







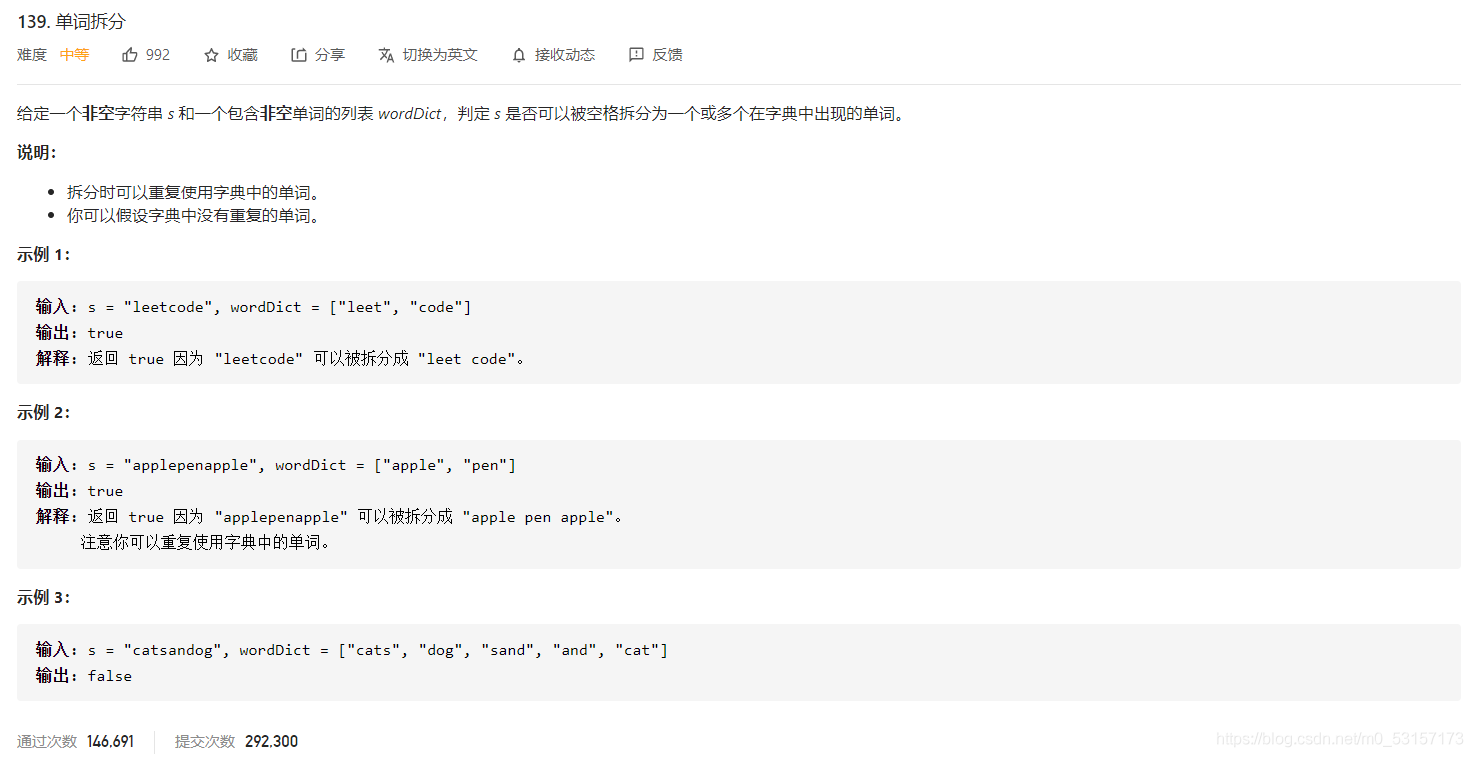
单词拆分题解集合
动态规划
单词就是物品,字符串s就是背包,单词能否组成字符串s,就是问物品能不能把背包装满。
拆分时可以重复使用字典中的单词,说明就是一个完全背包!
