






kube scheduler的调度过程是有一个个的扩展点组成的,调度阶段包括sort,filter,score,reserve,permit,绑定阶段包括bind,每个扩展点又有很多的调度插件组成,在sort阶段,待调度的pod都会放在activeQ对列中,这是一个基于堆实现的优先级对列,因为我们可以给pod设置优先级,比如加上priorityclass字段,不加这个字段,会根据pod创建的先后顺序调度,filter有三个扩展点prefilter,filter,postfilter,
 prefilter的作用就是先计算一些节点的信息,为后续filter阶段过滤一些明显不符合要求的节点,比如它的noderesourcefit会计算node资源是否符合pod的标准,然后存储这个信息,在filter的noderesourcefit阶段进行判断
prefilter的作用就是先计算一些节点的信息,为后续filter阶段过滤一些明显不符合要求的节点,比如它的noderesourcefit会计算node资源是否符合pod的标准,然后存储这个信息,在filter的noderesourcefit阶段进行判断
filter会为prefilter阶段筛选剩下来的的node进行在筛选,如果某个插件判断节点不符合要求,剩余的插件就不会再计算了
postfiter扩展点,只会在filter结束后没有任何节点符合要求才运行,它只有一个默认插件,会遍历所在命名空间下所有pod,delete掉可以被抢占的pod,加入待调度对列
score是为filter过滤剩余的node进行打分,分最高的就是最终选定的节点,它包括prescore和score
reserve扩展点只实现了一个插件,volumebinding更新pod声明的pvc和对应的pv缓存信息,表明这个pv已经被pod绑定
permit默认没有扩展点
bind扩展点有三个,prebind,bind,postbind,prebind扩展点有一个内置插件volumebinding这个插件会调用pv controller完成绑定操作,bind扩展点也只有一个默认的插件defaultbinder吧pod.spec.nodename更新为选定出来的node
调度分为两个cycle是为了增加效率,在bind过程中有两次外部api调用,apiserver和 pv controller,另起一个go协程进行bind,在scheduling cycle阶段node信息是从本地缓存获取,具体实现原理就是先list获取所有的node信息,再watch他们的变化更新到本地缓存
下面的图片展示了scheduler的源码架构
 schedulerCache缓存pod,node等信息,各个扩展点在计算所需要的node和pod信息都是从它获取
schedulerCache缓存pod,node等信息,各个扩展点在计算所需要的node和pod信息都是从它获取
informer是client-go提供的能力,它是监听目标资源的变化,同步到本地缓存,具体来说scheduler监听了,node,pod,csinode,csidriver,csistoragecapability,pv,pvc,storageclassq,后面的是很存储有关,是因为prefilter和filter扩展点的插件里面有volumebinding这个插件,检查系统当前是否能够满足pod声明的pvc,不满足把pod放到unscheduledQ里面
schedulerQueue包含三个对列,activeQ,podBackofdQ,unscheduledpods,第一个是优先对列基于堆实现,用于存放待调度的pod,第二个是用来存放异常的pod,第三个用于存放调度失败的pod,过了一定的时间,异常或失败的pod会重新加入activeQ对列重新调度
当一个新的pod创建出来后这个流程是怎样走的,
1.informer监听到了有新创建的pod,根据优先级吧它加入activeQ中
2.scheduler从activeQ中取出一个pod进行调度
3.执行filter扩展点包括prefilter,filter,postfiter,选出符合pod的node如果没找到,把pod加入到unscheduledQ中,这次调度失败
4.执行score插件,找出最符合要求的node
5.assume pod pod调度成功,更新缓存中的node.和podstatus信息,开启一个新的协程进行绑定
6.执行reserve插件
7.启动协程绑定node就是吧pod字段下的nodename换成选定的node名字
为一个pod选择一个node是按照固定顺序执行扩展点的,扩展点不支持。增加,但是可以支持增加插件

