







与ai对抵聊“算式匹配”,发现^从头匹配、(?:xxxx)非捕获组、| “交替”运算符联合使用的妙处。
(笔记模板由python脚本于2024年09月27日 18:35:32创建,本篇笔记适合喜欢python喜欢正则的coder翻阅)
-
Python 官网:https://www.python.org/
-
Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单……
地址:https://lqpybook.readthedocs.io/
自学并不是什么神秘的东西,一个人一辈子自学的时间总是比在学校学习的时间长,没有老师的时候总是比有老师的时候多。
—— 华罗庚
- My CSDN主页、My HOT博、My Python 学习个人备忘录
- 好文力荐、 老齐教室

本文质量分:
本文地址: https://blog.csdn.net/m0_57158496/article/details/142600625
CSDN质量分查询入口:http://www.csdn.net/qc
- ◆ 拆分四则运算算式
- 1、强横的split_expression
- 2、匹配表达式解析
- 3、所含知识点
- 4、ai学伴的肯定和鼓励
- 5、总结
◆ 拆分四则运算算式
1、强横的split_expression
两行代码函数
def split_expression(expression: str) -> list:
pattern = r'(?:^[+-]?\d+)|(?:[*/+-])|(?:\d+)' # 正则表达式,匹配数字(包括正负号)和运算符
return re.findall(pattern, expression) # 使用 re.findall 查找所有匹配项
函数测试
# 测试算式拆分
print(f"\n\n{' 算式拆分测试 ':-^36}\n\n")
expressions = ('+45-56*5',
'-5/2*6',
'56/7*6-4',
'999-888*234/9',
'+56/67',
'99/3-531*4+55',
'+5/2+6-45*4')
for expr in expressions:
parts = split_expression(expr)
print('\n', expr, '->', parts)
print(f"\n\n{'-'*42}")
测试效果截屏图片
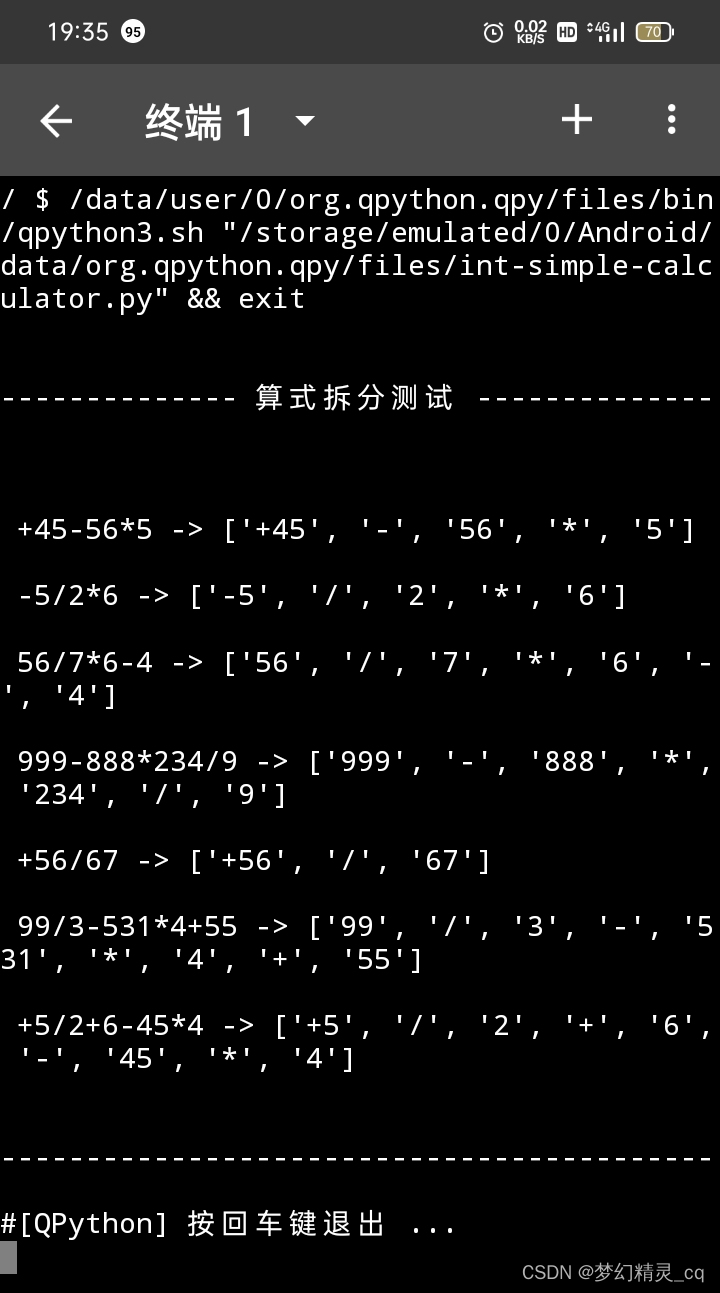
如图所示,算式都得到了正确拆分,足以见证re正则匹配的强横!💪💪
