







1.使用场景
Map Join适用于一张表十分小、一张表很大的场景。
2.优点
思考:在Reduce端处理过多的表,非常容易产生数据倾斜。怎么办?
在Map端缓存多张表,提前处理业务逻辑,这样增加Map端业务,减少Reduce端数据的压力,尽可能的减少数据倾斜。
3.具体办法:采用DistributedCache
(1)在Mapper的setup阶段,将文件读取到缓存集合中。
(2)在驱动函数中加载缓存。
// 缓存普通文件到Task运行节点。
job.addCacheFile(new URI(“file://e:/cache/pd.txt”));
Map Join案例实操
1.需求
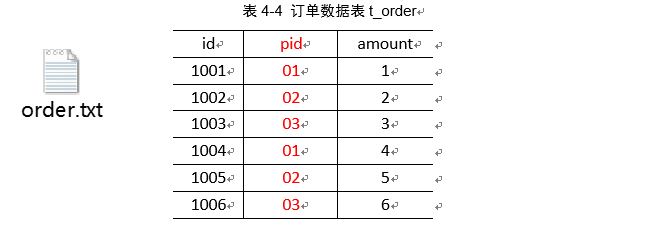
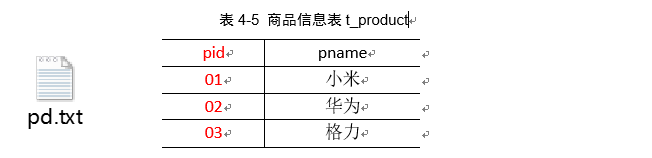
将商品信息表中数据根据商品pid合并到订单数据表中。
2.需求分析
MapJoin适用于关联表中有小表的情形。

3.实现代码
(1)先在驱动模块中添加缓存文件
| package test; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class DistributedCacheDriver { public static void main(String[] args) throws Exception { // 0 根据自己电脑路径重新配置 args = new String[]{“e:/input/inputtable2”, “e:/output1”}; // 1 获取job信息 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 2 设置加载jar包路径 job.setJarByClass(DistributedCacheDriver.class); // 3 关联map job.setMapperClass(DistributedCacheMapper.class); // 4 设置最终输出数据类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(NullWritable.class); // 5 设置输入输出路径 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 6 加载缓存数据 job.addCacheFile(new URI(“file:///e:/input/inputcache/pd.txt”)); // 7 Map端Join的逻辑不需要Reduce阶段,设置reduceTask数量为0 job.setNumReduceTasks(0); // 8 提交 boolean result = job.waitForCompletion(true); System.exit(result ? 0 : 1); } } |
(2)读取缓存的文件数据
| package test; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.util.HashMap; import java.util.Map; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class DistributedCacheMapper extends Mapper<LongWritable, Text, Text, NullWritable>{ Map<String, String> pdMap = new HashMap<>(); @Override protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException { // 1 获取缓存的文件 URI[] cacheFiles = context.getCacheFiles(); String path = cacheFiles[0].getPath().toString(); BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(path), “UTF-8”)); String line; while(StringUtils.isNotEmpty(line = reader.readLine())){ // 2 切割 String[] fields = line.split(“\t”); // 3 缓存数据到集合 pdMap.put(fields[0], fields[1]); } // 4 关流 reader.close(); } Text k = new Text(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { // 1 获取一行 String line = value.toString(); // 2 截取 String[] fields = line.split(“\t”); // 3 获取产品id String pId = fields[1]; // 4 获取商品名称 String pdName = pdMap.get(pId); // 5 拼接 k.set(line + “\t”+ pdName); // 6 写出 context.write(k, NullWritable.get()); } } |
想了解大数据培训开发技术知识,关注我,有更多精彩内容与您分享!
文章转载链接:http://www.atguigu.com/jsfx/12049.html















 1804
1804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









