






一/卷积神经网络
1/概念
卷积神经网络(Convolutional Neural Network,CNN)是一种在计算机视觉和图像识别领域广泛应用的深度学习模型。它通过使用卷积层(Convolutional Layer)和池化层(Pooling Layer)来自动提取图像中的特征,并通过全连接层(Fully Connected Layer)进行分类或回归。
与传统的神经网络相比,卷积神经网络的主要特点是它能够处理具有网格结构的输入数据,例如图像。它利用卷积操作来学习局部特征,并通过共享权重和参数的方式减少模型的参数量,从而提高模型的运算效率和泛化能力。
卷积神经网络的基本组件包括:
卷积层:通过应用一系列的滤波器(卷积核)对输入进行卷积操作,提取输入数据中的局部特征。
激活函数层:对卷积层的输出进行非线性变换,引入非线性因素,常见的激活函数包括ReLU、Sigmoid和Tanh等。
池化层:通过对局部区域进行下采样或汇聚操作,减小特征图的尺寸,降低模型复杂性,并增强特征的不变性。
全连接层:将经过卷积操作和池化操作后的特征图展平为一维向量,并通过神经网络的全连接层进行分类或回归。
卷积神经网络在图像识别、目标检测、语义分割和人脸识别等任务上表现出色。它具有良好的特征提取能力、参数共享性和平移不变性等优势,在处理大规模图像数据时具有很强的适应性和表现力。
2/练习记录



二/python_basics图像处理
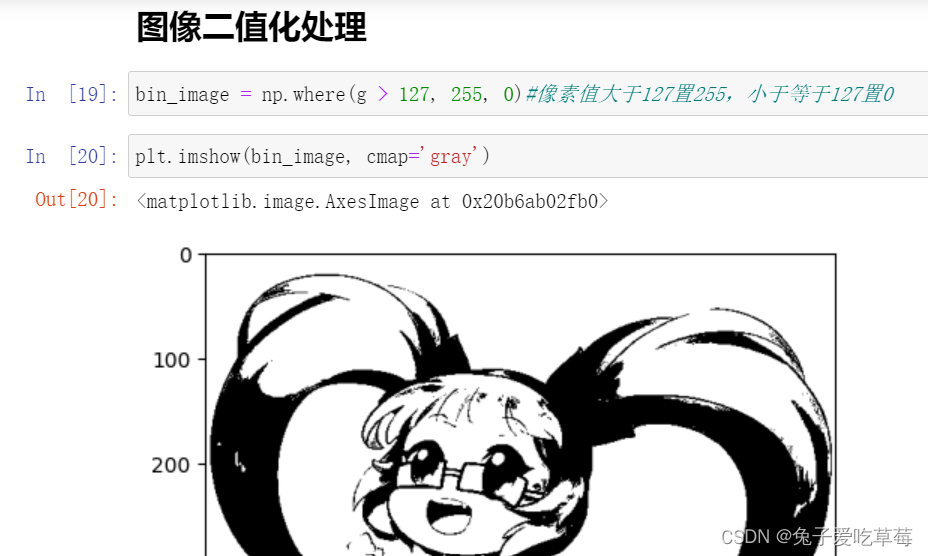
1/图像二值化
图像二值化是一种常用的图像处理方法,其原理是将一幅彩色或灰度图像转换为只有两个像素值的二值图像,其中一个像素值表示目标物体,另一个像素值表示背景。
二值化处理的目的是将图像中的目标物体与背景进行明确的分割,以便后续的分析和处理。例如,在字符识别中,可以将字符与背景分割开来,便于字符的识别和提取。
常用的二值化方法有全局阈值法、自适应阈值法和局部阈值法。
2/图像的sepia
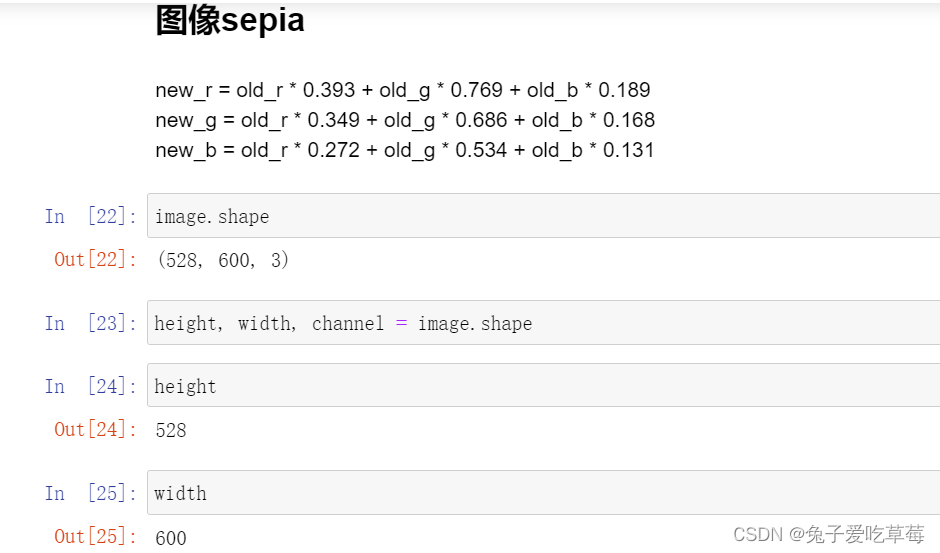
图像的sepia(或称为“怀旧”)效果是一种通过调整图像的色调和饱和度来模拟古老照片的外观。它给图像添加了一种暖色调,使图像呈现出类似于怀旧照片的效果。通常,sepia效果使图像的阴影部分变为棕黄色,高光部分变为淡黄色,整体图像呈现出一种古旧的感觉。
sepia效果的实现通常涉及以下步骤:
1.将图像从彩色或灰度转换为RGB颜色空间。
2.调整图像的色调和饱和度,使其整体呈现出暖色调。
3.根据需要,可以进一步调整图像的对比度和亮度以增强效果。
4.将图像转换回原始颜色空间,如灰度或其他颜色空间。

"""
图像棕色处理
image: ndarray, 原图
return: ndarray, 棕色图
"""
def sepia_style(image):
height, width, _ = image.shape
