







前言
本文着重分解Hadoop理论基础及底层原理
文中涉及的Hadoop是基于2.x版本(2.9)

1. 大数据
1.1 定义
- 无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合
- 需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力
- 海量、高增长率和多样化的信息资产
1.2 特点
通常,大数据具有如下5大特点(5V):

1.2.1 Volume(大量)
采集、存储和计算的数据量都非常大
以PB为例,PB级数据量有多大?是怎样的一个概念?
假如⼿机播放MP3的速度为平均每分钟1MB,而1⾸歌曲的平均时长为4分钟,那么1PB存量的歌曲可以连续播放2000年。
1PB 也相当于50%的全美学术研究图书馆藏书咨询内容。
(1)1986年,全球只有0.02EB也就是约21000TB的数据量
(2)2007年,全球就是280EB也就是约300000000TB的数据量,翻了14000倍
(3)近些年,由于移动互联网及物联网的出现,各种终端设备的接入,各种业务形式的普及,平均每40个⽉,全球的数据量就会翻倍!2012年,每天会产生2.5EB的数据量
(4)基于IDC的报告预测,从2013年到2020年,全球数据量会从4.4ZB猛增到44ZB!而到了2025年,全球会有163ZB的数据量!
全球的数据量已经大到爆了!而传统的关系型数据库根本处理不了如此海量的数据!
1.2.2 Velocity(高速)
在大数据时代,数据的创建、存储、分析都要求被高速处理
1.2.3 Variety(多样)
数据形式和来源多样化,可分为结构化数据、半结构化数据和非结构化数据
1.2.3.1 结构化数据
例如:RDBMS、Excel
1.2.3.2 半结构化数据
例如:XML、JSON、HTML、网络日志
1.2.3.3 非结构化数据
例如:音频、视频、图片、Word、Text
1.2.4 Veracity(真实)
确保数据的真实性,才能保证数据分析的正确性
1.2.5 Value(低价值)
互联网发展催生了大量数据,信息海量,但价值密度较低
1.3 应用
1.3.1 仓储物流
智能分仓、就近备货和预测式调拨(京东、苏宁)
1.3.2 个性推荐
分析挖掘用户行为数据,为用户实时推荐个性化内容
1.3.3 精准营销
电信套餐:根据用户画像,匹配哪种套餐适合哪类人群
1.3.4 无人驾驶
利用物联网+大数据的无人驾驶汽车
1.3.5 生物医学
流行病预测、智慧医疗、健康管理
例如:影像大数据支撑下的早期肺癌支撑平台,基于大量病例数据样本,制定早期肺癌高危人群预警指标
1.3.6 人工智能
语音识别、机器人技术(如AlphaGo)等
1.3.7 智慧城市
大数据有效支撑智慧城市发展,成为城市的“数据大脑”
例如:覆盖面广的移动支付、新颖的在线医疗模式、创新的物流运输模式
2. Hadoop
2.1 概述

