







python selenium爬虫
1 前言
博主是一名经管研究生,以自身经历为例。如今大学生写论文大部分都需要数据支撑来论证研究结果,数据除了从数据库直接下载外,有些是需要通过网络爬虫来获得。网络爬虫有很多方法,本文主要介绍selenium爬虫, 版本为python3.6。
2 爬虫
前几天有室友让我爬一个网址:
http://bank.jrj.com.cn/bankpro/data.shtml?type=1&wd=%D1%F8%C0%CF


要求是将所有产品的专业评级、购买信息、收益指标等信息整合成一个excel表格。
2.1 导包
python写代码需要导入一些模块。这里导入webdriver是为了驱动浏览器自动化。导入time模块是为了爬虫休眠,防止ip被封。导入pandas模块是为了将爬取的信息整合到excel表格里。
from selenium import webdriver
import time
import pandas as pd
没有下载包的,直接在cmd里输入这三行就行。
pip install selenium
pip install time
pip install pandas
2.2 发送请求
爬虫的一般流程为发送请求、获取响应内容、解析内容、保存数据四步。第一步是发送请求,我们需要进入这个网页,才能爬取数据。
chrome_driver=r"C:\Program Files (x86)\Google\Chrome\chromedriver.exe" #替换为你的谷歌浏览器驱动位置
bro=webdriver.Chrome()
bro.get('http://bank.jrj.com.cn/bankpro/data.shtml?type=1&wd=%D1%F8%C0%CF') #替换为你需要爬取的网址
这里需要先下载谷歌浏览器驱动,可以先打开谷歌浏览器,找到关于Chrome,查看谷歌浏览器版本,下载对应的驱动。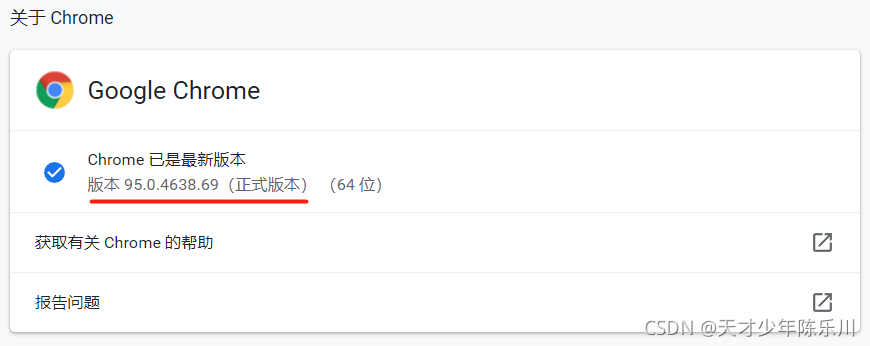
运行后就能看到桌面弹出谷歌浏览器,自动跳转到要爬取的网页。
2.3 爬取内容
本文将获取响应内容、解析内容这两步合并。这部分是本文的重点,需要仔细阅读。这里我们的思路是先爬取所有产品的网址,再进入每个产品网址爬取信息。
先用谷歌浏览器打开爬取的网站,点击F12,浏览器右边会弹出一个框框,再点击Ctrl+Shift+C,鼠标点击第一个产品的名称。可以看到这个href就是第一个产品的网址,也就是我们需要爬取的内容。