simage = np.zeros(image.shape)
for i in range(height):
for j in range(width):
old_red = image[i, j, 0] * 0.393 + image[i, j, 1] * 0.769 + image[i, j, 2] * 0.189
old_green = image[i, j, 0] * 0.349 + image[i, j, 1] * 0.686 + image[i, j, 2] * 0.168
old_blue = image[i, j, 0] * 0.272 + image[i, j, 1] * 0.534 + image[i, j, 2] * 0.131
simage[i, j, 0] = maxpixel(old_red) #处理超过255的像素值
simage[i, j, 1] = maxpixel(old_green) #处理超过255的像素值
simage[i, j, 2] = maxpixel(old_blue) #处理超过255的像素值
simage = simage.astype(np.uint8)#将浮点的像素值转换为8bit无符号的整型
return simage
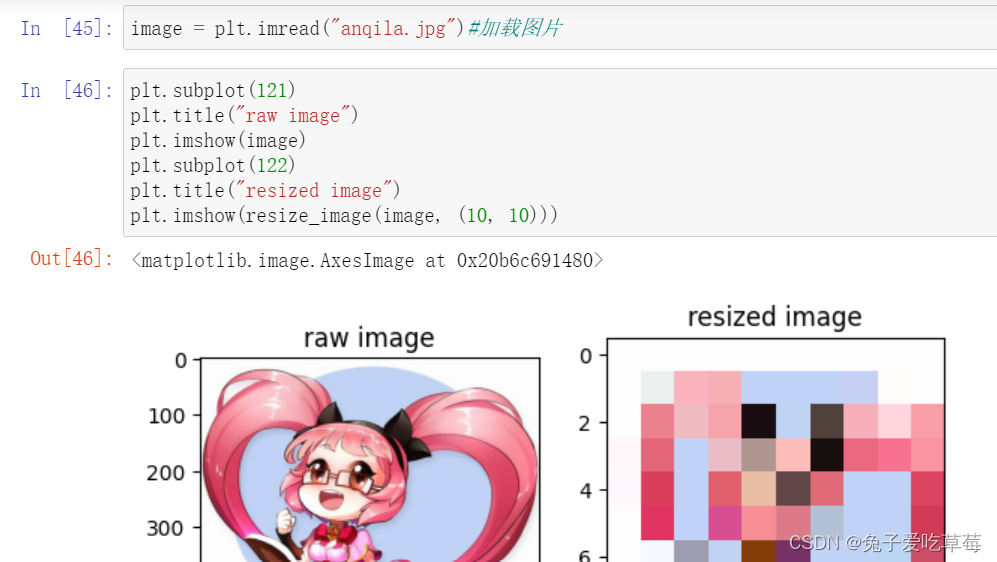
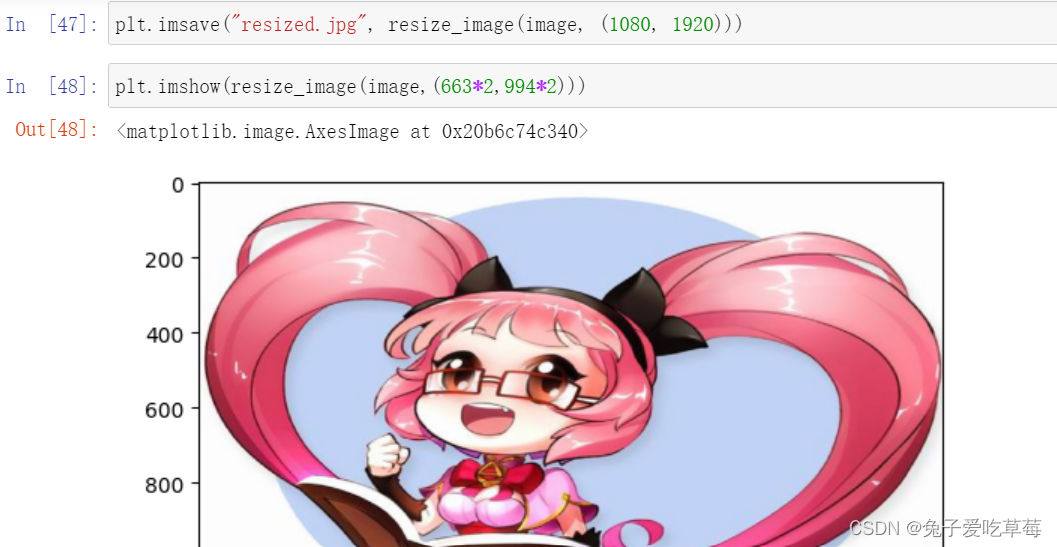
3/图像放大缩小
三/手写全连接
通过修改一部分参数(学习率或批量或epoch)、网络结构、卷积核大小、卷积步长、填零、通道数,以提升精度。


通过更改卷积核大小,卷积核步长达到提升精度的效果。
四/连接板子
这一部分非常繁琐,需要安装许多东西,由于在中间部分环境安装错误,没能成功实现连接到板子。
五/口罩识别
1.环境的配置
本地环境要求
openvino2022.2.0
paddle2onnx1.0.5
paddlepaddle2.4.2
opencv-python4.2.0.32
onnx1.11.0
tensorflow2.9.1
库的安装
pip install openvino-dev[onnx,tensorflow]==2022.2.0
pip install paddle2onnx==1.0.5 -i https://pypi.tuna.tsinghua.edu.cn/simple/
2.数据准备
1.激活安装过labelimg工具的虚拟环境

启动labelimg,为图片打标签,值得注意的是要选择打开图片的文件路径和保存生成的txt文件路径,转化成YOLO格式,每打好一个标签都要记得保存。
2.数据转化
把数据拆成训练集、测试集、验证集,我们为了方便,就只需要拆分成训练集和验证集就可以了。在YOLO2COCO\dataset文件下建立一个yolo_mask文件夹,然后将mask移动到此文件夹下。点击YOLO2COCO获取工具。

编写一个gen.py生产我们需要的train.txt,val.txt