动规五部曲分析如下:
1.确定dp数组及其下标的含义
dp[i] : 字符串长度为i的话,dp[i]为true,表示可以拆分为一个或多个在字典中出现的单词。
2.确定递推公式
如果确定dp[j] 是true,且 [j, i] 这个区间的子串出现在字典里,那么dp[i]一定是true。(j < i )。
所以递推公式是 if([j, i] 这个区间的子串出现在字典里 && dp[j]是true) 那么 dp[i] = true。
3.dp数组如何初始化
从递归公式中可以看出,dp[i] 的状态依靠 dp[j]是否为true,那么dp[0]就是递归的根基,dp[0]一定要为true,否则递归下去后面都都是false了。
那么dp[0]有没有意义呢?
dp[0]表示如果字符串为空的话,说明出现在字典里。
但题目中说了“给定一个非空字符串 s” 所以测试数据中不会出现i为0的情况,那么dp[0]初始为true完全就是为了推导公式。
下标非0的dp[i]初始化为false,只要没有被覆盖说明都是不可拆分为一个或多个在字典中出现的单词。
4.确定遍历顺序
题目中说是拆分为一个或多个在字典中出现的单词,所以这是完全背包。
还要讨论两层for循环的前后循序。
如果求组合数就是外层for循环遍历物品,内层for遍历背包。
如果求排列数就是外层for遍历背包,内层for循环遍历物品。
本题最终要求的是是否都出现过,所以对出现单词集合里的元素是组合还是排列,并不在意!
那么本题使用求排列的方式,还是求组合的方式都可以。
即:外层for循环遍历物品,内层for遍历背包 或者 外层for遍历背包,内层for循环遍历物品 都是可以的。
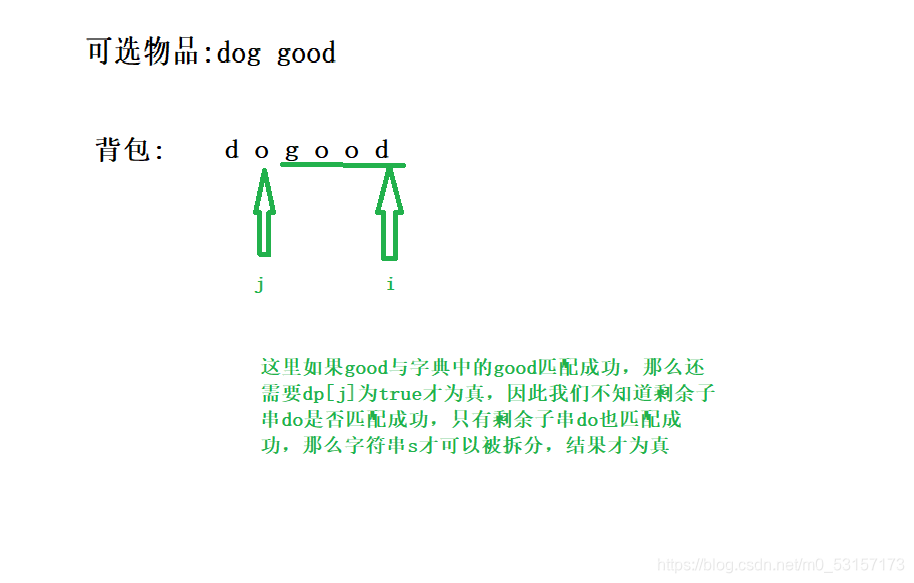