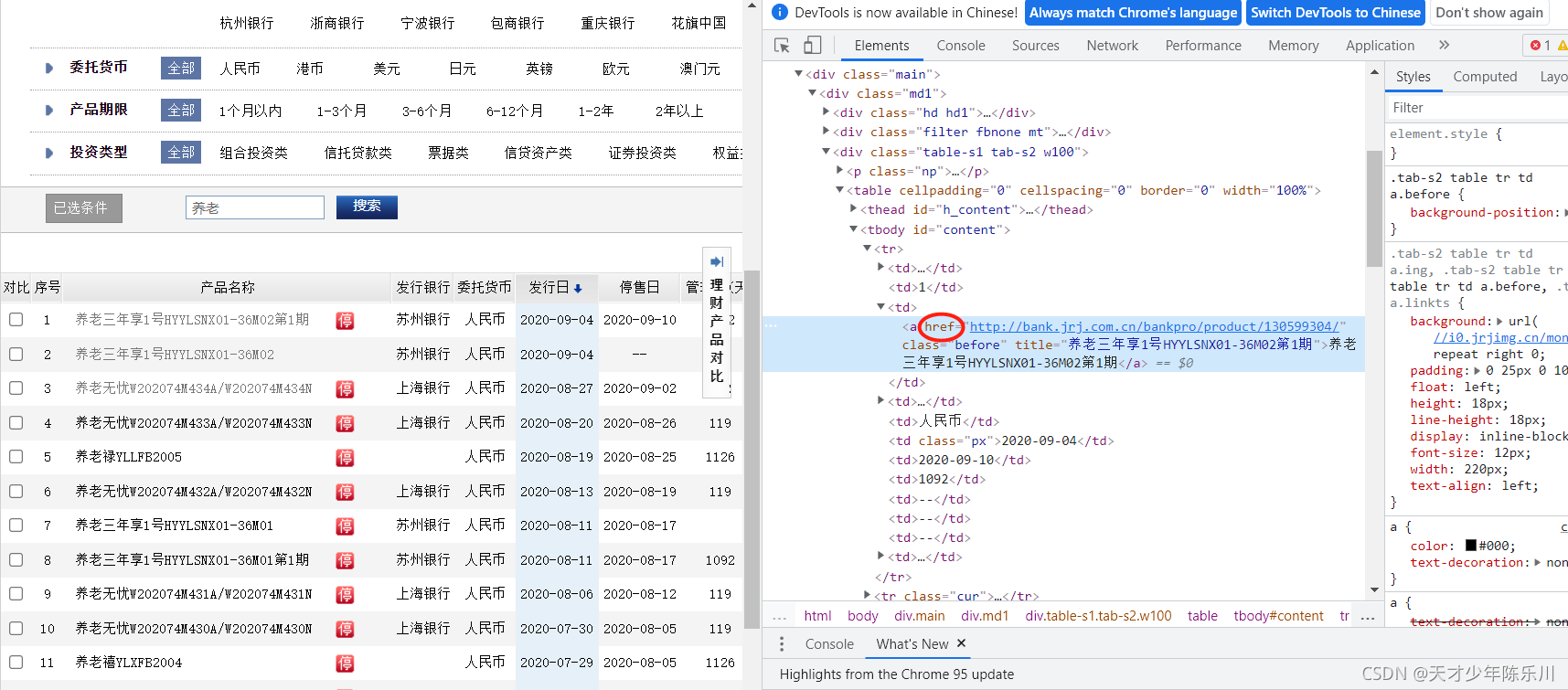
这里我们用xpath定位,教大家一个非常简单的定位方法,右键点击画圈位置,依次点击Copy,Copy full Xpath,粘贴到文本中。
/html/body/div[9]/div/div[3]/table/tbody/tr[1]/td[3]/a #第一个产品
/html/body/div[9]/div/div[3]/table/tbody/tr[2]/td[3]/a #第二个产品
/html/body/div[9]/div/div[3]/table/tbody/tr[4]/td[3]/a #第四个产品
可以看到,这几个产品的区别在tr处,规律是第n个产品,定位就是tr[n]。往下拉可以看到,该网址一页有20条产品信息,我们可以用for循环遍历第一页的所有产品信息,用get_attribute提取网址和产品名称。get_attribute参数根据需要提取内容的标签决定,这里产品网址前面的标签href=“http://”,所以提取网址get_attribute参数为"href"。用format进行字符串格式化,将值赋予到字符串中。
for j in range(20): #一页20条产品信息
url=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("href") #产品网址
name=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("title") #产品名称
time.sleep(1) #加1秒休眠
再用同样的方法,对比第一页第一个产品,第二页第一个产品,第四页第一个产品等等,可以看出定位一模一样,现在的问题便只有如何跳转到第二页了。
我们人为点击下一页,需要将网页拉到底部,看到下一页这个按钮才能点击,selenium也不例外。这里我们用bro.execute_script(‘window.scrollTo(0,document.body.scrollHeight)’)将网页拉到底部,再用bro.find_element_by_partial_link_text(“下一页”)定位到下一页这个按钮。partial_link_text()是模糊匹配,不用link_text精确匹配是因为网页中下一页后面跟了两个箭头,不用find_elements是因为Ctrl+F查到下一页这三个字在网页中是唯一的,再用click()就可以点击到下一页了。
