







概念
哈夫曼树,也叫最优二叉树。在含有给定的n个带权叶子结点的二叉树中,WPL最小的树。其中,结点的权指的是某种特定含义的数值;带权路径长度值根到结点的路径长度乘以结点权值;树的带权路径长度(WPL)是指树中所有叶子结点的带权路径长度之和。
构造
根据哈夫曼算法,叙述如下:
1.根据给定的n个权值{w1,w2,…,wn}构成的n棵二叉树集合F={T1,T2,…,Tn},其中每棵二叉树Ti中只有一个带权为wi的根结点,其左右子树均为空。
2.在F中选取两棵根结点权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左右子树上的根结点的权值之和。
3.在F中删除这两棵树,同时将新得到的二叉树加入到F中。
4.重复(2)和(3),知道F只含有一棵树为止。则这棵树便是哈夫曼树。
其中关键步骤是,每次选两个根结点权值最小的树合并,并将两者的权值之和作为新的根结点的权值。而从哈夫曼算法可以看到,哈夫曼树不唯一,但WPL必是最小值。
如下图所示,给出ABCDEF六个字符,字符下方标出了各自所占的权值,通过上面的算法一步步得出哈夫曼树:
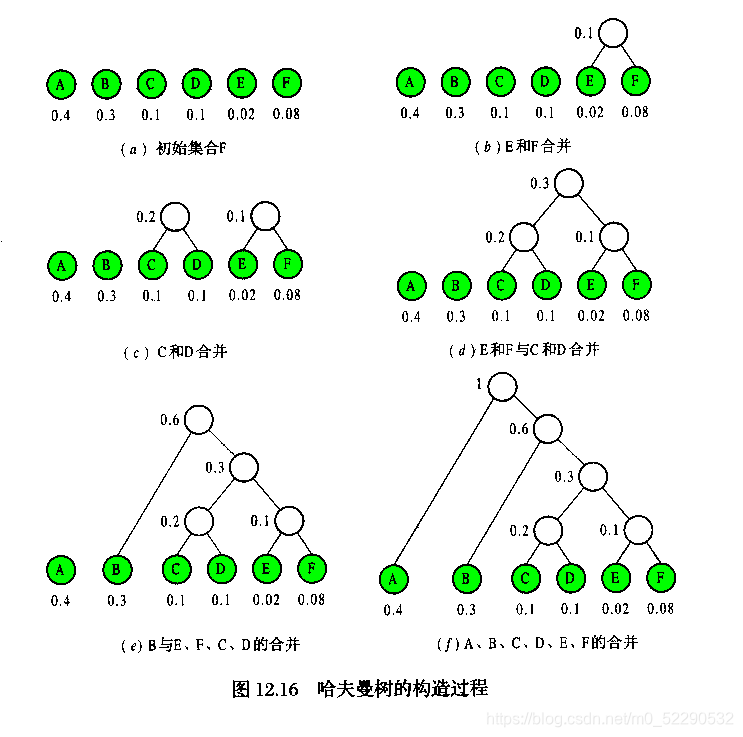
哈夫曼编码
哈夫曼树有什么用?根据哈夫曼树,我们可以得到哈夫曼编码。哈夫曼编码是可变字长编码的一种形式,该编码依照字符出现频率来构造平均长度最短的码字,有时也叫做最佳编码。
例如,英文当中有26个英文字母,每个字母出现的频率是不一样的:
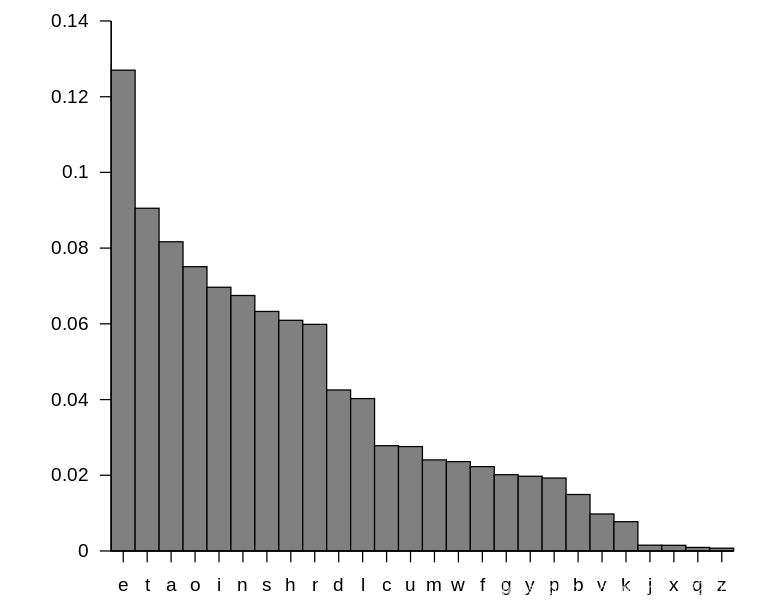
如果采用常规的固定编码,每个字符所对应的二进制编码可能会更加容易表示出来,但是在实际上,所造成的负面作用是显而易见的,那就是句子冗长。进行快速远距离通信的主要手段是电报,即将需要传送的文字转换成二进制的字符组成的字符串。在传送电文时,总长应尽可能的短,这样传递更有效率。尤其是在传递大量信息,或是关键情报时,电报的长度就显得十分重要。所以,哈夫曼编码就专门处理这类问题,首先根据字符出现的频率分配权值,构造哈夫曼树,得到哈夫曼编码的方式十分简单,我们在哈夫曼树的每一个左分支上注“0”,右分支上注“1”,从根结点走到一个叶子结点,得到一组二进制序列,这个序列就是就是该叶子结点对应字符的哈夫曼编码。
如何利用代码具体实现为给定权值的字符编码?下面通过例子来说一下大致流程:假定一个通信系统中只可能出现8种字符,其概率分别为0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11,试设计哈夫曼代码。
首先我们利用动态分配数组存储哈夫曼树,该数组的每一个元素表示这样一个结构体,它存放哈夫曼树中一个结点的信息:即权值、双亲结点、左孩子、右孩子的位置(及数组的下标)。那么,在本例中,我们有8个待编码的字符,根据哈夫曼树的性质可知,我们应该构建2*8-1=15个结点的哈夫曼树,即定义一个存放15个结构体的数组。我们应该给哈夫曼树中每一个叶子结点赋权值,然后其他数据域赋无效值。那么对于本题,应对数组中下标为1到8的元素权值域赋值,其他数据域赋0,对于下标8到15的元素所有数据域均赋值为0,对应图a。