import os
def train_val(labels_path, data_path, ratio=0.3):
nomask_num = 0#计数nomask的数量
mask_num = 0#计数mask的数量
image_dir = "\\".join(data_path.split("\\")[-3:]) + "\\images"#根据yolo2coco要求制定路径
txt_files = os.listdir(labels_path)
f_train = open("train.txt", "w")
f_val = open("val.txt", "w")
m = 0
n = 0
for txt in txt_files:
f_txt = open(os.path.join(labels_path, txt), 'r')#打开txt文件
if f_txt.read()[0] == "0":#读取每个文件的第一行,判断是nomask(0)还是mask(1)
nomask_num += 1#不戴口罩加1
else:
mask_num += 1#戴口罩加1
f_txt.close()
for txt in txt_files:
f_txt = open(os.path.join(labels_path, txt), 'r')
if f_txt.read()[0] == "0":#读取每个文件的第一行,判断是nomask(0)还是mask(1)
n += 1
if n >= int(nomask_num * ratio):
f_train.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
else:
f_val.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
else:
m += 1
if m >= int(mask_num * ratio):
f_train.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
else:
f_val.writelines(image_dir+"\\" + txt.split(".")[0] + ".jpg" + "\n")#往文件里面写路径,记得换行
f_txt.close()
f_train.close()
f_val.close()
if __name__ == "__main__":
data_path = os.path.join(os.getcwd(), 'mask')#获取文件夹mask的绝对路径
labels_path = os.path.join(data_path, "labels")#获取labels文件夹的绝对路径
train_val(labels_path=labels_path, data_path=data_path, ratio=0.3)