最后我们点到最后一页,可以看到第59页只有11条产品信息,所以需要判断是否是最后一页,若是最后一页,则for j in range(11)。
urls=[]
titles=[]
for i in range(59):
if i != 58:
for j in range(20):
url=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("href")
name=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("title")
sleep(1)
print(url)
urls.append(url)
titles.append(name)
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
btn = bro.find_element_by_link_text("下一页")
btn.click()
else:
for j in range(11):
url=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("href")
name=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("title")
sleep(1)
print(url)
urls.append(url)
titles.append(name)
注意:网页拉到页面底部后仍会加载信息,如果不加休眠可能会定位不到,因为此时页面底部的信息还没加载出来,会导致程序报错。
此时我们已经获得所有产品的网址了,接着我们打开网址,
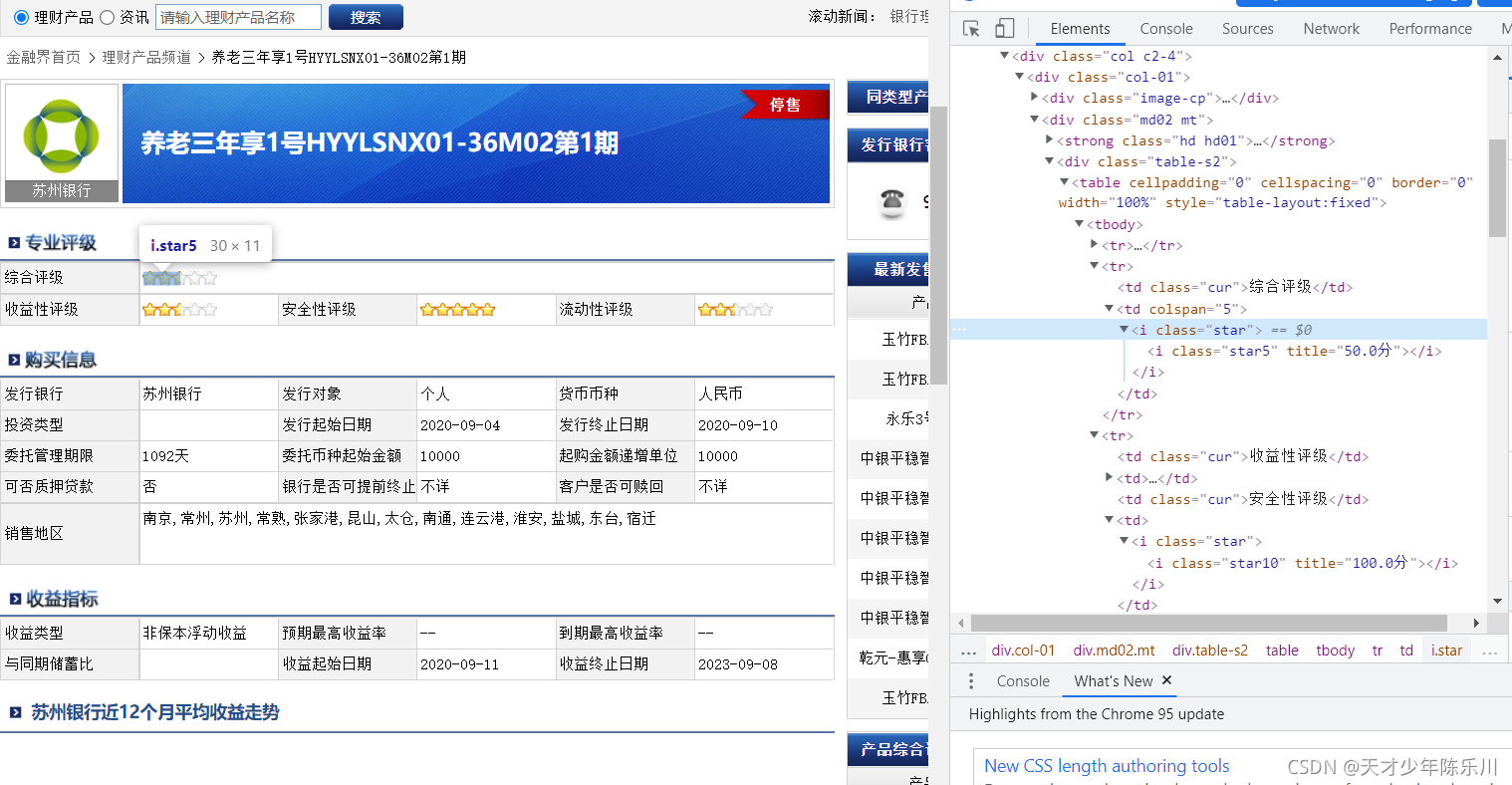
用xpath的方法进行定位,专业评级中分数前面的标签是title,所以用get_attribute(“title”)提取。而购买信息和收益指标的数据前面没有标签,所以用text提取文字。随意点击几个产品,可以看出每个产品的综合评估、发行银行等信息的位置都是一致的。
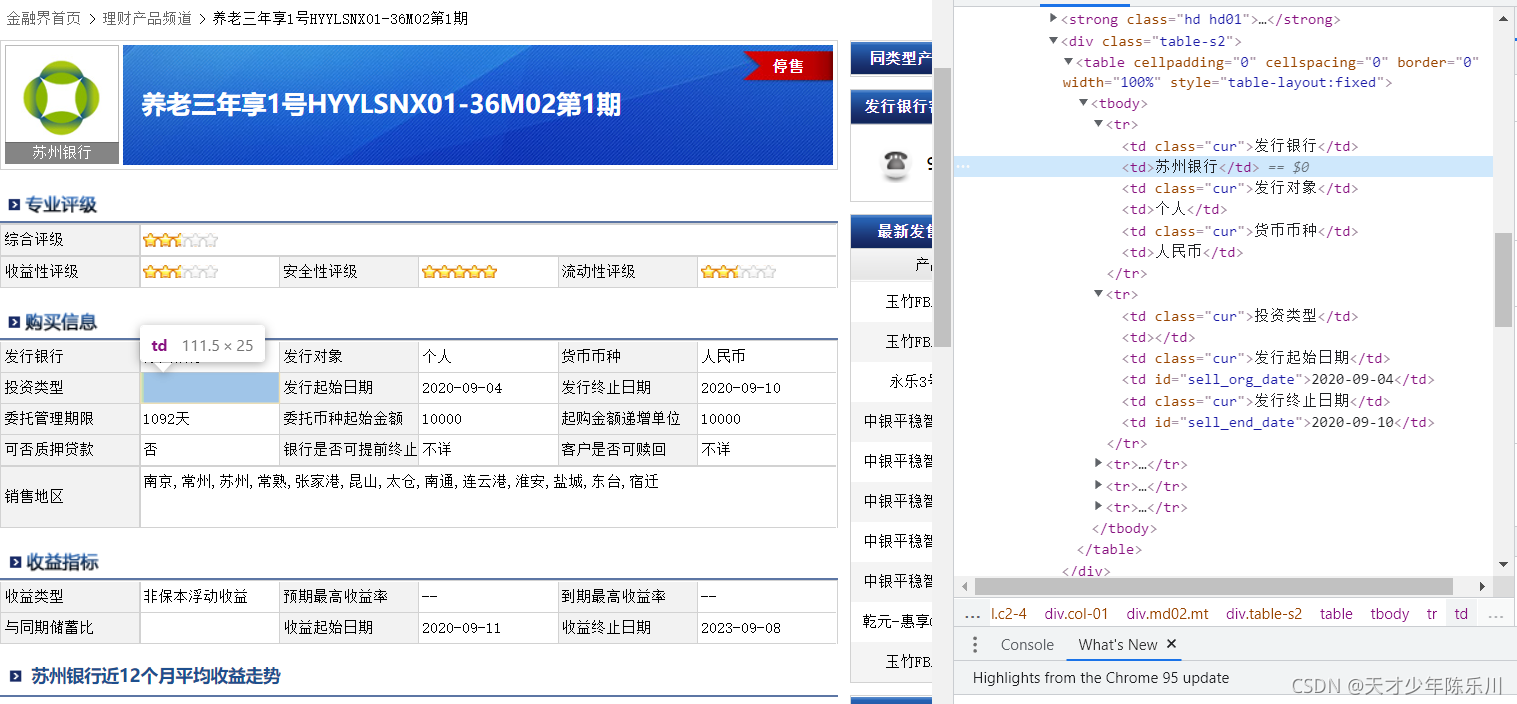
zhpj=[] #综合评级
fxyh=[] #发行银行
sylx=[] #收益类型
for i in urls:
bro.get(i)