但本题还有特殊性,因为是要求子串,最好是遍历背包放在外循环,将遍历物品放在内循环。
如果要是外层for循环遍历物品,内层for遍历背包,就需要把所有的子串都预先放在一个容器里。(如果不理解的话,可以自己尝试这么写一写就理解了)
所以最终我选择的遍历顺序为:遍历背包放在外循环,将遍历物品放在内循环。内循环从前到后。
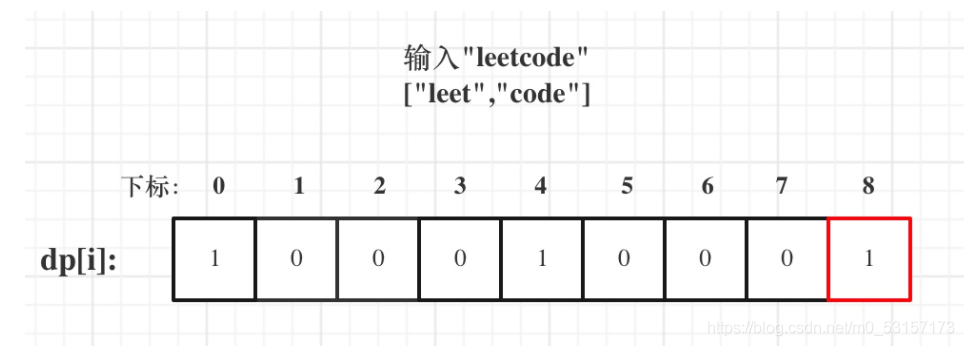
5.举例推导dp[i]
以输入: s = “leetcode”, wordDict = [“leet”, “code”]为例,dp状态如图:
代码:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict)
{
int objNum = wordDict.size();
int Size = s.size();
vector<bool> dp(Size + 1, false);
dp[0] = true;
for (int i = 1; i <= Size; i++)// 遍历背包
{
for (int j = 0; j <i; j++) // 遍历物品
{
string word = s.substr(j, i - j);//获取所有可能的子串,去字典中找,看能否出现匹配
if (find(wordDict.begin(), wordDict.end(), word) != wordDict.end() && dp[j] == true)
dp[i] = true;
}
}
return dp[Size];
}
};
记忆化搜索
思路:
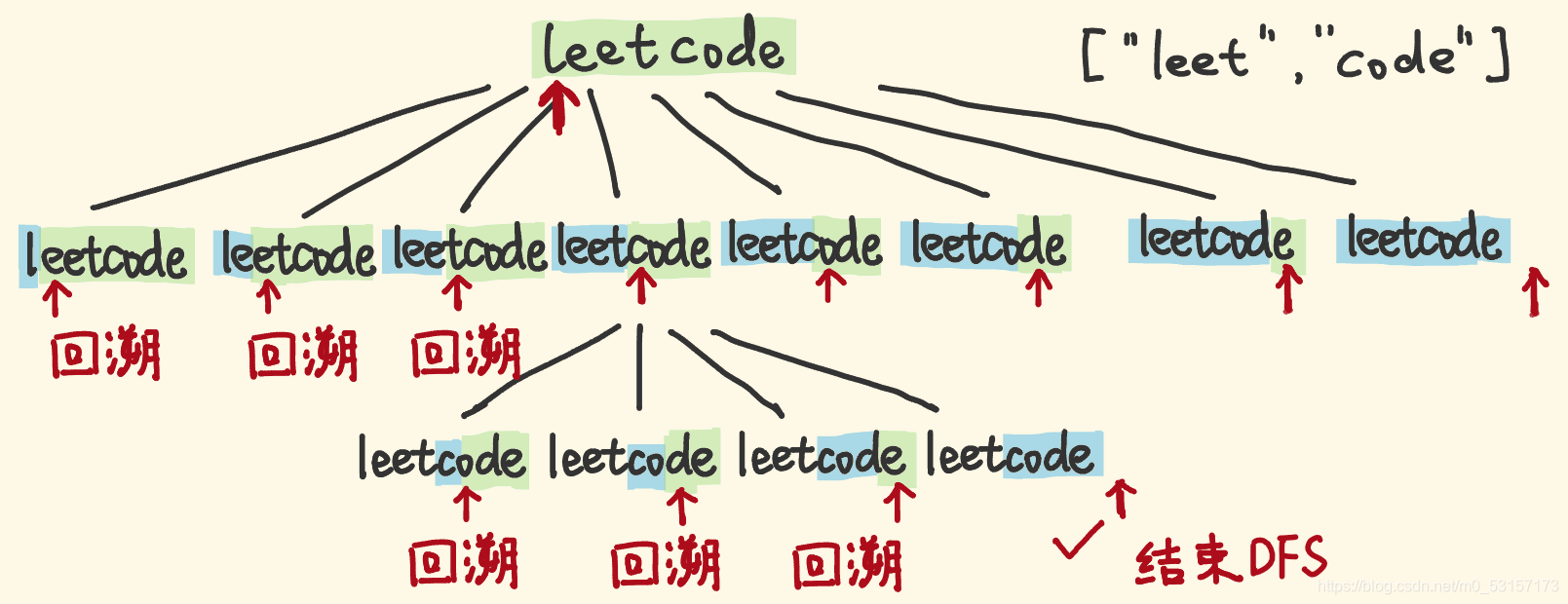
