







 本文介绍了一个使用Python进行猫眼电影票房数据爬取的实战案例,通过requests库发送HTTP请求并获取数据,利用csv库将数据保存为CSV文件,展示了如何从指定网站抓取最新电影票房数据的方法。
本文介绍了一个使用Python进行猫眼电影票房数据爬取的实战案例,通过requests库发送HTTP请求并获取数据,利用csv库将数据保存为CSV文件,展示了如何从指定网站抓取最新电影票房数据的方法。
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于CSDN ,作者嗨学编程
前言
随着疫情的转好,电影院终于在7月20日复工了。
电影《八佰》快接近尾声了,截止目前,上映29天票房已破27亿。
让我们来看看近段时间,有哪些电影取得了好的成绩
目标网站
http://piaofang.maoyan.com/dashboard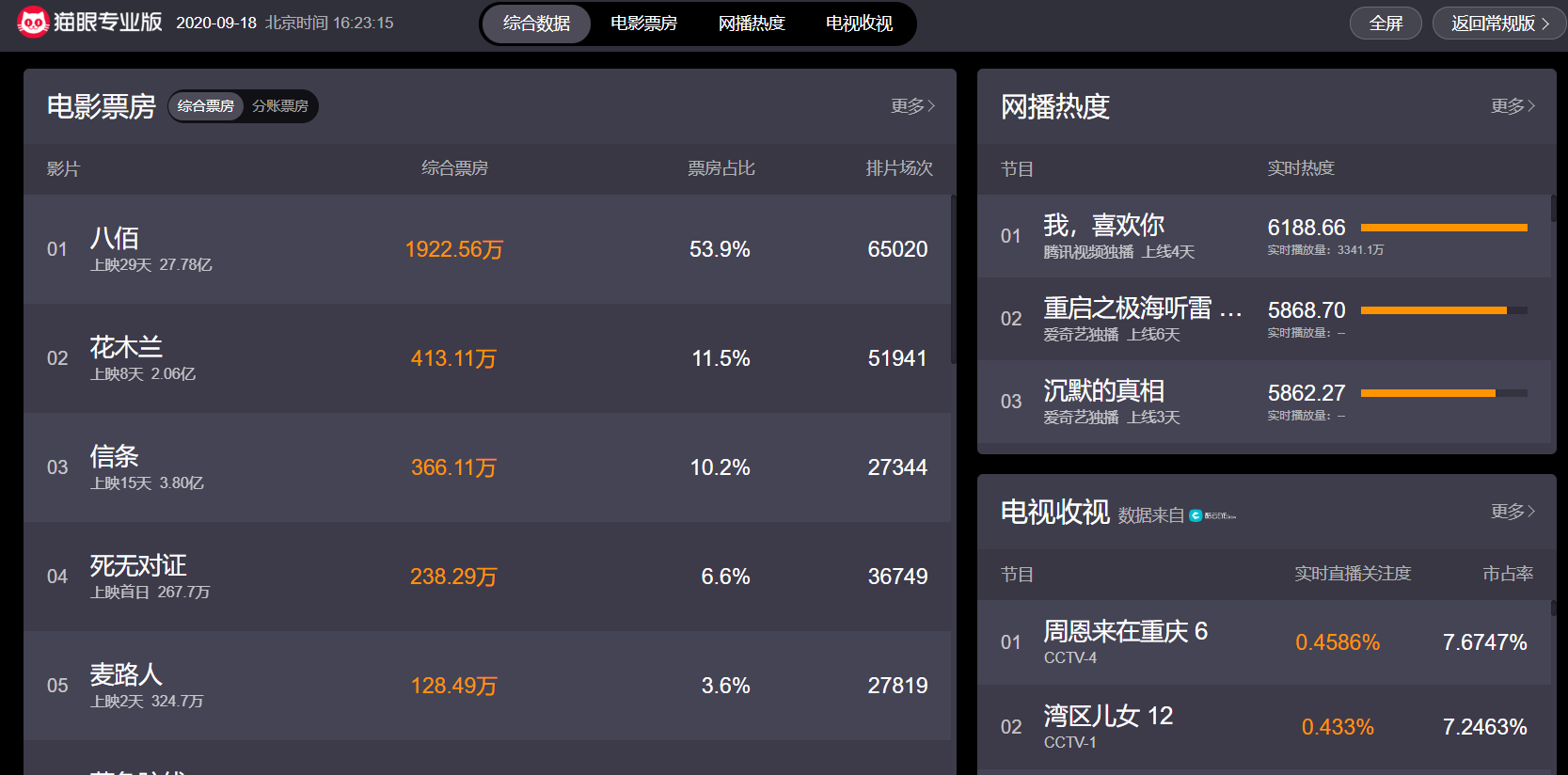

基本环境配置
- python 3.6