为一个pod选择一个node是按照固定顺序执行扩展点的,扩展点不支持。增加,但是可以支持增加插件这些插件是通过profile包下的一个字典定义的,

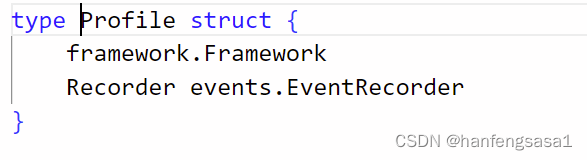 Profiles 是一个 key 为 scheduler name,value 是 framework.Framework 的map,表示根据 scheduler name 来获取 framework.Framework 类型的值,所以可以有多个scheduler
Profiles 是一个 key 为 scheduler name,value 是 framework.Framework 的map,表示根据 scheduler name 来获取 framework.Framework 类型的值,所以可以有多个scheduler
其实 kube-scheduler 运行的时候可以指定配置文件,而不直接把参数写在启动命令上,如下形式。
./kube-scheduler --config /etc/kube-scheduler.conf
于是乎,我们就可以在配置文件中配置我们调度器的插件了
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
clientConnection:
kubeconfig: "/etc/kubernetes/scheduler.conf"
profiles:
- schedulerName: my-scheduler
plugins:
preFilter:
enabled:
- name: zoneLabel
disabled:
- name: NodePorts
也可以定义多个调度器
apiVersion: kubescheduler.config.k8s.io/v1beta2
kind: KubeSchedulerConfiguration
leaderElection:
leaderElect: true
clientConnection:
kubeconfig: "/etc/kubernetes/scheduler.conf"
profiles:
- schedulerName: my-scheduler-1
plugins:
preFilter:
enabled:
- name: zoneLabel
- schedulerName: my-scheduler-2
plugins:
queueSort:
enabled:
- name: mySort
当一个 Pod 需要被调度的时候,kube-scheduler 会先取出 Pod 的 schedulerName 字段的值,然后通过 Profiles[schedulerName],拿到 framework.Framework 对象,进而使用这个对象开始调度可以用下面的图片描述
 下面是framework的定义
下面是framework的定义
// pkg/scheduler/framework/interface.go
type Framework interface {
Handle
QueueSortFunc() LessFunc
RunPreFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod) (*PreFilterResult, *Status)
RunPostFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
RunPreBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunPostBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunReservePluginsReserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunReservePluginsUnreserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunPermitPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
WaitOnPermit(ctx context.Context, pod *v1.Pod) *Status
RunBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
HasFilterPlugins() bool
HasPostFilterPlugins() bool
HasScorePlugins() bool
ListPlugins() *config.Plugins
ProfileName() string
}
那么需要用户自己实现么?答案是不用,kube-scheduler 已经有一个该接口的实现:frameworkImpl
// pkg/scheduler/framework/runtime/framework.go
type frameworkImpl struct {
registry Registry
snapshotSharedLister framework.SharedLister
waitingPods *waitingPodsMap
scorePluginWeight map[string]int
queueSortPlugins []framework.QueueSortPlugin
preFilterPlugins []framework.PreFilterPlugin
filterPlugins []framework.FilterPlugin
postFilterPlugins []framework.PostFilterPlugin
preScorePlugins []framework.PreScorePlugin
scorePlugins []framework.ScorePlugin
reservePlugins []framework.ReservePlugin
preBindPlugins []framework.PreBindPlugin
bindPlugins []framework.BindPlugin
postBindPlugins []framework.PostBindPlugin
permitPlugins []framework.PermitPlugin
clientSet clientset.Interface
kubeConfig *restclient.Config
eventRecorder events.EventRecorder
informerFactory informers.SharedInformerFactory
metricsRecorder *metricsRecorder
profileName string
extenders []framework.Extender
framework.PodNominator
parallelizer parallelize.Parallelizer
}
frameworkImpl 这个结构体里面包含了每个扩展点插件数组,所以某个扩展点要被执行的时候,只要遍历这个数组里面的所有插件,然后执行这些插件就可以了。我们看看 framework.FilterPlugin 是怎么定义的(其他的也类似):
type Plugin interface {
Name() string
}
type FilterPlugin interface {
Plugin
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}
frameworkImpl 这个结构体里面包含了每个扩展点插件数组,所以某个扩展点要被执行的时候,只要遍历这个数组里面的所有插件,然后执行这些插件就可以了。我们看看 framework.FilterPlugin 是怎么定义的(其他的也类似):
type Plugin interface {
Name() string
}
type FilterPlugin interface {
Plugin
Filter(ctx context.Context, state *CycleState, pod *v1.Pod, nodeInfo *NodeInfo) *Status
}
插件数组的类型是一个接口,那么某个插件只要实现了这个接口就可以被运行。实际上,我们前面说的那些默认插件,都实现了这个接口,在目录 pkg/scheduler/framework/plugins 目录下面包含了所有内置插件的实现,主要就是对上面说的这个插件接口的实现。我们可以简单用图描述下 Pod被调度的时候执行插件的流程
 那么这些默认插件是怎么加到framework里面的,自定义插件又是怎么加进来的呢?
那么这些默认插件是怎么加到framework里面的,自定义插件又是怎么加进来的呢?
分三步:
1.根据配置文件(--config指定的)、系统默认的插件,按照扩展点生成需要被加载的插件数组(包括插件名字,权重信息),也就是初始化 KubeSchedulerConfiguration 中的 Profiles 成员。
2.创建 registry 集合,这个集合内是每个插件实例化函数,也就是 插件名字->插件实例化函数的映射,通俗一点说就是告诉系统:1.我叫王二; 2. 你应该怎么把我创建出来。那么张三、李四、王五分别告诉系统怎么创建自己,就组成了这个集合。
将(1)中每个扩展点的每个插件(就是插件名字)拿出来,去(2)的映射(map)中获取实例化函数,然后运行这个实例化函数,最后把这个实例化出来的插件(可以被运行的)追加到上面提到过的 frameworkImpl 中对应扩展点数组中,这样后面要运行某个扩展点插件的时候就可以遍历运行就可以了。我们可以把上述过程用下图表示