接下来可以转换数据了,在YOLO2COCO文件夹下启动cmd
python yolov5_2_coco.py --dir_path E:\paddle_openvino\YOLO2COCO\dataset\yolo_mask
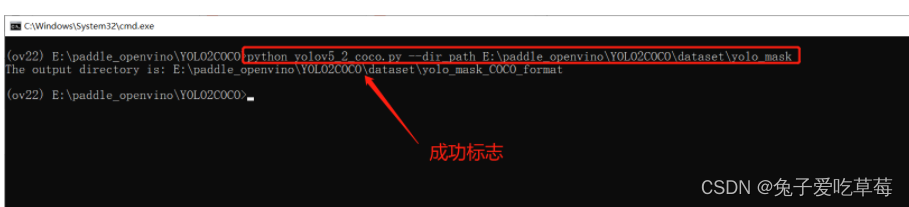
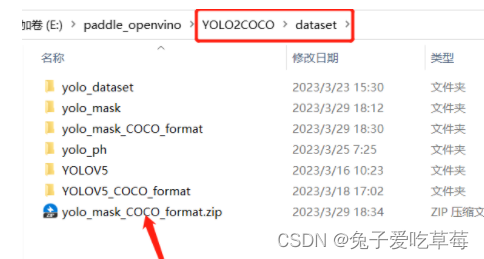
3.模型训练
首先在百度飞桨的AI Studio上上传自己的数据集
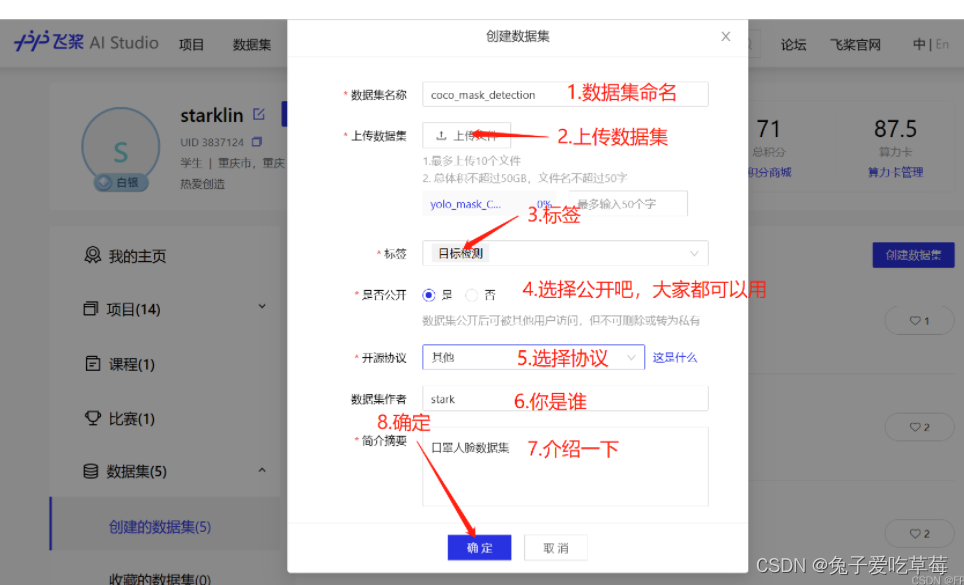
然后创建项目,启动环境
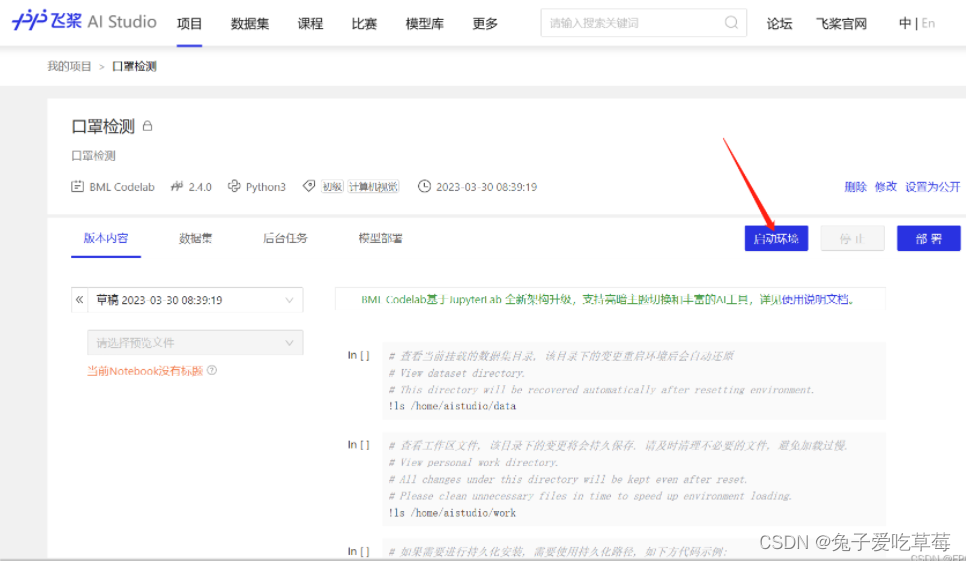
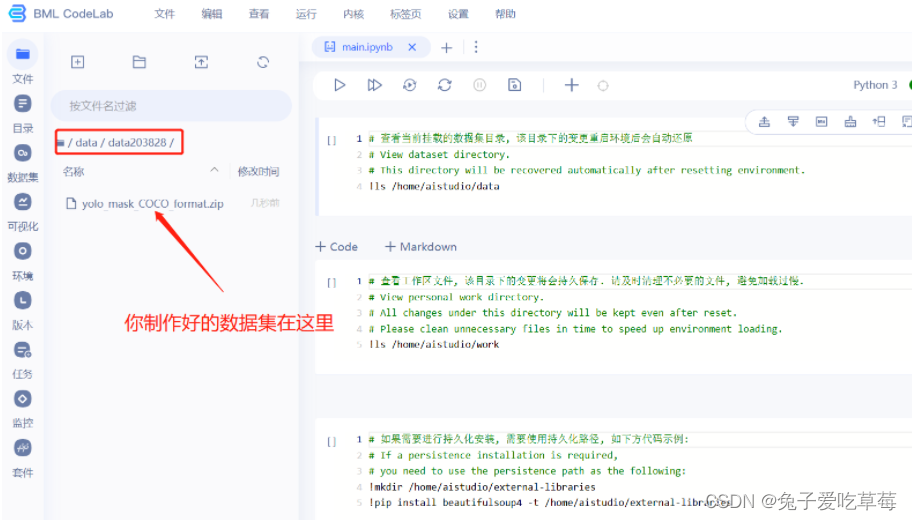
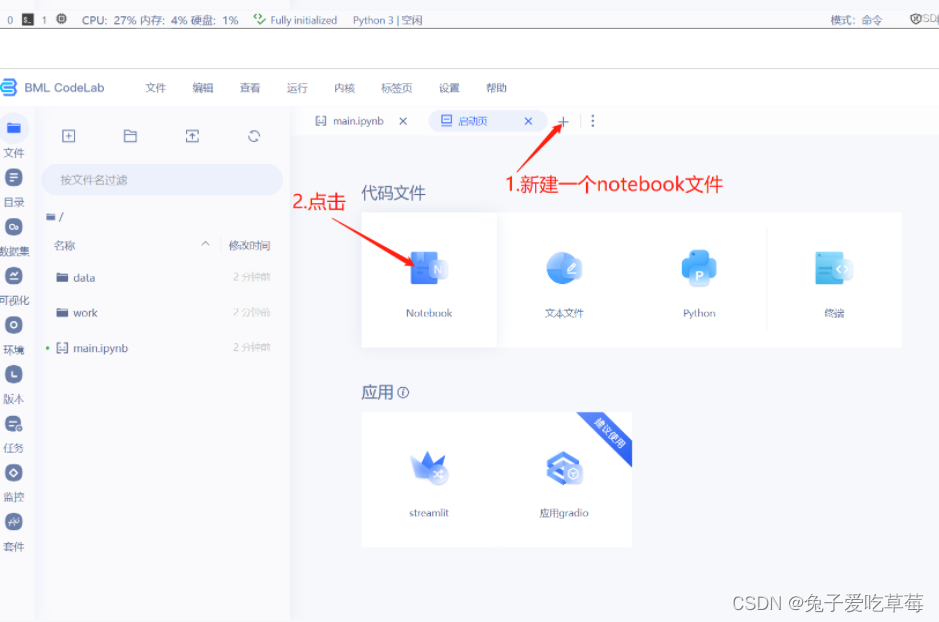
随后进行模型配置,详细配置过程可至https://blog.csdn.net/weixin_43828944/article/details/129850005?spm=1001.2014.3001.5502处查看
4.模型转化
把上一节下载的四个文件打包进ppyoloe_crn_s_80里面
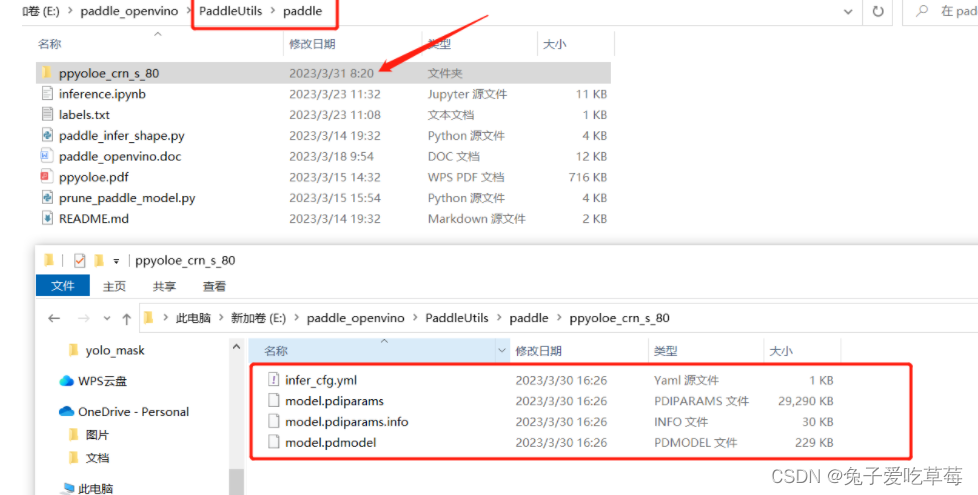
进行模型剪枝,在模型减支工具的paddle目录下打开cmd
运行以下命令
python prune_paddle_model.py --model_dir ppyoloe_crn_s_80 --model_filename model.pdmodel --params_filename model.pdiparams --output_names tmp_16 concat_14.tmp_0 --save_dir export_model
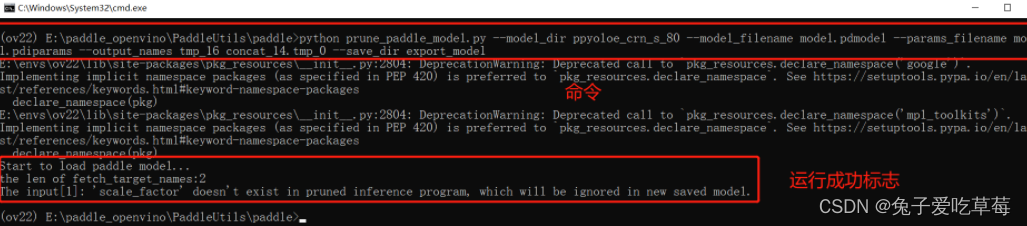
运行过后新增一个减支完成的模型文件夹
然后进行模型转化
先把paddle模型转换为onnx,需要在环境里面提前安装paddle2onnx。执行以下命令
paddle2onnx --model_dir export_model --model_filename model.pdmodel --params_filename model.pdiparams --input_shape_dict "{'image':[1,3,640,640]}" --opset_version 11 --save_file ppyoloe_crn_s_80.onnx
执行生成的ppyoloe_crn_s_80.onnx
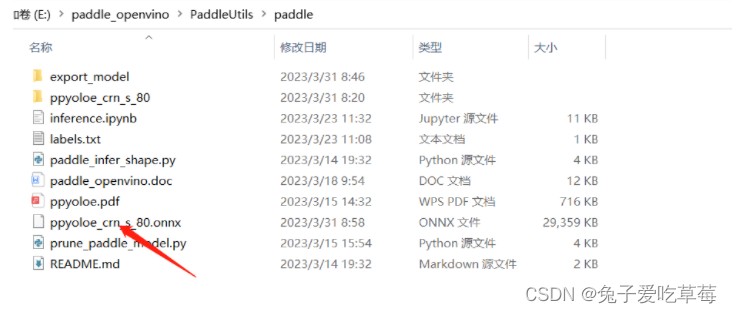
onnx转xml,bin(OpenVINO)
mo --input_model ppyoloe_crn_s_80.onnx

5.模型推理
