预测的文本。
但我已经实现了两部分,首先我有一个训练过检测模型,然后我有一个训练过的识别模型。因为我们有这两个任务的数据。
所以我们的检测部分是受East 论文的启发,https://arxiv.org/abs/1704.03155。本文介绍了一种从不同背景的场景中检测文本的方法。该网络使用的架构由卷积层、池化层和规范化层组成。
这个网络的灵感来自于u形网络,正如你所看到的,从特征提取器的中层,我们将信息提取到特征合并分支。
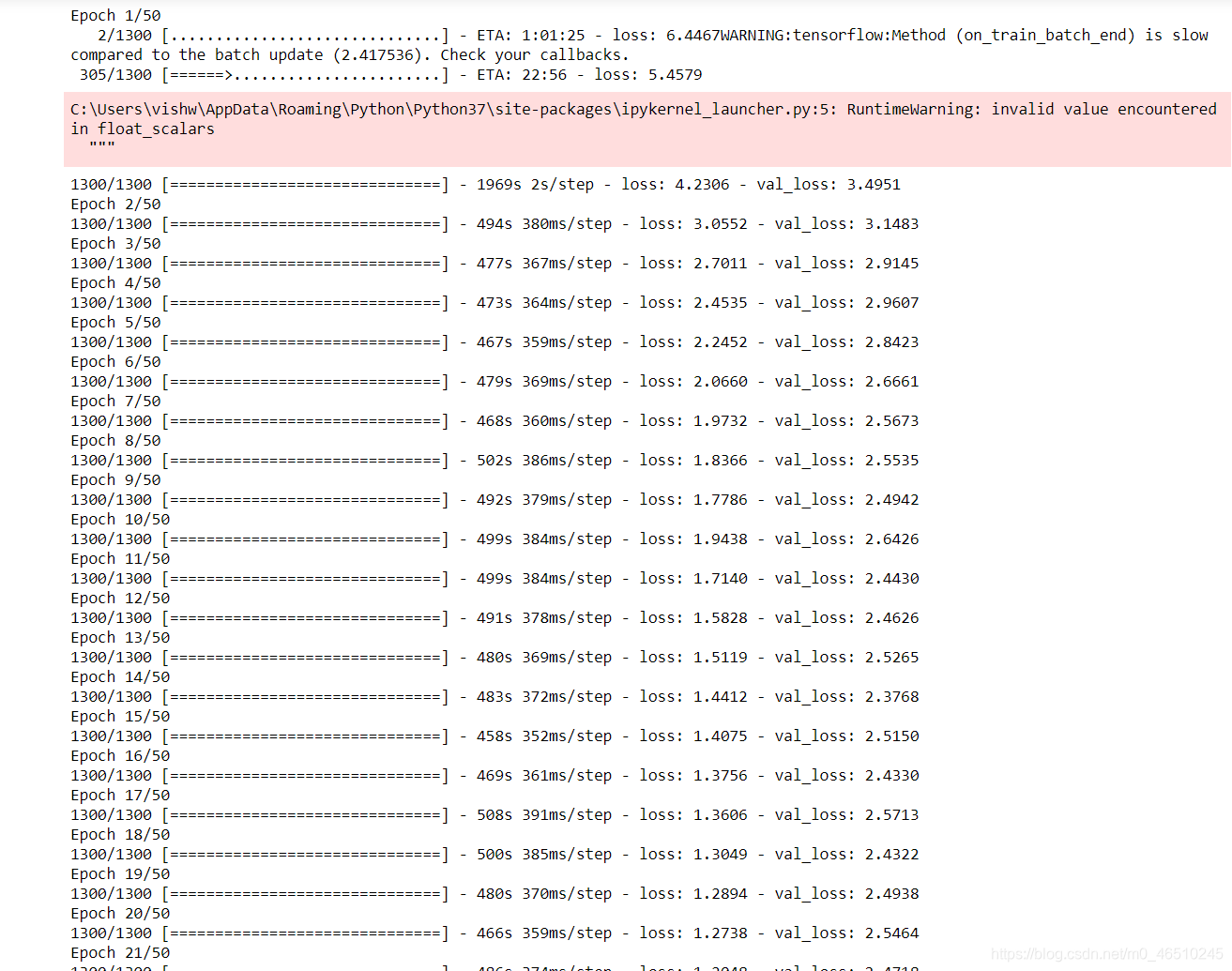
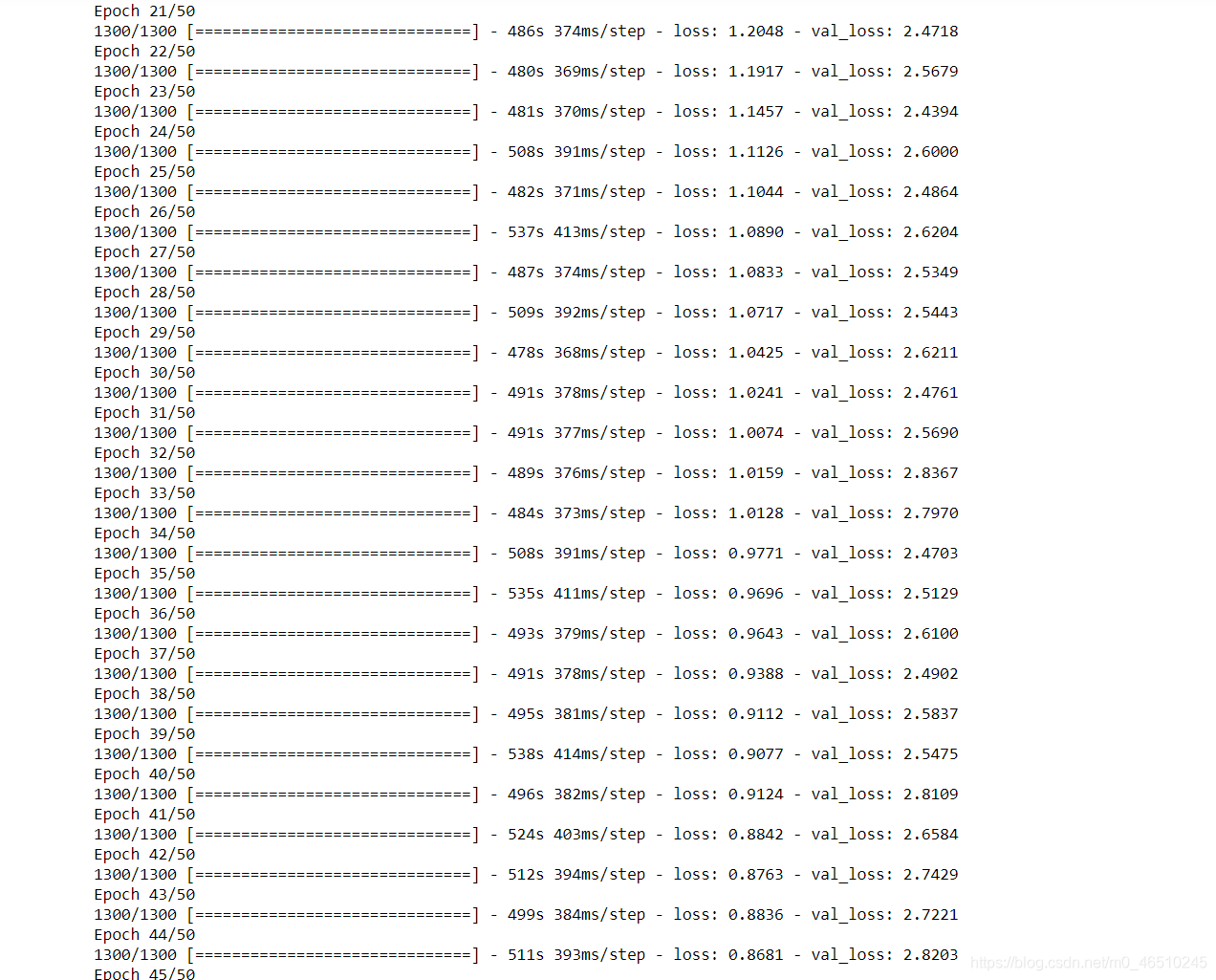
这里我们使用了预先训练的resnet50模型,该模型在imagenet数据集上进行了训练,用于提取特征并将其用于特征合并分支。你可以看到前50个训练时代的检测模型-

识别模型
对于识别模型,我们使用了一些初始的Conv层、批处理归一化层和max-pooling层从图像中提取信息,之后我们必须使用一个双向LSTM层。
对于如何构建数据的识别模型,我已经在上面的准备数据一节中解释过了。
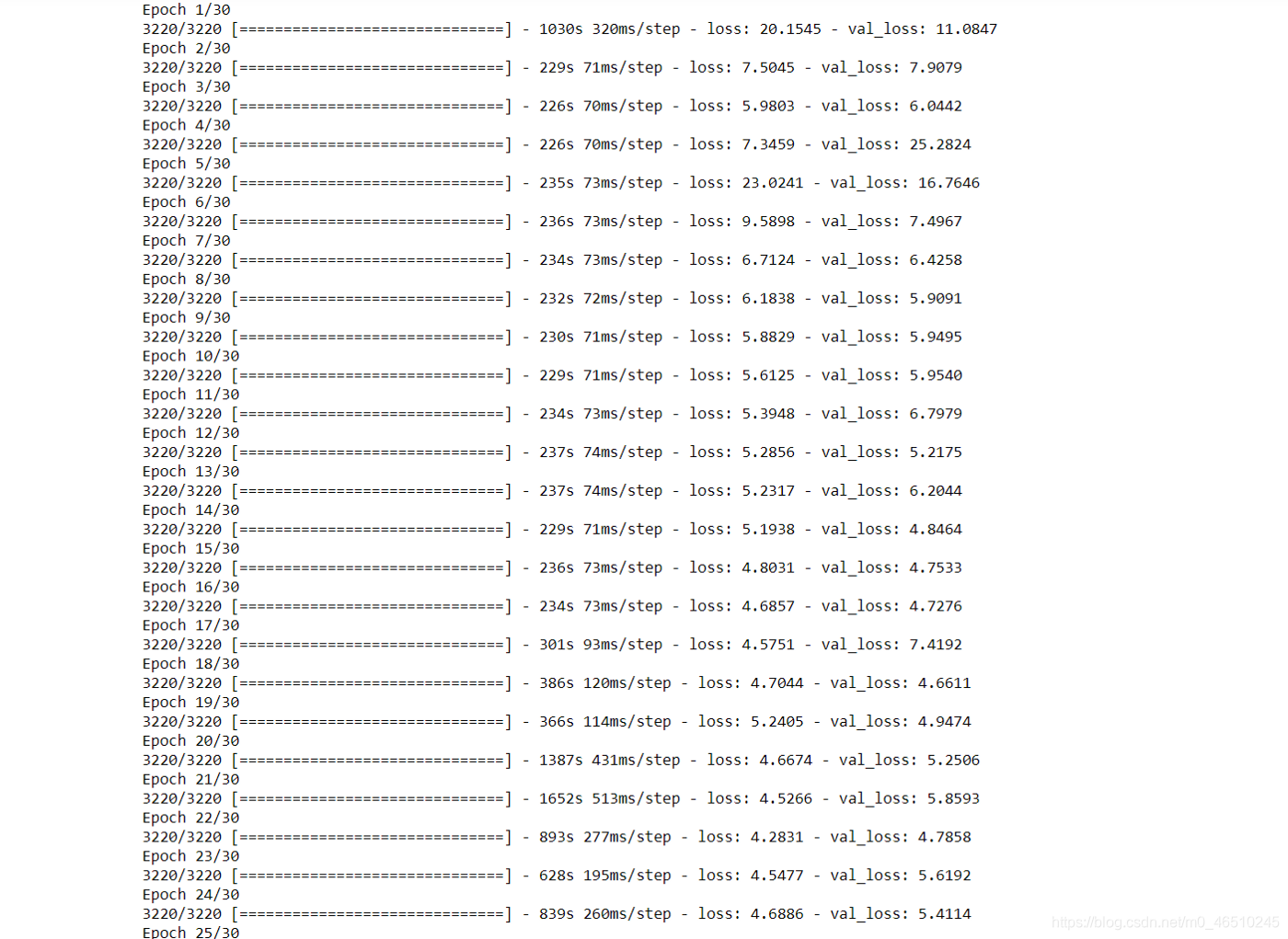