之后构建哈夫曼树,在之前的算法描述中,我们可以知道,应将两个权值最小的结点合并,并将两者的权值之和作为新的根结点的权值。那么具体到这个题目来说,举例说明。第一次时,先扫描数组前8个结点,选择两个权值最小的结点,将它们的双亲域置为9,意思是数组下标为9的地方存放这两个结点的双亲结点,左、右孩子域仍为0(因为这两个结点是叶子结点)。然后将它们的双亲结点(即数组下标为9的结点)的左、右孩子域分别置为那两个权值最小的结点所在的数组下标,并将该结点的权值域设置为那两个权值最小的结点的权值域之和,第一次构建就完成了。我们应通过适当的循环来重复这一过程,直到构建出一个完整的哈夫曼树,最终构建完如图b。
构建好哈夫曼树之后,就可以求哈夫曼编码。同之前一样,动态分配数组存储哈夫曼编码表,这个数组的每一个元素是char*类型,即每一个元素存储一个字符串。通过循环,每一次从不同叶子到根逆向求编码,遵循之前提到的左0右1原则,每次构建出一个叶子结点的编码,通过strcpy函数将结果拷贝到之前的数组当中,该操作对应图c。

附录:代码
输入待编码字符数目,输入对应待编码字符的权值,我们就可以得到每个字符的哈夫曼编码。下面是整体代码:
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define OVERFLOW -1
typedef struct {
unsigned int weight;//权重
unsigned int partent, lchild, rchild;
}HTNode,* HuffmanTree;
typedef int Status;
typedef char** HuffmanCode;
void Select(HuffmanTree* HT, int n, int* s1, int* s2) {
int i;
unsigned int min = 9999;
int temp1 = 0, temp2 = 0;
for (i = 1;i <= n;i++) {
if ((*HT)[i].partent == 0 && (*HT)[i].weight < min) {
min = (*HT)[i].weight;
temp1 = i;
}
}
*s1 = temp1;
min = 9999;
for (i = 1;i <= n;i++) {
if ((*HT)[i].partent == 0 && (*HT)[i].weight < min && temp1 != i) {
min = (*HT)[i].weight;
temp2 = i;
}
}
*s2 = temp2;
}
void HuffmanCoding(HuffmanTree* HT, HuffmanCode* HC, int w[], int n) {
//w存放n个字符的权值(均>0),构造哈夫曼树HT,并求出n个字符的哈夫曼编码HC。
if (n <= 1)return;
int m = 2 * n - 1;
(*HT) = (HuffmanTree)malloc((m + 1) * sizeof(HTNode));
if (!(*HT))exit(OVERFLOW);
int i;
for (i = 1;i <= n;++i) {
(*HT)[i].weight = w[i];//权值
(*HT)[i].partent = 0;
(*HT)[i].lchild = 0;
