







此文章只是学习笔记,不具有任何参考价值。
学习网站:http://c.biancheng.net/view/1902.html
回归是数学建模、分类和预测中最古老但功能非常强大的工具之一。
回归通常是机器学习中使用的第一个算法。通过学习因变量和自变量之间的关系实现对数据的预测。
因此,回归有两个重要组成部分:自变量和因变量之间的关系,以及不同自变量对因变量影响的强度。
以下是几种常用的回归方法:
1.线性回归:使用最广泛的建模技术之一。线性回归假定输入变量(X)和单个输出变量(Y)之间呈线性关系。它旨在找到预测值Y的线性方程
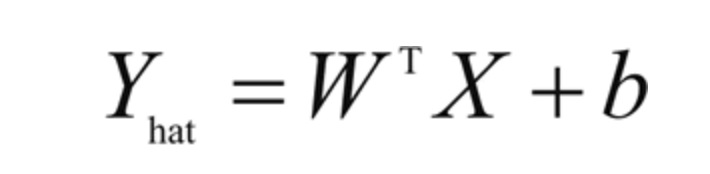
其中,X=(x1,x2,...,xn)为n个输入变量,W=(w1,w2,...,wn)为线性系数,b是偏置项。目标是找到系数W的最佳估计,使得预测值Y的误差最小。使用最小二乘法估计线性系数W,即使预测值(Yhat)与观测值之间的差的平方和最小。
因此这里经靓最小化损失函数:
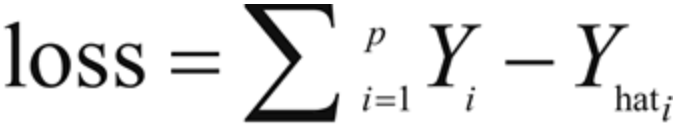
其中,需要对所有训练样本的误差求和。根据输入变量X的数量和类型,可划分出多种线性回归类型:简单线性回归(一个输入变量,一个输出变量),多元线性回归(多个输入变量,一个输出变量),多变量线性回归(多个输入变量,多个输出变量)
2.逻辑回归:用来确定一个事件的概率。通常来说,事件可被表示为类别因变量。事件的概率用logit函数(Sigmoid 函数)表示:
- 用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。
- 在特征相差比较复杂或是相差不是特别大时效果比较好。
- 优点:平滑、易于求导。
- 缺点:激活函数计算量大,反向传播求误差梯度时,求导涉及除法;反向传播时,很容易就会出现梯度消失的情况,从而无法完成深层网络的训练。
Sigmoid函数由下列公式定义:
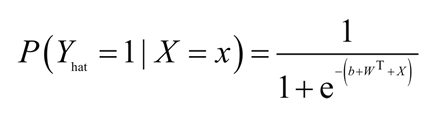
函数图象
现在的目标是估计权重W = (w1,w2,...,wn)和偏置项b。在逻辑回归中,使用最大似然估计或随机梯度下降来估计系数。损失函数通常被定义为交叉熵项:
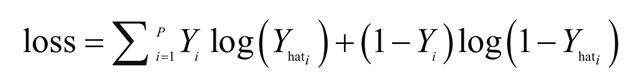
逻辑回归用于分类问题,例如对于给定的医疗数据,可以使用逻辑回归判断一个人是否患有癌症。如果输出类别变量具有两个或多个层级,则可以使用多项式逻辑回归。
另一种用于两个或更多输出变量的常见技术是OneVsAll。 对于多类型逻辑回归,交叉熵损失函数被修改为
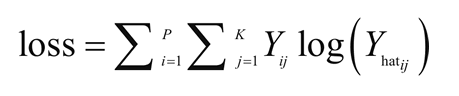
3.正则化:当有大量的输入特征是,需要正则化来确保预测模型不会太复杂。正则化可以帮助防止数据过拟合。它也可以用来获得一个凸损失函数。有两种类型的正则化---L1 和L2 正则化,其描述如下:
- 当数据高度共线时,L1正则化也可以工作。在L1 正则化中,与所有系数的绝对值的和相关的附加惩罚项被添加到损失函数中。L1正则化惩罚项如下:
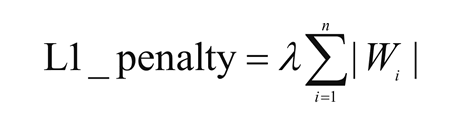
- L2正则化提供了稀疏的解决方案。当输入特征的数量非常大时,非常有用。在这种情况下,惩罚项是所有系数的平方和。
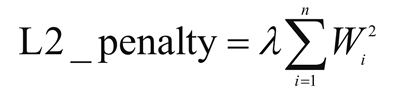
其中,λ是正则化参数。














 840
840











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