你可以在这里看到识别模型的训练时代

训练代码整合
现在我们需要创建一个管道或者说是python函数,它可以获取图像并返回带有高亮文本区域和文本的图像。
为了编写这个函数,我们将使用NMS(Non-Max suppression)技术和一个ROI-ROTATE方法。问题是什么是NMS, NMS是一种选择与文本区域相交较高的边框的技术。在预测之后我们将得到shape的输出(512,512,6)。geo-map,score-map和angle的帮助下,我们将首先制作很多边界框要。假设图像中已有文本,现在将该图像提供给检测模型,我们将获得6个通道的结果图,现在我们将只提取所有6个通道中的像素,这些像素在预测得分图中的值为1,这样我们就拥有了文本区域像素的位置及其与像素顶部,右侧,底部和左侧的预测距离矩形。每个像素都有它自己的边界框(我们知道区域的面积,像素和距离两边的像素),所以最后得分图和距离的帮助下,我们将得到一个为每个像素边界框。此后,NMS的工作就开始了,NMS选择其中包含大部分文本的最佳边界框。然后,我们用ROI旋转技术旋转这些边界框中的区域。现在我们在边界框的帮助下裁剪文本图像,并将其发送到识别模型,识别模型给出文本输出。现在我们将在TensorFlow ctc_decoder方法的帮助下解码这个输出。在这之后,我们可以很容易地得到我们的文本。
