






 AST-Trans是一种针对代码摘要的新型方法,通过高效利用AST中的祖先关系和兄弟关系,降低了计算复杂度。它通过动态权重分配和排除无关节点,改进了基于Transformer的编码器-解码器架构,提高了处理大型AST时的效率。实验结果显示,AST-Trans在多个评估指标上优于现有基线方法。
AST-Trans是一种针对代码摘要的新型方法,通过高效利用AST中的祖先关系和兄弟关系,降低了计算复杂度。它通过动态权重分配和排除无关节点,改进了基于Transformer的编码器-解码器架构,提高了处理大型AST时的效率。实验结果显示,AST-Trans在多个评估指标上优于现有基线方法。
文章目录
AST-Trans: Code Summarization with Efficient Tree-Structured Attention
原文链接:https://ieeexplore.ieee.org/document/9794079
摘要
代码摘要旨在为源代码生成简短的自然语言描述,最先进的方法遵循基于变压器的编码器-解码器架构,抽象语法树(AST)被广泛用于编码结构信息。然而,AST一般而言很大,由于每个节点都需要对AST中的所有其他节点计算self-attention,因此这也会导致大量的计算开销。
现有的方法忽略了尺寸约束,并简单地将整个线性化AST馈送到编码器中,这样一个简单的过程很难从过长的输入序列中提取真正有用的依赖关系。
本文中提出了AST-Trans,它利用了AST中的两种类型的节点关系:祖先关系和兄弟关系,为相关节点动态分配权重,并基于这两种关系排除无关节点。
介绍
背景:代码摘要能够帮助程序员快速消化代码,而不用自己遍历代码,然而,维护高质量的代码摘要实际上需要昂贵的人工。在许多项目中,这些总结往往不匹配、缺失或过时,从而减缓了开发进度,自动代码摘要可以大大节省开发人员的时间。
AST通常通过不同的算法进行线性化,如先序遍历、基于结构的遍历、路径分解等,然而,线性化的AST由于包含额外的结构化信息,比其相应的源代码序列长得多,这使得模型极难从过长的输入序列中准确地检测有用的依赖关系,且来大量的计算开销。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pPslb7w8-1678689110365)(C:\Users\28413\AppData\Roaming\Typora\typora-user-images\image-20230128180738066.png)]](https://i-blog.csdnimg.cn/blog_migrate/e02b3ba41aab2c91cc00ca04e58d04cc.png)
假设受其祖先节点和兄弟节点的影响最大,如上图所示,祖先节点代表层次关系,兄弟节点代表块内关系。捕获这两个信息就足以生成摘要,而不需要在所有节点之间建立self-attention。
普通线性AST树的时间复杂度是 O ( n 2 ) O(n^2) O(n2),本文提出的复杂度为 O ( n ) O(n) O(n)。
AST-TRAN
这节将利用AST树生成祖先关系矩阵和兄弟关系矩阵,取代原有的自我注意力,并动态排除无关节点降低计算成本。
AST 线性化
为了对树形AST进行编码,首先需要使用线性化方法将其转换为序列。当前工程中使用的三种最具代表性的线性化方法:
- 先序遍历(POT):这种方法会损失原有的AST信息,不能利用先序遍历还原出原来的AST树。
- 结构遍历(SBT):添加了额外的括号来表征父子关系,这样可以利用这些有序对还原出AST,但是线性化序列大小增倍。
- 路径分解(PD):通过连接两个随机叶节点之间的路径来表示AST。路径的总数对于计算来说可能太大,因此需要随机采样。
下表展示了这几种遍历方式的结果

关系矩阵
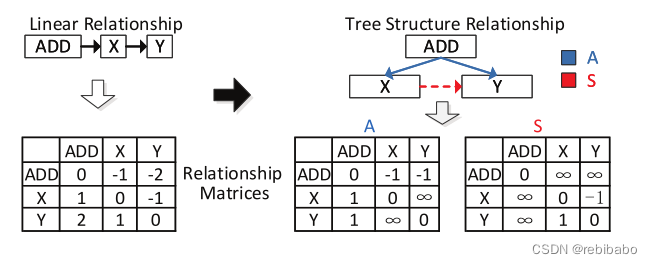
定义了两种我们关心的节点之间的关系:祖先关系A和兄弟关系S,维度都是 N × N N\times N N×N,N为节点个数。假定在线性AST树(先序遍历)中的第i个节点为 n i n_i ni, A i j A_{ij} Aij 表示两节点 n i , n j n_i,n_j ni,nj之间最短路径的长度, S i j S_{ij} Sij表示两兄弟节点之间的水平距离,如果不满足这些关系,用Inf无穷大表示。