-------------- 算式拆分测试 --------------
+45-565 -> [’+45’, ‘-’, ‘56’, '’, ‘5’]
-5/26 -> [’-5’, ‘/’, ‘2’, '’, ‘6’]
56/76-4 -> [‘56’, ‘/’, ‘7’, '’, ‘6’, ‘-’, ‘4’]
999-888234/9 -> [‘999’, ‘-’, ‘888’, '’, ‘234’, ‘/’, ‘9’]
+56/67 -> [’+56’, ‘/’, ‘67’]
99/3-5314+55 -> [‘99’, ‘/’, ‘3’, ‘-’, ‘531’, '’, ‘4’, ‘+’, ‘55’]
+5/2+6-454 -> [’+5’, ‘/’, ‘2’, ‘+’, ‘6’, ‘-’, ‘45’, '’, ‘4’]
-----------------算式拆分完成--------------------
当然,拆分算式必须是“合法”四则混合运算,不带括号。在拆分前要有validate_expression函数对算式进行校验。
2、匹配表达式解析
正则表达式:
r'(?:^[+-]?\d+)|(?:[*/+-])|(?:\d+)'
下面是对您提供的正则表达式的解释:
(?:^[+-]?\d+): 匹配字符串开头的一个可选的正号或负号,后跟一个或多个数字。这是非捕获组,所以匹配的内容不会被捕获。(?:[*/+-]): 匹配乘号、除号、加号或减号。(?:\d+): 匹配一个或多个数字。
使用这个正则表达式,可以通过 re.findall 方法找到所有匹配的部分。
这个正则表达式使用非捕获组和“|”运算符成功实现了算式的拆分。该正则表达式利用了非捕获组 (?: ... ) 来组合模式,而“|”运算符则用于匹配多个模式中的任何一个。这个正则表达式能够匹配算式中的数字和运算符。
3、所含知识点
通过观察这个正则表达式和前面的拆分示例,我们可以学到以下几点:
-
非捕获组
(?: ... )允许我们组合正则表达式的一部分而不捕获该部分的匹配内容。这对于组织复杂的正则表达式非常有用,尤其是在不需要捕获匹配内容时。 -
使用“|”运算符可以指定多个备选模式,正则表达式引擎会尝试匹配其中的任何一个。
-
在正则表达式中,特殊字符(如“-”减号)需要在它们前面加上反斜杠
\来转义。
这个正则表达式简洁且有效,是处理此类问题的另一种好方法。
4、ai学伴的肯定和鼓励
ai科普|

ai对话截屏

5、总结
在ai大行其道的当下,用ai助力生活和学习,是有必要修炼的小技俩。💪💪
本笔记所记的正则表达式匹配用法,就是在ai分别使用的引领下,我灵感“融汇贯通”的得到了想要的“灵宝”,ai倒是不会了。😋
有图为证