显示结果
我已将此图片提供给我的管道

得到如下结果:
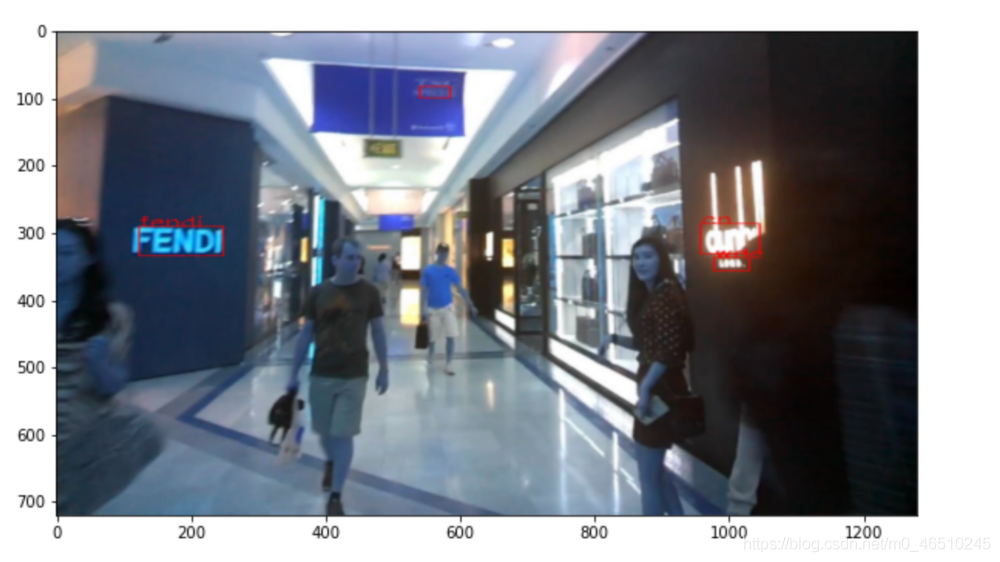
正如我们在此处看到的那样,它正在检测“ fendi”和更多的单词,并且可以正确识别“ fendi”单词。
现在我们可以看到更多示例

我们可以在上图中看到该模型的检测和识别能力还是可以的
但是,有些图像在模型上表现不佳,例如,如果图像中的单词很大或单词的角度一定,则无法正确检测到它们,也无法正确识别它们。 查看一些示例-

因此,要解决此问题,首先,我们可以使用更多数据,我们仅在1300张图像上训练了我的检测模型,并且您也可以在识别模型的训练中获取更多数据。 因此,如果我们训练更多的数据,则该模型可能会为包含文本的每个像素预测更准确的标注。
完整代码:https://github.com/vishwas-upadhyaya/mercari_price_suggestion
引用
- https://arxiv.org/abs/1704.03155
- https://arxiv.org/pdf/1801.01671.pdf
- https://www.youtube.com/watch?v=c86gfVGcvh4
- https://github.com/Pay20Y/FOTS_TF
- https://github.com/yu20103983/FOTS/tree/master/FOTS
- https://github.com/Masao-Taketani/FOTS_OCR
- https://www.appliedaicourse.com/course/11/Applied-Machine-learning-course
- https://machinelearningmastery.com/how-to-use-transfer-learning-when-developing-convolutional-neural-network-models/
作者:VISHWAS UPADHYAY
作者:VISHWAS UPADHYAY
deephub翻译组














 341
341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