- pycharm
- requests
- csv
数据接口
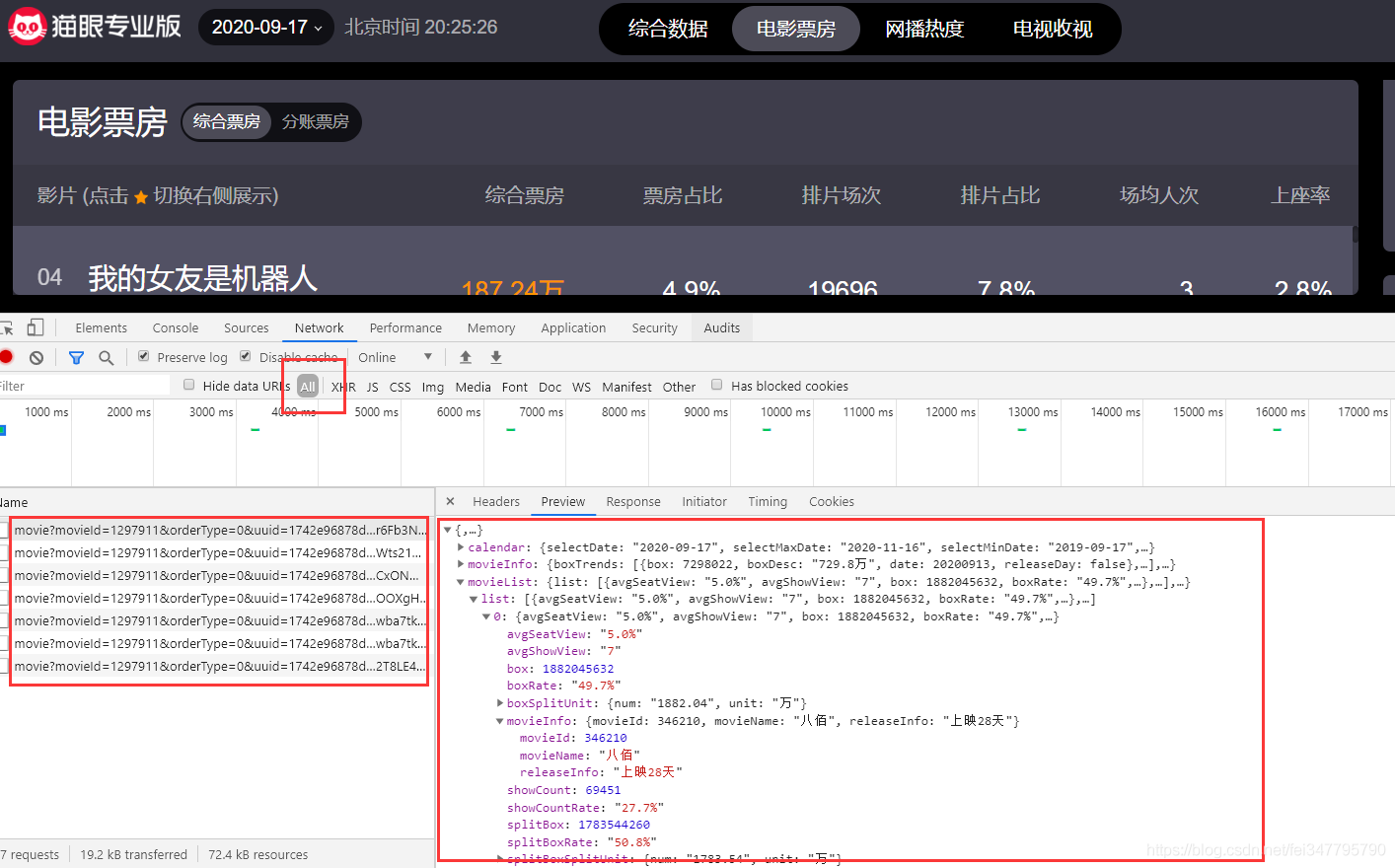
请求网页获取数据
import requests
url = 'http://piaofang.maoyan.com/dashboard-ajax/movie'
params = {
}cookies = {}headers = {}response = requests.get(url=url, params=params, headers=headers, cookies=cookies)
html_data = response.json()pprint.pprint(html_data)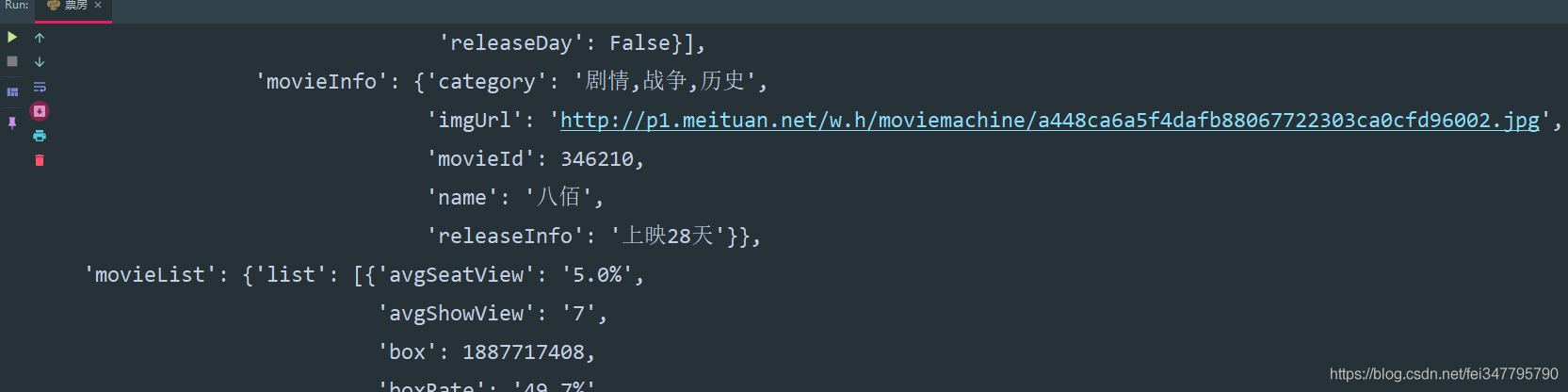
解析数据
movieList = html_data['movieList']['list']
dit = {}for i in movieList: dit['电影名'] = i['movieInfo']['movieName']