Hadoop 是一个大数据的分布式存储和计算平台,有狭义和广义之分。
2.1.1 狭义的Hadoop
一个框架平台。
2.1.2 广义的Hadoop
代表大数据的一个技术生态圈,包括很多其他软件框架。
2.2 发行版
2.2.1 Apache Hadoop 原始版本
Apache(非营利性组织)发布的免费开源版本
优点:
- 拥有全世界的开源贡献,代码更新版本比较快
- 学习非常方便,可随时翻阅文档
缺点:
- 版本的升级、维护困难
- 版本之间的兼容性不友好
2.2.2 Cloudera CDH 版本
Cloudera(商业公司)发布的收费软件,可在生产环境使用
2.2.3 HortonWorks HDP 版本
HortonWorks(商业公司,已被Cloudera收购)发布的收费软件,可在生产环境使用
2.3 版本更迭
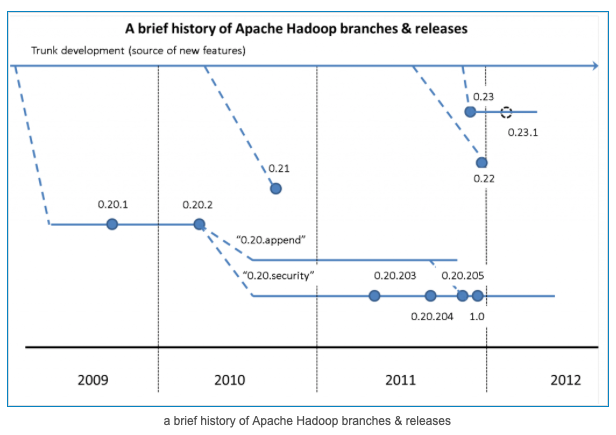
2.3.1 v0.x 系列版本
Hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本
2.3.2 v1.x 系列版本
Hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.3.3 v2.x 系列版本
架构产生重大变化,引入了YARN平台等许多新特性
2.3.4 v3.x 系列版本
EC技术、YARN的时间轴服务等新特性
2.4 优缺点
2.4.1 优点
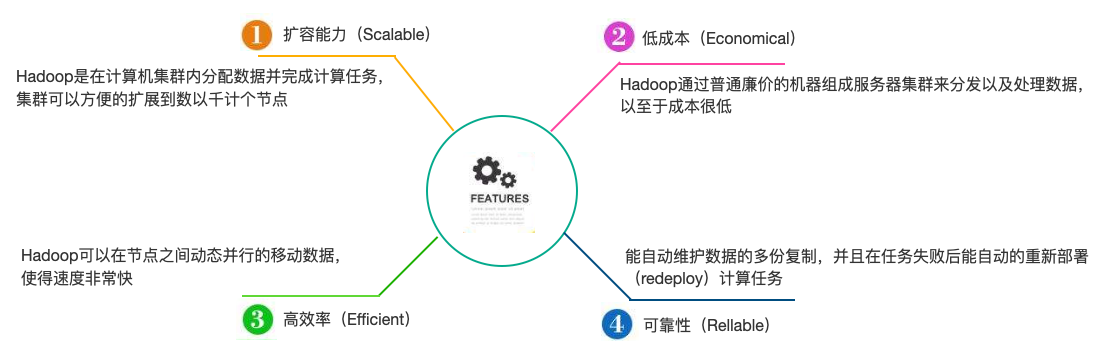
2.4.1.1 高可靠性
具有存储和处理海量数据的能力
2.4.1.2 高扩展性
集群可以方便地扩展到数以千计的节点中
2.4.1.3 低成本性
可使用廉价机器即可搭建集群
2.4.1.4 高效性
能够在节点之间进行动态地移动数据,并保证各个节点的动态平衡,处理速度非常快
2.4.1.5 高容错性
- 能自动维护数据的多份副本
- 能自动重新分配失败的任务
2.4.2 缺点
- Hadoop不适用于低延迟数据访问
- Hadoop不能高效存储大量小文件
- Hadoop不支持多用户写入并任意修改文件
2.5 搭建方式
- 单机模式
- 单机伪分布式模式
- 完全分布式模式
2.6 重要组成
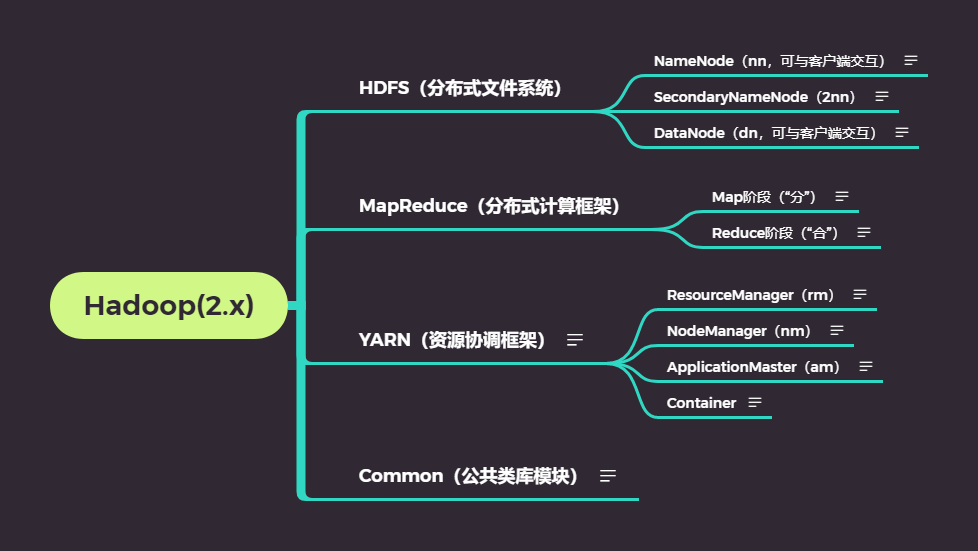
2.6.1 HDFS
HDFS(Hadoop Distributed File System )是一个高可靠的、高吞吐量的分布式文件系统。
1. HDFS 通过统一的命名空间目录树来定位文件
2. HDFS 是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的⻆⾊,分布式本质是拆分,各司其职
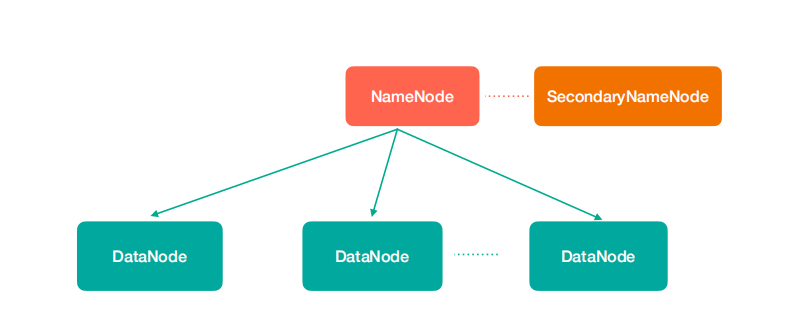
2.6.1.1 重要角色
作用:管理和维护文件的元数据
比如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- 注意:如果NameNode挂掉,即便分散在各DataNode上的数据块是正常的,那么整个HDFS集群依然不可用(因为我们无法得知数据块的存储位置等元数据信息)