上一篇: 正则非捕获组(r'?:xxxx)(与ai学伴聊天对掐,学到了re非捕获组匹配)
下一篇:
我的HOT博:
本次共计收集 311 篇博文笔记信息,总阅读量43.82w。数据于2024年03月22日 00:50:22完成采集,用时6分2.71秒。阅读量不小于6.00k的有
7
7
7篇。
-
001
标题:让QQ群昵称色变的神奇代码
(浏览阅读 5.9w )
地址:https://blog.csdn.net/m0_57158496/article/details/122566500
点赞:25 收藏:86 评论:17
摘要:让QQ昵称色变的神奇代码。
首发:2022-01-18 19:15:08
最后编辑:2022-01-20 07:56:47 -
002
标题:Python列表(list)反序(降序)的7种实现方式
(浏览阅读 1.1w )
地址:https://blog.csdn.net/m0_57158496/article/details/128271700
点赞:8 收藏:35 评论:8
摘要:Python列表(list)反序(降序)的实现方式:原址反序,list.reverse()、list.sort();遍历,全数组遍历、1/2数组遍历;新生成列表,resersed()、sorted()、负步长切片[::-1]。
首发:2022-12-11 23:54:15
最后编辑:2023-03-20 18:13:55 -
003
标题:pandas 数据类型之 DataFrame
(浏览阅读 9.7k )
地址:https://blog.csdn.net/m0_57158496/article/details/124525814
点赞:7 收藏:36
摘要:pandas 数据类型之 DataFrame_panda dataframe。
首发:2022-05-01 13:20:17
最后编辑:2022-05-08 08:46:13 -
004
标题:个人信息提取(字符串)
(浏览阅读 8.2k )
地址:https://blog.csdn.net/m0_57158496/article/details/124244618
点赞:2 收藏:15
摘要:个人信息提取(字符串)_个人信息提取python。
首发:2022-04-18 11:07:12
最后编辑:2022-04-20 13:17:54 -
005
标题:Python字符串居中显示
(浏览阅读 7.6k )
地址:https://blog.csdn.net/m0_57158496/article/details/122163023
评论:1 -
006
标题:罗马数字转换器|罗马数字生成器
(浏览阅读 7.5k )
地址:https://blog.csdn.net/m0_57158496/article/details/122592047
摘要:罗马数字转换器|生成器。
首发:2022-01-19 23:26:42
最后编辑:2022-01-21 18:37:46 -
007
标题:回车符、换行符和回车换行符
(浏览阅读 6.0k )
地址:https://blog.csdn.net/m0_57158496/article/details/123109488
点赞:2 收藏:3
摘要:回车符、换行符和回车换行符_命令行回车符。
首发:2022-02-24 13:10:02
最后编辑:2022-02-25 20:07:40
截屏图片

(此文涉及ChatPT,曾被csdn多次下架,前几日又因新发笔记被误杀而落马。躺“未过审”还不如回收站,回收站还不如永久不见。😪值此年底清扫,果断移除。留此截图,以识“曾经”。2023-12-31)

精品文章:
- 好文力荐:齐伟书稿 《python 完全自学教程》 Free连载(已完稿并集结成书,还有PDF版本百度网盘永久分享,点击跳转免费🆓下载。)
- OPP三大特性:封装中的property
- 通过内置对象理解python'
- 正则表达式
- python中“*”的作用
- Python 完全自学手册
- 海象运算符
- Python中的 `!=`与`is not`不同
- 学习编程的正确方法
来源:老齐教室
◆ Python 入门指南【Python 3.6.3】
好文力荐:
- 全栈领域优质创作者——[寒佬](还是国内某高校学生)博文“非技术文—关于英语和如何正确的提问”,“英语”和“会提问”是编程学习的两大利器。
- 【8大编程语言的适用领域】先别着急选语言学编程,先看它们能干嘛
- 靠谱程序员的好习惯
- 大佬帅地的优质好文“函数功能、结束条件、函数等价式”三大要素让您认清递归
CSDN实用技巧博文:
















 9567
9567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