最后一步进行模型推理,增加一个文件labels.txt,内容是我们的标签,注意放置位置。

推理代码
from openvino.runtime import Core
import openvino.runtime as ov
import cv2 as cv
import numpy as np
import tensorflow as tf
OpenVINO 模型推理器(class)
class Predictor:
"""
OpenVINO 模型推理器
"""
def __init__(self, model_path):
ie_core = Core()
model = ie_core.read_model(model=model_path)
self.compiled_model = ie_core.compile_model(model=model, device_name="CPU")
def get_inputs_name(self, num):
return self.compiled_model.input(num)
def get_outputs_name(self, num):
return self.compiled_model.output(num)
def predict(self, input_data):
return self.compiled_model([input_data])
def get_request(self):
return self.compiled_model.create_infer_request()
图像预处理
在这里插入代码片def process_image(input_image, size):
"""输入图片与处理方法,按照PP-Yoloe模型要求预处理图片数据
Args:
input_image (uint8): 输入图片矩阵
size (int): 模型输入大小
Returns:
float32: 返回处理后的图片矩阵数据
"""
max_len = max(input_image.shape)
img = np.zeros([max_len,max_len,3],np.uint8)
img[0:input_image.shape[0],0:input_image.shape[1]] = input_image # 将图片放到正方形背景中
img = cv.cvtColor(img,cv.COLOR_BGR2RGB) # BGR转RGB
img = cv.resize(img, (size, size), cv.INTER_NEAREST) # 缩放图片
img = np.transpose(img,[2, 0, 1]) # 转换格式
img = img / 255.0 # 归一化
img = np.expand_dims(img,0) # 增加维度
return img.astype(np.float32)
图像后处理