更准确的表示形式如下,其中SPD和SID分别表示到根节点的最短路径和兄弟节点之间的水平距离。
A
i
j
=
{
S
P
D
(
i
,
j
)
if
∣
S
P
D
(
i
,
j
)
∣
≤
P
∞
otherwise
S
i
j
=
{
S
I
D
(
i
,
j
)
if
∣
S
I
D
(
i
,
j
)
∣
≤
P
∞
otherwise
(
1
)
\begin{aligned} & A_{i j}=\left\{\begin{aligned} \mathbf{SPD}(i, j) & \text { if }|\mathbf{S P D}(i, j)| \leq P \\ \infty & \text { otherwise } \end{aligned}\right. \\ & S_{i j}=\left\{\begin{aligned} \mathbf{S I D}(i, j) & \text { if }|\mathbf{S I D}(i, j)| \leq P \\ \infty & \text { otherwise } \end{aligned}\right. \end{aligned}\qquad\qquad(1)
Aij={SPD(i,j)∞ if ∣SPD(i,j)∣≤P otherwise Sij={SID(i,j)∞ if ∣SID(i,j)∣≤P otherwise (1)
P是预先定义的阈值,如果距离大于这个值则被忽略,这假设了一定距离之外的节点,它们的关系是无用的,可以降低计算复杂度。
下图展示了这两个矩阵的例子,距离是有方向的
树形结构注意力
self-attention:对于标准的自注意力,假定输入为
x
=
(
x
1
,
⋯
,
x
n
)
\mathbf{x}=(x_1,\cdots,x_n)
x=(x1,⋯,xn), 其中
x
i
∈
R
d
x_i\in \R^d
xi∈Rd,是嵌入向量,输出矩阵
o
=
(
o
1
,
⋯
,
o
n
)
,
o
i
∈
R
d
\mathbf o = (o_1,\cdots,o_n),o_i\in \R^d
o=(o1,⋯,on),oi∈Rd,公式如下
α
i
j
=
Q
(
x
i
)
K
(
x
j
)
⊤
d
o
i
=
∑
j
=
1
n
σ
(
α
i
j
)
V
(
x
j
)
(
2
)
\begin{aligned} \boldsymbol{\alpha}_{i j} & =\frac{Q\left(x_i\right) \boldsymbol{K}\left(x_j\right)^{\top}}{\sqrt{d}} \\ o_i & =\sum_{j=1}^n \sigma\left(\boldsymbol{\alpha}_{i j}\right) \boldsymbol{V}\left(x_j\right) \end{aligned}\qquad\qquad\qquad\qquad(2)
αijoi=dQ(xi)K(xj)⊤=j=1∑nσ(αij)V(xj)(2)
其中 Q、K表示query函数和key函数,都是
R
d
→
R
m
\R^d\rightarrow\R^m
Rd→Rm,V 时value函数,
R
d
→
R
d
\R^d\rightarrow\R^d
Rd→Rd,
σ
\sigma
σ 是得分函数(softmax)。
Relative position embedding:上面的等式没有任何位置信息的,而相对位置嵌入在代码摘要任务中显示出更有效,相对位置
δ
(
i
,
j
)
\delta(i,j)
δ(i,j)反应了节点
n
i
,
n
j
n_i,n_j
ni,nj 之间的相对距离,假设P是最大的相对距离,则
δ
(
i
,
j
)
\delta(i,j)
δ(i,j) 有如下定义
δ
(
i
,
j
)
=
{
0
for
i
−
j
≤
−
P
2
P
for
i
−
j
≥
P
i
−
j
+
P
others.
