




 本文详细阐述了线程缓存(ThreadCache)、中心缓存(CentralCache)和页缓存(PageCache)在内存回收中的协作过程,涉及小块定长内存的分配、回收策略以及跨层次的内存合并,旨在提升内存利用效率和减少外碎片。
本文详细阐述了线程缓存(ThreadCache)、中心缓存(CentralCache)和页缓存(PageCache)在内存回收中的协作过程,涉及小块定长内存的分配、回收策略以及跨层次的内存合并,旨在提升内存利用效率和减少外碎片。
文章目录
一. ThreadCache回收内存
1. 基本步骤
- 当线程释放对象空间的大小小于256KB时会将内存释放回ThreadCache,计算对象大小bytes映射ThreadCache自由链表桶的下标 i,将对象PushFront到_freeLists[ i ]。
- 当自由链表的长度过长,则回收自由链表中的所有小块定长内存到CentralCache。
2 FreeList类中的补充
补充一:增加一个获取自由链表中小块定长内存个数的接口FreeList::GetSize(...)

补充二:增加一个删除自由链表中头n个小块定长内存的接口FreeList::PopRangeFront(...),注意还需要把要删除的一段小块定长内存通过输出型参数传出:

3. 线程缓存回收一个小块定长内存的实现
ThreadCache回收一个小块定长内存的接口我们在ThreadCache初步设计时就有简单的实现过,那时候的实现仅仅就是“回收一个小块定长内存到自由链表”,这个只是ThreadCache回收内存基本步骤中的第一步:
// ThreadCache初步设计时的释放一个小块定长内存
void ThreadCache::Deallocate(void* ptr, size_t bytes)
{
assert(ptr);
assert(bytes <= MAX_BYTES);
// 1、计算映射到哪一个自由链表桶
size_t index = SizeClass::Index(bytes);
// 2、把小块定长内存头插到自由链表桶中
_freeLists[index].PushFront(ptr);
}
现在继续实现基本步骤中的第二步:当自由链表的长度过长,则回收自由链表中的所有小块定长内存到CentralCache:
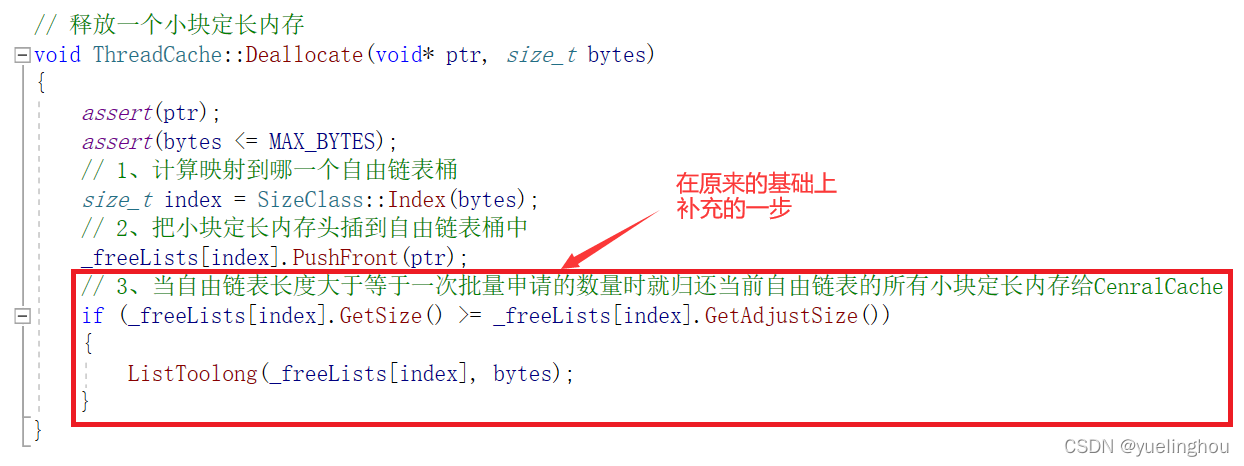
另外我们在线程缓存中新增一个private接口ThreadCache::ListToolong(...)专门用于归还自由链表中的小块定长内存给CenralCache:
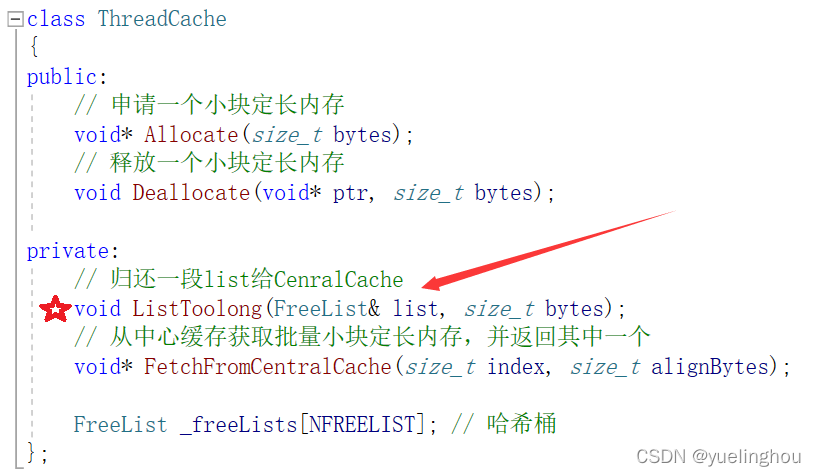
下面是ThreadCache::ListToolong(...)函数的内部实现步骤:
- 把自由链表中的所有小块定长内存剥离。
- 把所有剥离出来的小块定长内存归还到CentralCache对应SpanList桶中的不同Span中。
// 归还一段list给CenralCache
void ThreadCache::ListToolong(FreeList& list, size_t bytes)
