







目录
1.selenium定义
selenium 是浏览器自动化测试框架,原本被用于网页测试。在爬虫领域,selenium 可以控制浏览器,模仿人浏览网页,从而获取数据,自动操作等。
2.安装selenium浏览器驱动器
1)下载、安装驱动器
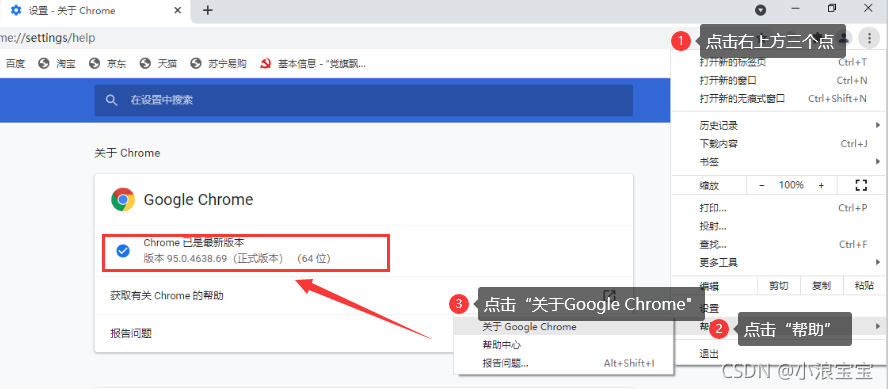
以Chrome浏览器为例,首先打开Chrome浏览器,依次点击浏览器右上角的 三个点——>帮助——>关于Google Chrome。可以看到浏览器的版本信息,如下图所示,我的浏览器版本是95.0.4638.69。
打开 驱动下载地址 ,找到和自己浏览器最接近版本的驱动,Windows系统下载里面的chromedriver_win32.zip 文件,MacOS 下载 chromedriver_mac64.zip 文件。将下载好的chromedriver 解压缩,Windows 系统得到 chromedriver.exe,MacOS 得到 chromedriver 。将驱动器放到 Python 所在安装目录。
如果忘了 Python 的安装目录,在代码编辑器中运行以下代码,可以打印出 Python 所在位置。
import sys
print(sys.executable)输出:
Windows 系统: 2C:\xxx\xxx\python.exe 3MacOS: 4/Users/xxx/xxx/xxx/python
将末尾的\python.exe 或者 /python 去掉,就是 Python所在的目录。可在文件管理器中逐层点进,或者复制到文件管理器的地址栏,直接到该目录,将驱动放到目录中。
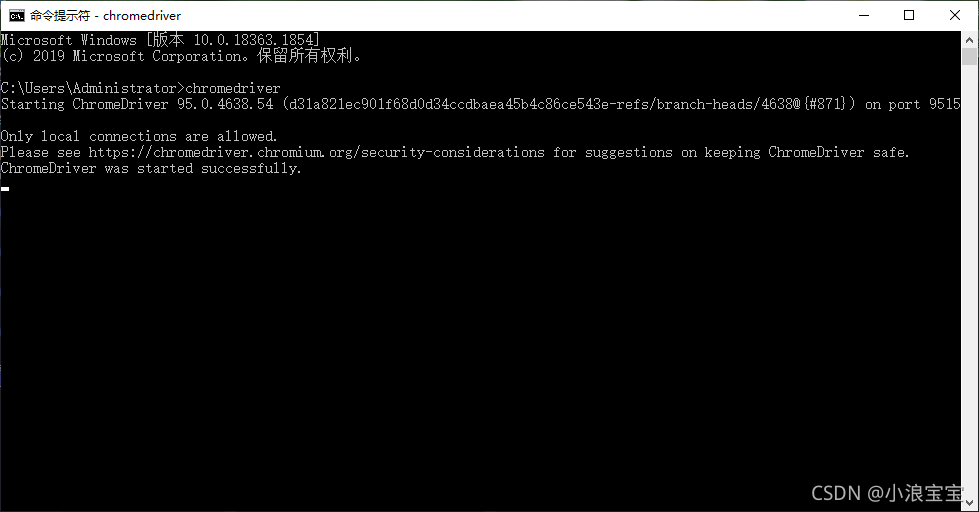
2)检测驱动器
win+cmd+回车,出现命令行,或者在 Anaconda Prompt 输入 chromedriver 命令,MacOS系统在终端中输入 chromedriver 命令。如果出现类似下面所示图片内容,就证明驱动已安装完成。
3.用selenium打开浏览器
# 从 selenium 中导入 webdriver(驱动)
from selenium import webdriver
# 选择 Chrome 浏览器并打开
browser = webdriver.Chrome()运行上面的代码可以,打开现有的Google浏览器,并将实例化的浏览器对象赋值给 browser 变量。
4. 用selenium获取数据
# 从 selenium 中导入 webdriver(驱动)
from selenium import webdriver
#导入time库
import time
#选择 Chrome 浏览器并打开
browser = webdriver.Chrome()
#打开网站,实例为《小浪宝宝博客》网址
browser.get('https://blog.csdn.net/m0_52162042?spm=3001.5343')
print(browser.page_source) #打印网页源代码
time.sleep(2) #延时2s
browser.quit() #关闭Chrome 浏览器
browser 是实例化的浏览器,将网站传给 browser 对象的 get() 方法,即可打开对应的网址。用 browser 对象的 page_source 属性获取网页的源代码,并且用 selenium 获取的网页原地阿玛是数据加载完毕最终的源代码,网页加载后通过 API 获取的数据也在源代码中。最后 quit() 方法关闭浏览器。time.sleep()是为了确保将网页加载完全,单位是秒。
| 代码 | 作用 |
| browser = webdriver.Chrome() | 打开 Chrome 浏览器 |
| browser.get(‘网址’) | 打开网页 |
| browser.page_source | 获取网页源代码 |
| browser.quit() | 关闭浏览器 |
5.用selenium处理数据
| 方法 | 作用 |
|---|---|
| find_element_by_tag_name | 通过标签查找元素 |
| find_element_by_class_name | 通过 class 属性查找元素 |
| find_element_by_id | 通过 id 查找元素 |
| find_element_by_name | 通过 name 属性查找元素 |
| find_element_by_link_text | 通过链接文本查找元素 |
| find_element_by_partial_link_text | 通过链接的部分文本查找元素 |
这些方法找到的元素(返回值)都是 WebElement 对象,它和 BeautifulSoup 里的Tag 对象一样,也有 text 属性,都可以获取元素里的文本内容。不同的是, Tag 对象 通过字典取值的方式获取元素的属性值,而 WebElement 对象则使用 get_attribute() 方法来获取。如果想获取所有符合条件的元素,只要将上面方法中的 element 改为 elements。
| 方法 | 作用 |
| WebElement.text | 获取元素文本内容 |
| WebElement.get_attribute('属性名') | 获取元素属性值 |
在获取数据时,也可以将 selenium 和 BeautifulSoup 结合起来,因为 selenium 方法page_resource 获取的网页源代码是字符串形式,和 requests 库获取网页源代码,通过 text 属性获取形式相同。
6.用selenium控制浏览器
| 方法 | 作用 |
| click() | 点击元素 |
| send_keys() | 模拟按键输入 |
通过 selenium 查找元素的方法找到对应的元素后,调用 click() 方法,可以模拟点击该元素,一般用于点击链接或者按钮;调用 send_keys() 方法用于模拟按键输入,常用于账号密码等输入框架的表单填写。
深入学习 selenium 可以参考网址:Selenium 中文文档















 638
638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