(
3
)
\delta(i, j)=\left\{\begin{array}{rll} 0 & \text { for } & i-j \leq-P \\ 2 P & \text { for } & i-j \geq P \\ i-j+P & \text { others. } & \end{array}\right.\qquad(3)
δ(i,j)=⎩
⎨
⎧02Pi−j+P for for others. i−j≤−Pi−j≥P(3)
通过这种方式,我们可以将每个相对距离映射到嵌入区域,可以在等式2的顶部添加相对位置嵌入,以表明成对距离。
Disentangled Attention(分散注意力):分离注意力使用相对位置嵌入作为自我注意过程中的偏差。每个单词都使用两个向量来表示,这两个向量对其内容和相对位置进行了编码。然后将注意力计算分为三个部分:内容对内容、内容对位置和位置对内容,定义如下:
α
~
i
,
j
=
Q
(
x
i
)
K
(
x
j
)
⊤
⏟
content-to-content
+
Q
(
x
i
)
K
δ
(
i
,
j
)
P
⏟
content-to-position
+
Q
δ
(
j
,
i
)
P
K
(
x
j
)
⊤
⏟
position-to-content
(
4
)
\tilde{\alpha}_{i, j}=\underbrace{Q\left(x_i\right) K\left(x_j\right)^{\top}}_{\text {content-to-content }}+\underbrace{Q\left(x_i\right) K_{\delta(i, j)}^P}_{\text {content-to-position }}+ \underbrace{Q_{\delta(j, i)}^P K\left(x_j\right)^{\top}}_{\text {position-to-content }}\qquad\qquad(4)
α~i,j=content-to-content
Q(xi)K(xj)⊤+content-to-position
Q(xi)Kδ(i,j)P+position-to-content
Qδ(j,i)PK(xj)⊤(4)
其中
Q
P
,
K
P
∈
R
(
2
P
+
1
)
×
m
Q^P,K^P\in \R^{(2P+1)\times m}
QP,KP∈R(2P+1)×m 表示相对位置的query矩阵和key矩阵,
K
δ
(
i
,
j
)
P
K^P_{\delta(i,j)}
Kδ(i,j)P表示
K
P
K^P
KP 的
δ
(
i
,
j
)
\delta(i,j)
δ(i,j)行,
Q
δ
(
i
,
j
)
P
Q^P_{\delta(i,j)}
Qδ(i,j)P表示
Q
P
Q^P
QP 的
δ
(
i
,
j
)
\delta(i,j)
δ(i,j)行,后面两个乘积,即content-to-position和position-to-content用于测量单词对之间的相对位置。时间复杂度为
O
(
2
P
m
)
O(2Pm)
O(2Pm)。
Attention with Tree-Structured Relationships:文章提出的距离取代了相对距离
δ
(
i
,
j
)
\delta(i,j)
δ(i,j),而用的
δ
R
(
i
,
j
)
\delta_R(i,j)
δR(i,j),其中 R 代表祖先矩阵A 或者 兄弟矩阵S,其定义如下
δ