作用:辅助NameNode更好地工作
用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据快照
作用:在本地文件系统存储文件块数据,以及块数据的校验
2.6.1.2 重要概念
(1)Master(NameNode):
1. HDFS集群的管理者
2. 维护管理HDFS的命名空间(NameSpace)
3. 维护副本策略
4. 记录文件块(Block)的映射信息
5. 负责处理客户端读写请求
(2)Slave(Datanode):
1. 真正负责Block存储的角色
2. 负责Block的读写
(3)Client:
1. 负责将文件切分成Block,然后上传
2. 请求NameNode交互,获取文件的位置信息
3. 读取或写入文件,与DataNode交互
4. Client可以使用一些命令来管理HDFS或者访问HDFS
- HDFS中的文件在物理上是分块存储(Block)的
- 文件块的大小可以通过配置参数来规定(Hadoop2.x中默认的Block大小是128M)
- HDFS通过统一的命名空间目录树来定位文件
- 文件系统名字空间的层次结构和大多数现有的文件系统类似,用户可以创建、删除、移动或重命名文件
- Namenode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode记录下来
- HDFS提供给客户单一个抽象目录树,访问形式:hdfs://namenode的hostname:port/test/input(如hdfs://linux121:9000/test/input)
- 元数据:目录结构及文件分块位置信息
- NameNode的元数据记录每一个文件所对应的Block信息(Block的id,以及所在的DataNode节点的信息)
- 文件的各个Block的具体存储管理由DataNode节点承担
- 一个Block会有多个DataNode来存储
- DataNode会定时向NameNode汇报自己持有的Block信息
- 为了容错,文件的所有 Block 都会有副本
- 每个文件的 Block 大小和副本系数都可配置
- 副本系数在文件创建时和创建后都可以改变(默认是3)
- HDFS 是设计成适应一次写入,多次读出的场景
- 不支持文件的随机修改(支持追加写入,不支持随机更新)
- 因此,HDFS 适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用(修改不方便,延迟大,网络开销大,成本太高)
2.6.1.3 客户端操作
HDFS常用操作命令如下:
# 显示目录信息
hdfs dfs -ls
# 在HDFS上创建目录
hdfs dfs -mkdir
# 从本地文件系统中拷⻉文件到HDFS路径去
hdfs dfs -put/-copyFromLocal
# 从HDFS拷⻉到本地
hdfs dfs -get/-copyToLocal
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2374
2374











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