def process_result(box_results, conf_results):
"""按照PP-Yolove模型输出要求,处理数据,非极大值抑制,提取预测结果
Args:
box_results (float32): 预测框预测结果
conf_results (float32): 置信度预测结果
Returns:
float: 预测框
float: 分数
int: 类别
"""
conf_results = np.transpose(conf_results,[0, 2, 1]) # 转置
# 设置输出形状
box_results =box_results.reshape(8400,4)
conf_results = conf_results.reshape(8400,2)
scores = []
classes = []
boxes = []
for i in range(8400):
conf = conf_results[i,:] # 预测分数
score = np.max(conf) # 获取类别
# 筛选较小的预测类别
if score > 0.5:
classes.append(np.argmax(conf))
scores.append(score)
boxes.append(box_results[i,:])
scores = np.array(scores)
boxes = np.array(boxes)
result_box = []
result_score = []
result_class = []
# 非极大值抑制筛选重复的预测结果
if len(boxes) != 0:
# 非极大值抑制结果
indexs = tf.image.non_max_suppression(boxes,scores,len(scores),0.25,0.35)
for i, index in enumerate(indexs):
result_score.append(scores[index])
result_box.append(boxes[index,:])
result_class.append(classes[index])
# 返回结果
return np.array(result_box),np.array(result_score),np.array(result_class)
读取标签
def read_label(label_path):
with open(label_path, 'r') as f:
labels = f.read().split()
return labels
同步推理
label_path = "labels.txt"
yoloe_model_path = "ppyoloe_crn_s_80.xml"
predictor = Predictor(model_path = yoloe_model_path)
boxes_name = predictor.get_outputs_name(0)