zhpj.append(bro.find_element_by_xpath("/html/body/div[9]/div/div[1]/div[2]/div/table/tbody/tr[2]/td[2]/i/i").get_attribute("title"))
fxyh.append(bro.find_element_by_xpath("/html/body/div[9]/div/div[1]/div[3]/div/table/tbody/tr[1]/td[2]").text)
sylx.append(bro.find_element_by_xpath("/html/body/div[9]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[2]").text)
本文只部分展示综合评级,发行银行,收益类型三个数据的爬取,其他信息爬取原理一样。
2.4 保存数据
data=pd.DataFrame()
data['基金名称']=titles
data['综合评级']=zhpj
data['发行银行']=fxyh
data['收益类型']=sylx
data.to_excel('爬取到的数据.xlsx',index=False)
到这里就完成任务了!
完整代码
from selenium import webdriver
from time import sleep
import pandas as pd
chrome_driver=r"C:\Program Files (x86)\Google\Chrome\chromedriver.exe"
bro=webdriver.Chrome()
bro.get('http://bank.jrj.com.cn/bankpro/data.shtml?type=1&wd=%D1%F8%C0%CF')
urls=[]
titles=[]
for i in range(59):
if i != 58:
for j in range(20):
url=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("href")
name=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("title")
sleep(1)
print(url)
urls.append(url)
titles.append(name)