dit['票房'] = i['sumBoxDesc']
dit['票房占比'] = i['boxRate']
dit['排片占比'] = i['showCountRate']
dit['上映周期'] = i['movieInfo']['releaseInfo']
pprint.pprint(dit)保存数据
import csv
f = open('data.csv', mode='a', encoding='utf-8', newline='')
csv_write = csv.DictWriter(f, fieldnames=['电影名', '票房', '票房占比', '排片占比', '上映周期'])
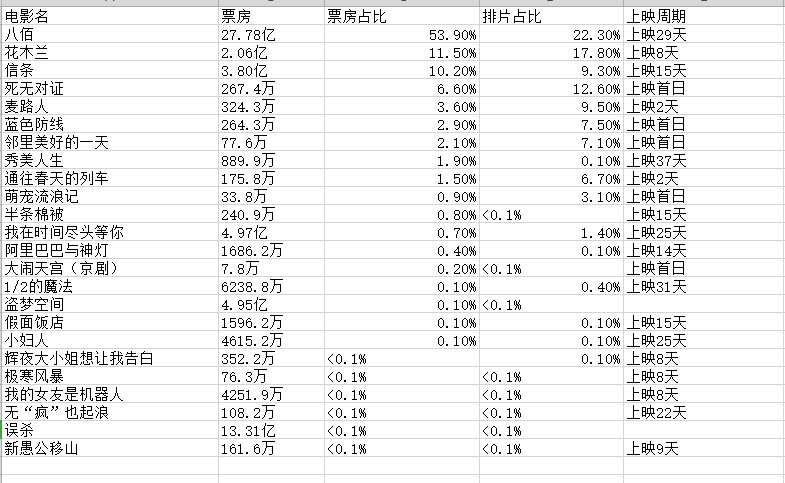
csv_write.writeheader()f.close() 运行代码,结果如下图


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