conf_name = predictor.get_outputs_name(1)
labels = read_label(label_path=label_path)
cap = cv.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
frame = cv.flip(frame, 180)
cv.namedWindow("MaskDetection", 0) # 0可调大小,注意:窗口名必须imshow里面的一窗口名一直
cv.resizeWindow("MaskDetection", 640, 480) # 设置长和宽
input_frame = process_image(frame, 640)
results = predictor.predict(input_data=input_frame)
boxes, scores, classes = process_result(box_results=results[boxes_name], conf_results=results[conf_name])
result_frame = draw_box(image=frame, boxes=boxes, scores=scores, classes=classes, labels=labels)
cv.imshow('MaskDetection', result_frame)
key = cv.waitKey(1)
if key == 27: #esc退出
break
cap.release()
cv.destroyAllWindows()
异步推理
label_path = "labels.txt"
yoloe_model_path = "ppyoloe_crn_s_80.xml"
predictor = Predictor(model_path = yoloe_model_path)
input_layer = predictor.get_inputs_name(0)
labels = read_label(label_path=label_path)
cap = cv.VideoCapture(0)
curr_request = predictor.get_request()
next_request = predictor.get_request()
ret, frame = cap.read()
curr_frame = process_image(frame, 640)
curr_request.set_tensor(input_layer, ov.Tensor(curr_frame))
curr_request.start_async()
while cap.isOpened():
ret, next_frame = cap.read()
next_frame = cv.flip(next_frame, 180)
