






使用SHAP优化特征选择,同时调整参数
特征选择和超参数调整是每个机器学习任务中的两个重要步骤。大多数情况下,它们有助于提高性能,但缺点是时间成本高。参数组合越多,或者选择过程越准确,持续时间越长。这是我们实际上无法克服的物理限制。我们能做的是充分利用我们的管道。我们面临着不同的可能性,最方便的两个是:
- 结合调优和特征选择;
- 采用SHAP(Shapley Additive exPlanations)使整个过程更具有加一般化和准确性。
将调整过程与特征的最佳选择相结合可能是每个基于排名的选择算法的最佳解决方案。排名选择包括迭代删除不太重要的特征,同时重新训练模型直到达到收敛。用于特征选择的模型可能与用于最终拟合和预测的模型不同(在参数配置或类型上)。这可能导致次优的性能。例如,RFE(递归特征消除)或 Boruta 就是这种情况,其中通过算法通过变量重要性选择的特征被另一种算法用于最终拟合。
当我们使用基于排名的算法执行特征选择时,SHAP 会有所帮助。我们没有使用由梯度提升生成的默认变量重要性,而是选择最佳特征,例如具有最高 shapley 值的特征。由于基于原生树的特征重要性存在偏差,因此使用 SHAP 的好处是显而易见的。标准方法倾向于高估连续或高基数分类变量的重要性。这使得在特征变化或类别数量变化的情况下重要性计算变得不可信。
为了克服这些不足,我们开发了 shap-hypetune:一个用于同时调整超参数和特征选择的 Python 包。它允许在单个管道中将超参数调整和特征选择与梯度提升模型相结合。它支持网格搜索或随机搜索,并提供排序特征选择算法,如递归特征消除 (RFE) 或 Boruta。额外的提升包括提供使用 SHAP 重要性进行特征选择的可能性。
在这篇文章中,我们展示了在执行监督预测任务时采用 shap-hypetune 的实用程序。我们尝试搜索最佳参数配置,同时选择带有(和不带有)SHAP 的最佳特征集。我们的实验分为三个试验。给定分类场景中的数据集,我们首先通过优化参数来拟合 LightGBM。然后我们尝试在优化参数的同时使用默认的基于树的特征重要性来操作标准 RFE。最后,我们做同样的事情,但使用 SHAP 选择特征。为了让事情更有趣,我们使用了一个不平衡的二元目标和一些具有高基数的分类特征。
参数调优
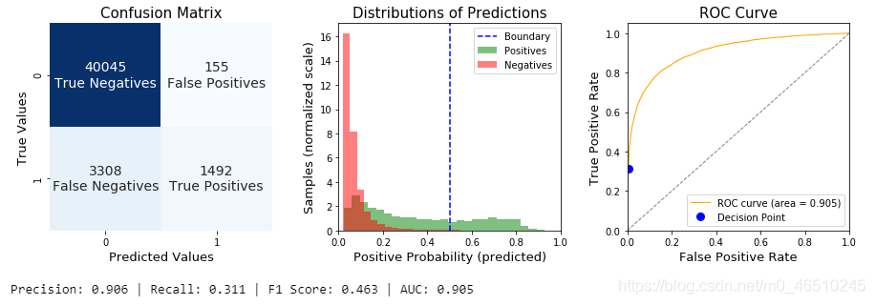
在这第一节中,我们在我们的训练集上计算一个拟合,只搜索最佳参数组合。最好的模型达到精度大于0.9,但我们的测试数据召回率很低。
参数调优+特性选择
一般来说,特征选择是用来从原始数据集合中去除噪声的预测器。我们使用递归特征消除(RFE)来寻找最优的参数集。换句话说,对于每个参数配置,我们在初始训练数据上迭代RFE。通过配置合适的参数,比如提前停止,或者设置较大的步骤,同时删除较差的功能,可以加快生成速度。在验证集中具有最佳分数的管道将被存储,并准备在推断时使用。
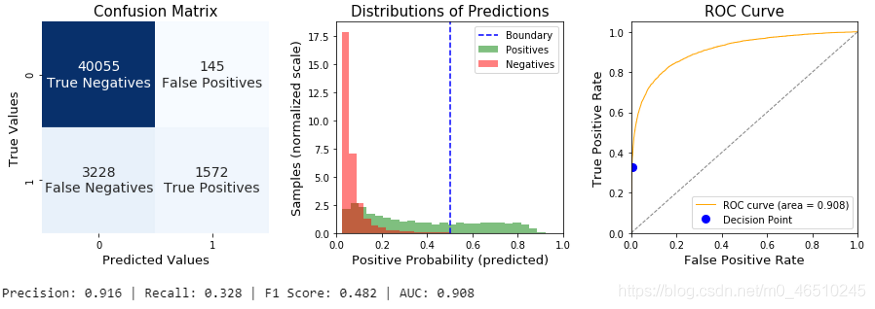
在这种情况下,我们记录了一个整体的改善,但召回和F1分数保持低值。
参数调整+SHAP特征选择
最后,我们重新使用了相同的过程,但使用SHAP的RFE。当与基于树的模型结合使用时,SHAP非常有效。它使用一种树路径方法来跟踪树,并提取每个叶下的训练示例数量,以提供背景计算。它也不太容易过度自信,因为我们可以在验证集上计算重要性,而不是在训练数据上(比如经典的基于树的重要性)。
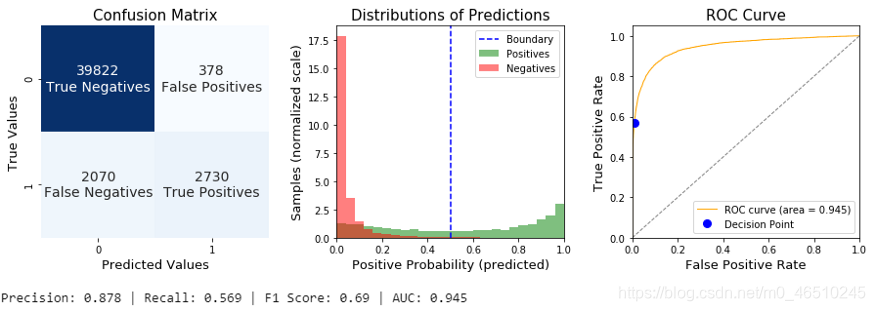
我们发现召回率和F1分数有了很大的提高。SHAP能够处理低质量的分类特征,只保留最好的预测器。
总结
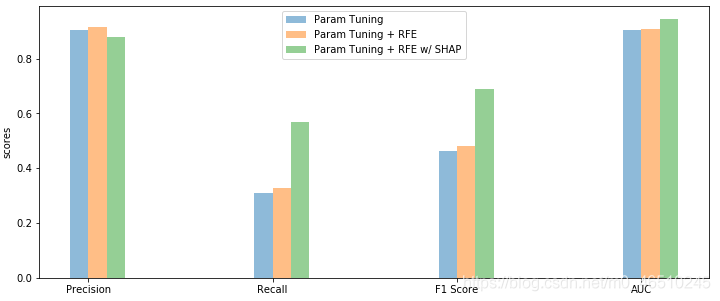
在这篇文章中,我们介绍了shape - hypertune,作为一个有用的框架来进行参数调整和梯度增强模型的最优特征搜索。我们展示了一个应用程序,其中我们使用了网格搜索和递归特征消除,但随机搜索和Boruta是其他可用的选项。我们还看到了如何在传统特征重要性方法缺乏性能的情况下使用SHAP功能改进选择过程。
作者:Marco Cerliani














 823
823











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