- "leetcode"能否 break,可以拆分为:
- "l"是否是单词表的单词、剩余子串能否 break。
- "le"是否是单词表的单词、剩余子串能否 break。
- “lee”…以此类推…
- 用 DFS 回溯,考察所有的拆分可能,指针从左往右扫描:
- 如果指针的左侧部分是单词,则对剩余子串递归考察。
- 如果指针的左侧部分不是单词,不用看了,回溯,考察别的分支。
加入记忆化
-
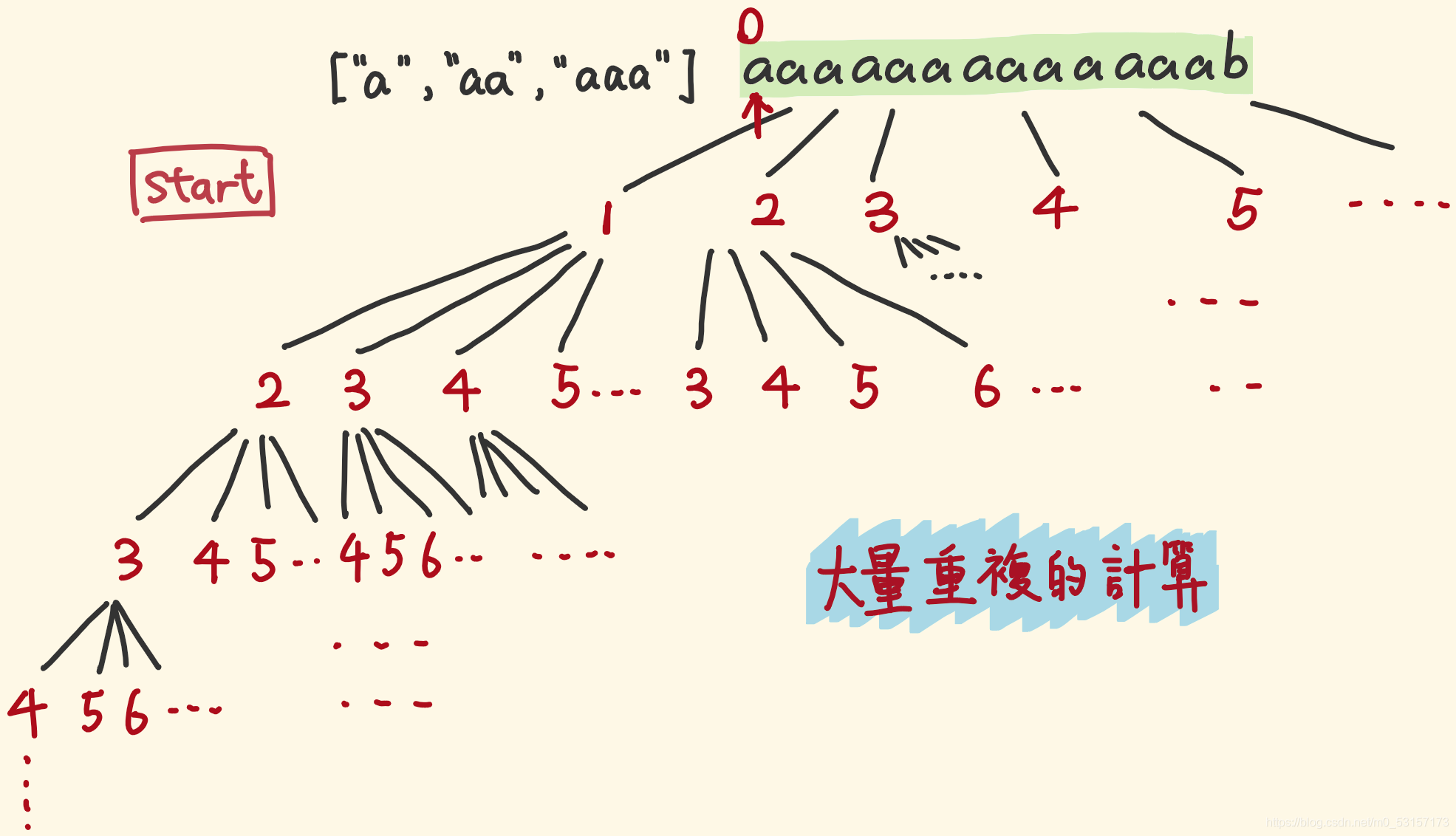
下面这个例子中,start 指针代表了节点的状态,可以看到,做了大量重复计算:
-
用一个数组,存储计算的结果,数组索引为指针位置,值为计算的结果。下次遇到相同的子问题,直接返回数组中的缓存值,就不用进入重复的递归。
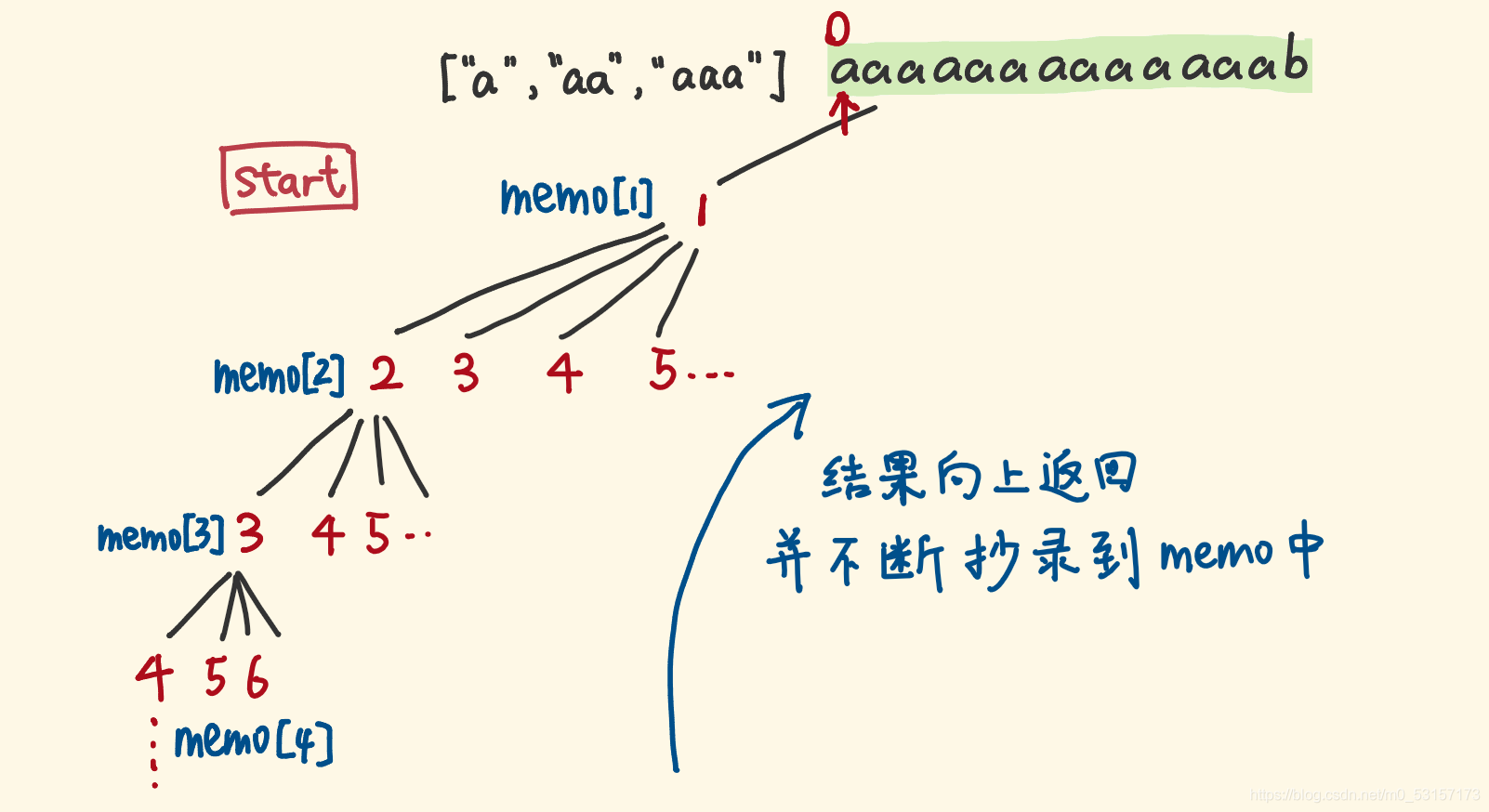
这里递归结束的条件就是当前已经匹配好的字符个数等于当前字符串s的长度
代码:
class Solution {
unordered_map<int,bool> cache;//保存当前子串的匹配结果
int size;//字符串s的长度
string S;
vector<string> word;
public:
bool wordBreak(string s, vector<string>& wordDict)
{
size = s.size();
S = s;
word = wordDict;
return dfs(0);
}
bool dfs(int start)//匹配成功的字符个数,同样也是当前匹配的起点,前面是已经匹配好的
{