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(2)
btn = bro.find_element_by_link_text("下一页")
btn.click()
else:
for j in range(11):
url=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("href")
name=bro.find_element_by_xpath("/html/body/div[9]/div/div[3]/table/tbody/tr[{}]/td[3]//a".format(1+j)).get_attribute("title")
sleep(1)
print(url)
urls.append(url)
titles.append(name)
zhpj=[]
fxyh=[]
sylx=[]
for i in urls:
bro.get(i)
zhpj.append(bro.find_element_by_xpath("/html/body/div[9]/div/div[1]/div[2]/div/table/tbody/tr[2]/td[2]/i/i").get_attribute("title"))
fxyh.append(bro.find_element_by_xpath("/html/body/div[9]/div/div[1]/div[3]/div/table/tbody/tr[1]/td[2]").text)
sylx.append(bro.find_element_by_xpath("/html/body/div[9]/div/div[1]/div[4]/div/table/tbody/tr[1]/td[2]").text)
data=pd.DataFrame()
data['基金名称']=titles
data['综合评级']=zhpj
data['发行银行']=fxyh
data['收益类型']=sylx
data.to_excel('爬取到的数据.xlsx',index=False)
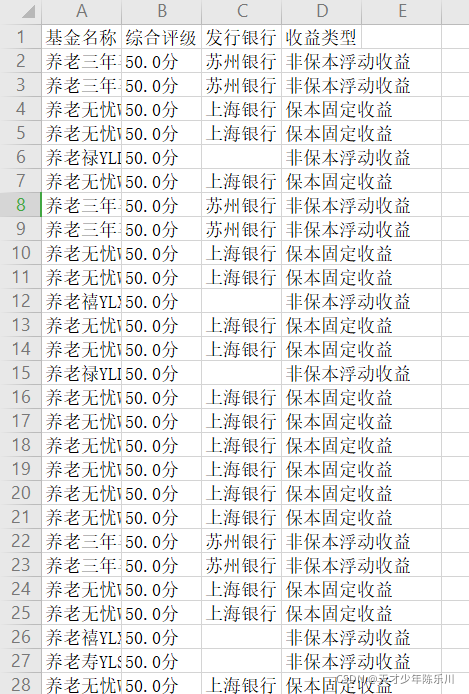
完整结果














 6830
6830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