{
assert(bytes > 0);
void* start = nullptr;
void* end = nullptr;
// 1、把自由链表中的所有小块定长内存剥离
list.PopRangeFront(start, end, list.GetSize());
// 2、只需要传第一个小块定长内存的指针即可,因为它们是单链表结构组织起来的,最后会走到空
CentralCache::GetInstance()->ReleaseListToSpans(start, SizeClass::Index(bytes));
}
PS:注意ThreadCache和CentralCache的哈希桶映射规则是一样的,所以我们从ThreadCache的某一个自由链表桶中剥离出来的小块定长内存应该回收到CentralCache相同下标的SpanList桶中。而且本来自由链表中存储的一个个小块内存是从中心缓存的某个SpanList桶中的不同Span对象“批发”出来的,具体小块定长内存归还给那个Span对象这个操作由中心缓存的CentralCache::ReleaseListToSpans(...)函数来完成。
二. CentralCache回收内存
1. 基本步骤
- 当ThreadCache中的自由链表过长时会将里面的所有小块定长内存释放回CentralCache的某个Span对象中,每释放回来一个小块定长内存,则Span对象的_useCount减一。
- 当_useCount从1减到0时说明这个Span对象分出去的所有小块定长内存都收回来了,这时我们可以将这个Span对象释放回PageCache,PageCache中会对这个Span对象的前后相邻空闲页进行合并以缓解外碎片问题。
2. PageCache类中的补充
前面说到ThreadCache某个自由链表桶中的每一个小块定长内存需要回收到CentralCache相同映射下标的SpanList桶中的不同Span对象里,那么每一个小块定长内存如何找到它与之对应的span的?
这里要再次说明申请小块定长内存的过程:每一个小块定长内存都是由连续大页内存切分而来的,即一开始申请内存时CentralCache向PageCache要一个k页的Span,然后CentralCache把这个k页连续大块内存切分成许多小块定长内存一部分分配给ThreadCache,另一部分留在Span中。
现在有一个结论就是:每一个小块定长内存的地址模上8KB(一页的大小)就能得到把它切分出来的那一页的页号:
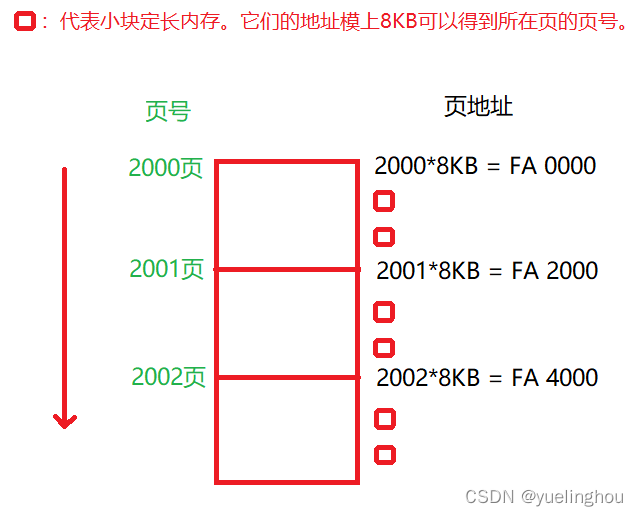
因为每一页的页号都是页地址整除8KB得来的,那么该页切分出来的所有小块定长内存的地址肯定是不能整除8KB的,所以我们对小块定长内存的地址取模8K
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1905
1905

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