if (cache.find(start) != cache.end()) return cache[start];
if (start == size)
return true;
//遍历所有分支,即遍历字符串s的所有子串
for (int i =start; i <size; i++)
{
//获取当前子串
string sub = S.substr(start,i-start+1);
//这里dfs(i)返回真,说明字符串s从i位置开始到字符串结束第已经完成了匹配
//并且这里start--i-1,字符串开始位置到i-1也完成了匹配
if (find(word.begin(), word.end(), sub) != word.end() && dfs(i+1))
{
cache[start] = true;
return true;
}
}
cache[start] = false;
return false;
}
};
BFS
- 刚才我们用DFS遍历空间树,当然也能用BFS。
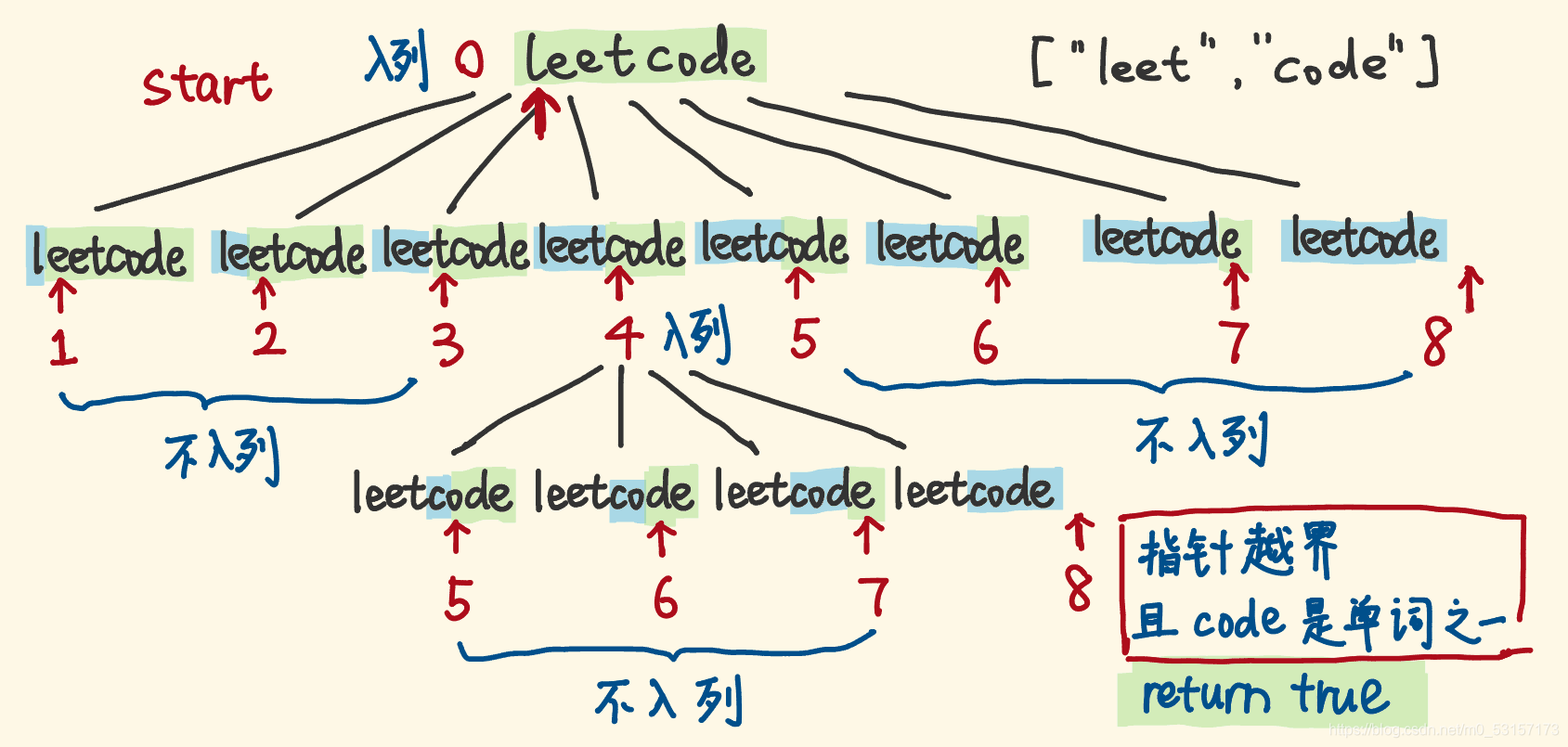
- 维护一个队列,依然用指针描述一个节点,依旧考察指针。
- 起初,指针 0 入列,然后它出列,指针 1,2,3,4,5,6,7,8 就是它的子节点,分别与 0 围出前缀子串,如果不是单词,对应的指针就不入列,否则入列,继续考察以它为起点的剩余子串。
- 然后重复:节点(指针)出列,考察它的子节点,能入列的就入列、再出列……
- 直到指针越界,没有剩余子串了,没有指针可入列,如果前缀子串是单词,说明之前一直在切出单词,返回 true。
- 如果整个BFS过程,始终没有返回true,则返回 false。