Scheduler 之 SchedulingQueue
上面我们介绍了 Scheduler 第一个关键成员 Profiles 的初始化和作用,下面我们来谈谈第二个关键成员:SchedulingQueue
SchedulingQueue 是一个 internalqueue.SchedulingQueue 的接口类型,PriorityQueue 对这个接口进行了实现,创建 Scheduler 的时候 SchedulingQueue 会被 PriorityQueue 类型对象赋值。
PriorityQueue 中有关键的3个成员:activeQ、podBackoffQ、unschedulablePods。
activeQ 是一个优先队列,用来存放待调度的 Pod,Pod 按照优先级存放在队列中
podBackoffQ 用来存放异常的 Pod, 该队列里面的 Pod 会等待一定时间后被移动到 activeQ 里面重新被调度unschedulablePods 中会存放调度失败的 Pod,它不是队列,而是使用 map 来存放的,这个 map 里面的 Pod 在一定条件下会被移动到 activeQ 或 podBackoffQ 中
PriorityQueue 还有两个方法:flushUnschedulablePodsLeftover 和 flushBackoffQCompleted
flushUnschedulablePodsLeftover:调度失败的 Pod 如果满足一定条件,这个函数会将这种 Pod 移动到 activeQ 或 podBackoffQ
flushBackoffQCompleted:运行异常的 Pod 等待时间完成后,flushBackoffQCompleted 将该 Pod 移动到 activeQ
Scheduler 在启动的时候,会创建2个协程来定期运行这两个函数
Scheduler 之 cache
要说 cache 最大的作用就是提升 Scheduler 的效率,降低 kube-apiserver(本质是 etcd)的压力,在调用各个插件计算的时候所需要的 Node 信息和其他 Pod 信息都缓存在本地,在需要使用的时候直接从缓存获取即可,而不需要调用 api 从 kube-apiserver 获取。cache 类型是 internalcache.Cache 的接口,cacheImpl 实现了这个接口
cacheImpl 中的 nodes 存放集群内所有 Node 信息;podStates 存放所有 Pod 信息;,assumedPods 存放已经调度成功但是还没调用 kube-apiserver 的进行绑定的(也就是还没有执行 bind 插件)的Pod,需要这个缓存的原因也是为了提升调度效率,将绑定和调度分开,因为绑定需要调用 kube-apiserver,这是一个重操作会消耗比较多的时间,所以 Scheduler 乐观的假设调度已经成功,然后返回去调度其他 Pod,而这个 Pod 就会放入 assumedPods 中,并且也会放入到 podStates 中,后续其他 Pod 在进行调度的时候,这个 Pod 也会在插件的计算范围内(如亲和性), 然后会新起协程进行最后的绑定,要是最后绑定失败了,那么这个 Pod 的信息会从 assumedPods 和 podStates 移除,并且把这个 Pod 重新放入 activeQ 中,重新被调度。
Scheduler 在启动时首先会 list 一份全量的 Pod 和 Node 数据到上述的缓存中,后续通过 watch 的方式发现变化的 Node 和 Pod,然后将变化的 Node 或 Pod 更新到上述缓存中
Scheduler 之 NextPod 和 SchedulePod,NextPod 和 ScheduleOne:尝试从 activeQ 获取一个 Pod,开始调度















 1001
1001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