(*HT)[i].rchild = 0;
}
for (i=n+1;i <= m;++i) {
(*HT)[i].weight = 0;
(*HT)[i].partent = 0;
(*HT)[i].lchild = 0;
(*HT)[i].rchild = 0;
}
int s1, s2;
for (i = n + 1;i <= m;++i) { //建哈夫曼树
//在HT[1...i-1]选择parent为0且weight最小的两个结点,其序号分别为s1和s2
Select(HT, i - 1, &s1, &s2);
(*HT)[s1].partent = i;(*HT)[s2].partent = i;
(*HT)[i].lchild = s1;(*HT)[i].rchild = s2;
(*HT)[i].weight = (*HT)[s1].weight + (*HT)[s2].weight;
}
//---从叶子到根逆向求每个字符的哈夫曼编码---
(*HC) = (HuffmanCode)malloc((n + 1) * sizeof(char*));
if (!(*HC))exit(OVERFLOW);
char* cd = (char*)malloc(n * sizeof(char));
if (!cd)exit(OVERFLOW);
cd[n - 1] = '\0';
for (int i = 1;i <= n;++i) {
int start = n - 1;
int f = 0;
for (int c = i, f = (*HT)[i].partent;f != 0;c = f, f = (*HT)[f].partent)
if ((*HT)[f].lchild == c)cd[--start] = '0';
else cd[--start] = '1';
(*HC)[i] = (char*)malloc((n - start) * sizeof(char));
if (!(*HC)[i])exit(OVERFLOW);
strcpy((*HC)[i], &cd[start]);
}
free(cd);
}
void main() {
HuffmanTree HT;
HuffmanCode HC;
printf("请输入待编码字符个数:");
int n;
scanf_s("%d", &n);
int w[100];
printf("请输入对应字符的权值:");
for (int i = 1;i <= n;i++) {
scanf_s("%d", &w[i]);
}
HuffmanCoding(&HT, &HC, w, n);
for (int i = 1;i <= 2 * n - 1;i++) {
printf("%d:\t%d\t%d\t%d\t%d\n", i, HT[i].weight, HT[i].partent, HT[i].lchild, HT[i].rchild);
}
for (int i = 1;i <= n;i++) {
printf("权值为%d的哈夫曼编码:%s\n", w[i],HC[i]);
}
}














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