代码:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict)
{
queue<int> q;//队列中存放的是下一次在s中切割的起点
q.push(0);//初始切割起点为0
while (!q.empty())
{
//获取当前切割起点
int start = q.front();
q.pop();
// i指针去划分两部分
for (int i = start; i <=s.size(); i++)
{
// 切出前缀部分
string sub = s.substr(start,i-start+1);
// 前缀部分是单词
if (find(wordDict.begin(), wordDict.end(), sub) != wordDict.end())
{
// i还没越界,还能继续划分,让它入列,作为下一层待考察的节点
if (i < s.size())
q.push(i+1);
else
// i==len,指针越界,说明s串一路被切出单词,现在没有剩余子串,返回true
return true;
}
// 前缀部分不是单词,这个 i 指针不入列,继续下轮迭代,切出下一个前缀部分,再试
}
}
// BFS完所有节点(考察了所有划分的可能)都没返回true,则返回false
return false;
}
};
BFS 避免访问重复的节点
未剪枝的DFS会重复遍历节点,BFS也一样。思考一下超时的case,BFS是如何重复访问节点。
解决:用一个 visited 数组记录访问过的节点,出列考察一个指针时,存在于 visited 就跳过,否则将它存入 visited。
代码:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict)
{
unordered_set<int> set;
queue<int> q;//队列中存放的是下一次在s中切割的起点
q.push(0);//初始切割起点为0
while (!q.empty())
{
//获取当前切割起点
int start = q.front();
q.pop();
//是访问过的就直接跳过
if (set.find(start) != set.end())
continue;
set.insert(start);
// i指针去划分两部分
for (int i = start; i <=s.size(); i++)
{
// 切出前缀部分
string sub = s.substr(start,i-start+1);
// 前缀部分是单词
if (find(wordDict.begin(), wordDict.end(), sub) != wordDict.end())
{
// i还没越界,还能继续划分,让它入列,作为下一层待考察的节点
if (i < s.size())
q.push(i+1);
else
// i==len,指针越界,说明s串一路被切出单词,现在没有剩余子串,返回true
return true;
}
// 前缀部分不是单词,这个 i 指针不入列,继续下轮迭代,切出下一个前缀部分,再试
}
}
// BFS完所有节点(考察了所有划分的可能)都没返回true,则返回false
return false;
}
};














 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