R
(
i
,
j
)
=
{
R
i
j
+
P
+
1
if
R
i
j
∈
[
−
P
,
P
]
0
if
R
i
j
=
∞
(
5
)
\delta_R(i, j)=\left\{\begin{array}{rll} R_{i j}+P+1 & \text { if } & R_{i j} \in[-P, P] \\ 0 & \text { if } & R_{i j}=\infty \end{array}\right.\qquad\qquad(5)
δR(i,j)={Rij+P+10 if if Rij∈[−P,P]Rij=∞(5)
由于有两种关系,我们认为每个head中只有一种关系,这两种关系的信息将通过多头注意力机制合并在一起,最终的输出为:
o
~
i
=
∑
j
j
∈
{
j
∣
δ
R
(
i
,
j
)
>
0
}
σ
(
α
~
i
,
j
3
d
)
(
V
(
x
j
)
+
V
R
i
j
P
)
(
6
)
\tilde{o}_i=\sum_j^{j \in\left\{j \mid \delta_R(i, j)>0\right\}} \sigma\left(\frac{\tilde{\alpha}_{i, j}}{\sqrt{3 d}}\right)\left(V\left(x_j\right)+V_{R_{i j}}^P\right)\qquad\qquad(6)
o~i=j∑j∈{j∣δR(i,j)>0}σ(3dα~i,j)(V(xj)+VRijP)(6)
值得一提的是只计算
δ
R
(
i
,
j
)
>
0
\delta_R(i,j)>0
δR(i,j)>0的,类似于滑动窗口的思想来减少时间和空间复杂度。
α
\alpha
α 要除以
3
d
\sqrt{3d}
3d 是因为有三项,要除以这个因子。
V
P
V^P
VP表示value相对位置的投影矩阵,
V
R
i
j
P
V_{R_{ij}}^P
VRijP 表示
V
P
V^P
VP 的第 $R_{ij} $ 行。
高效实现
标准Transformers中的全注意力机制随序列长度呈二次方增长,以前有人提出应用滑动窗口将注意力限制在固定范围内,使用滑动窗口,可以将序列数据中的节点对规划为线性分布,并与矩阵划分并行计算,这个方法不适用于AST,因为相关节点的位置分布随每个树结构而变化,本节有5中替代方法。
Mask:计算完注意力得分后,遮住 δ R ( i , j ) = 0 \delta_R(i,j)=0 δR(i,j)=0 的节点的注意力得分,这并不能减少时间复杂度
Loop:只在 δ R ( i , j ) > 0 \delta_R(i,j)>0 δR(i,j)>0 的节点中计算注意力得分,这可以减少计算注意力得分的时间和空间复杂度
Sparse:将 δ R \delta_R δR 以稀疏矩阵 S T ( δ R ) ST(\delta_R) ST(δR) 存放并且放入深度学习框架,在计算矩阵乘法时能够自动跳过零元素,这只能用于content-to-position 和 position-to-content
Gather with COO(GC):content-to-content可以通过附加的聚集操作来优化,核心思想是将需要计算的查询关键字对放入一对一的对应关系中,并将它们存储为密集矩阵。COO是存储稀疏张量的常用方法,其中只有非零元素存储为元素索引值 C O O r o w , C O O c o l COO_{row},COO_{col} COOrow,COOcol 和其对应的值 C O O v a l COO_{val} COOval。