cv.namedWindow("MaskDetection", 0) # 0可调大小,注意:窗口名必须imshow里面的一窗口名一直
cv.resizeWindow("MaskDetection", 640, 480) # 设置长和宽
in_frame = process_image(next_frame, 640)
next_request.set_tensor(input_layer, ov.Tensor(in_frame))
next_request.start_async()
if curr_request.wait_for(-1) == 1:
boxes_name = curr_request.get_output_tensor(0).data
conf_name = curr_request.get_output_tensor(1).data
boxes, scores, classes = process_result(box_results=boxes_name, conf_results=conf_name)
frame = draw_box(image=frame, boxes=boxes, scores=scores, classes=classes, labels=labels)
cv.imshow('MaskDetection', frame)
frame = next_frame
curr_request, next_request = next_request, curr_request
key = cv.waitKey(1)
if key == 27: #esc退出
break
cap.release()
cv.destroyAllWindows()
实现成果

六.小结
通过学习卷积神经网络(CNN),我对深度学习有了更深入的理解和应用的能力。首先,我学会了CNN的基本原理和结构,理解了卷积操作的作用和卷积核的作用。我明白了CNN在图像处理中的优势,能够提取出图像的局部特征并进行层级的抽象。
其次,我学会了使用深度学习框架(如TensorFlow或PyTorch)构建和训练CNN模型。我了解了如何选择合适的网络结构、激活函数和优化算法等。我学会了使用数据预处理和数据增强技术来优化模型的性能和泛化能力。
我还学会了使用CNN进行图像分类、目标检测和语义分割等任务。在实践中,我能够应用CNN模型进行图像分类,识别出图像中的物体,并对图像进行像素级的分割。我学到了如何调整模型的超参数和进行模型的调优,以提高模型的准确率和性能。最后通过搭建口罩识别模型,我深入理解了CNN在图像处理中的重要性和有效性。我学会了使用深度学习框架进行模型构建和训练,并掌握了优化算法和评估方法以及口罩识别的实现过程。这些知识和技能对我的机器视觉研究与应用有着重要的指导作用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