用COO矩阵来聚合前面的
Q
(
x
)
,
K
(
x
)
,
Q
P
,
K
P
Q(x),K(x),Q^P,K^P
Q(x),K(x),QP,KP:
Q
row
=
Q
(
x
)
[
C
O
O
row
;
:
]
;
K
c
o
l
=
K
(
x
)
[
C
O
O
c
o
l
;
:
]
Q
v
a
l
P
=
Q
P
[
C
O
O
v
a
l
;
:
]
;
K
v
a
l
P
=
K
P
[
C
O
O
v
a
l
;
:
]
\begin{gathered} Q_{\text {row }}=Q(x)\left[C O O_{\text {row }} ;:\right] ; K_{c o l}=K(x)\left[C O O_{c o l} ;:\right] \\ Q_{v a l}^P=Q^P\left[C O O_{v a l} ;:\right] ; K_{v a l}^P=K^P\left[C O O_{v a l} ;:\right] \end{gathered}
Qrow =Q(x)[COOrow ;:];Kcol=K(x)[COOcol;:]QvalP=QP[COOval;:];KvalP=KP[COOval;:]
这样,计算得分的公式就变成下面这样
α
coo
=
Q
row
⊙
K
col
+
Q
row
⊙
K
val
P
+
Q
val
P
⊙
K
col
\alpha_{\text {coo }}=Q_{\text {row }} \odot K_{\text {col }}+Q_{\text {row }} \odot K_{\text {val }}^P+Q_{\text {val }}^P \odot K_{\text {col }}
αcoo =Qrow ⊙Kcol +Qrow ⊙Kval P+Qval P⊙Kcol
⊙
\odot
⊙ 表示点乘,
α
c
o
o
\alpha_{coo}
αcoo 表示
α
~
\tilde \alpha
α~ 中的非零元素。并且
α
~
[
C
O
O
r
o
w
[
i
]
;
C
O
O
c
o
l
[
i
]
]
=
α
c
o
o
[
i
]
\tilde \alpha[COO_{row}[i];COO_{col}[i]]=\alpha_{coo}[i]
α~[COOrow[i];COOcol[i]]=αcoo[i]。
Gather with decomposed COO (GDC):在进行聚合操作钱,可以先分解COO再聚集,为了减少GC中聚集的数量,使得每个子矩阵 δ R s \delta_R^s δRs 只包含具有相同相对距离s的节点对
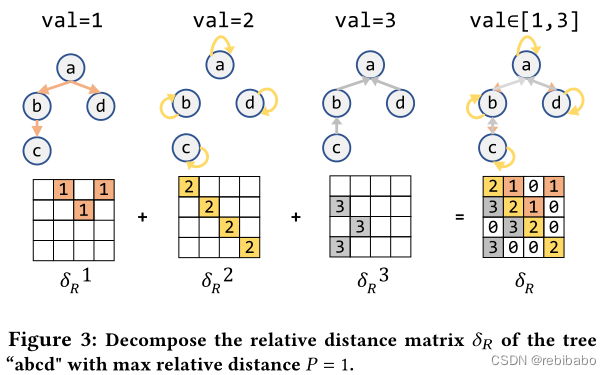
如上图3所示,原始的
δ
R
\delta_R
δR 是最右边的图,它包含有三种值 1,2,3,按照值将矩阵拆解成三个子矩阵,再对这三个子矩阵
C
O
O
s
COO^s
COOs 进行 GC 操作:
Q
r
o
w
s
=
Q
(
x
)
[
C
O
O
r
o
w
s
;
:
]
,
K
c
o
l
s
=
K
(
x
)
[
C
O
O
c
o
l
s
;
:
]
Q_{row_{s}}=Q(x)[COO^s_{row};:],K_{col_{s}}=K(x)[COO^s_{col};:]
Qrows=Q(x)[COOrows;:],Kcols=K(x)[COOcols;:]
自注意力得分就如下计算得到:
α
c
o
o
s
=
(
Q
r
o
w
s
+
Q
s
P
)
⊙
(
K
r
o
w
s
+
K
s
P
)
−
(
Q
s
P
⊙
K
s
P
)
\alpha_{coo_{s}}=(Q_{row_{s}}+Q_s^P)\odot(K_{row_s}+K_s^P)-(Q_s^P\odot K_s^P)
αcoos=(Qrows+QsP)⊙(Krows+KsP)−(QsP⊙KsP)
其中
α
c
o
o
s
\alpha_{coo_s}
αcoos 表示
δ
R
s
\delta_R^s
δRs 中节点的自注意力得分,所有子矩阵的自注意力得分可以并行计算,最终的自注意得分就等于所有
α
c
o
o
s
\alpha_{coo_s}
αcoos 的和:
α
c
o
o
=
∑
s
=
1
2
P
+
1
α
c
o
o
s
\alpha_{coo}=\sum_{s=1}^{2P+1}\alpha_{coo_s}
αcoo=s=1∑2P+1αcoos
使用分解的GC的原因有三个:
- K P , Q P K^P,Q^P KP,QP 可以重复使用,因为每一个 Q r o w s , K r o w s Q_{row_s} ,K_{row_s} Qrows,Krows 有相同的相对距离 s。位置嵌入 s 可以直接添加到内容content中而不需要收集操作。
- 只需要四分之一的收集操作(这个文中有证明)
- 只需要点乘,且 Q s P ⊙ K s P Q_s^P\odot K_s^P QsP⊙KsP 的结果可以重复利用
实验
实验设置
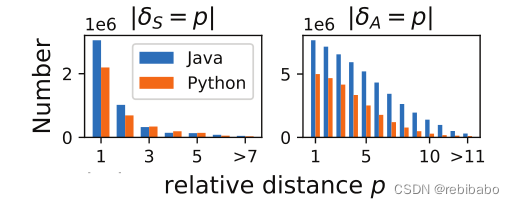
实验训练集是Java和Python,下图显示了大多数祖先关系距离在5以内,兄弟关系距离在10以内
预处理阶段:删除标点、分割单词,拆分的节点视为原始父节点的新子节点,例如gettabletypes作为父节点,get、table、types作为该节点的三个子节点,还会“reverse the children of the root node”当AST大小超过指定的最大大小,来防止重要信息被剪切。
评估指标
使用了语料库 BLEU、METEOR、ROUGE-L 来评估性能。
基线方法
与16中方法进行比较,根据输入类型可以分为5组:
- Code:直接将代码视为纯文本作为输入
- AST:以AST作为输入,并使用特定于树的编码器进行编码,如Tree LSTM 为训练添加代码信息和强化,另一种将AST视为图形进行编码
- AST(PD):以路径分解的AST作为输入
- AST(SBT):结构化AST
- AST(POT):线性化AST
实验结果
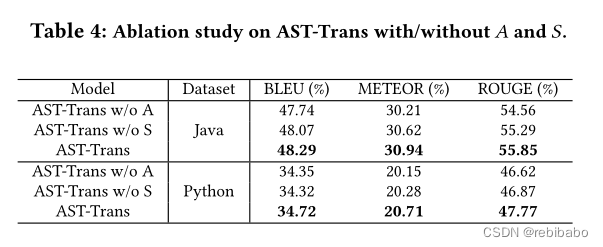
如下表3所示,AST-Trans在三个指标都优于所有基线
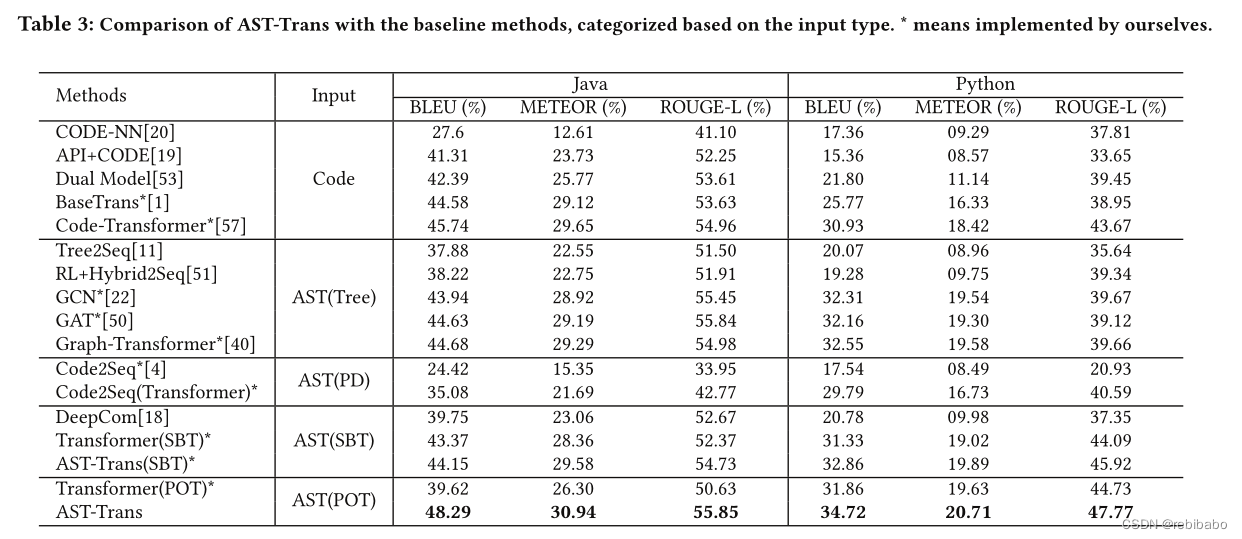
结果表明,当使用了祖先关系和兄弟关系时,性能得到了提高。然而,单独使用其中一种关系已经可以取得接近的结果,并超过所有先前的基线。
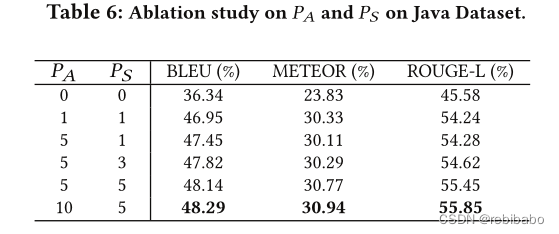
随着兄弟关系和祖先关系最大距离的增大,性能也会得到提高,但是由于它们大部分距离在10和5之间,所以越往后,改善越来越小


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









