




1、前言
随着自动化测试的普及与落地推广,出现了众多知名的自动化测试工具,如Selenium 、Robot Framework、Playwright等。本文将介绍一款在Python环境下的mechanize库,这个库能够模拟浏览器行为,支持发送HTTP请求、解析HTML页面和模拟用户输入等功能,非常适合开发自动化测试程序。
在如今的数字化时代,自动化与Web服务器的交互操作变得越来越重要。无论是数据抓取、网站测试,还是自动化表单提交,开发者都在寻找高效便捷的解决方案。Mechanize作为一款强大的Python库,为这些需求提供了完美的答案。
2、简介
在Python中进行有状态的程序化网页浏览。通过程序化浏览页面,轻松填写HTML表单和点击链接等操作,可以实现自动化测试、自动化爬虫等操作。
主要功能:
mechanize.Browser类实现了urllib2.OpenerDirector的接口,因此可以打开任何URL,不仅限于HTTP。
简便的HTML表单填写。
便捷的链接解析和跟踪。
浏览器历史记录,.back()和.reload()方法。
Referer HTTP请求头已正确添加(可选)。
自动遵守robots.txt。
自动处理HTTP-Equiv和Refresh。
Github网址:https://github.com/python-mechanize/mechanize
3、安装
1、正式版本:
pip3 install mechanize
2、开发版本:
git clone https://github.com/python-mechanize/mechanize.git
cd mechanize
pip3 install -e .
3、手动安装,只需在PYTHONPATH上的某处添加mechanize子目录。
那么,Mechanize究竟是如何简化与HTTP Web服务器的交互操作的?为什么它成为了开发者的首选工具
4、快速上手1、简单示例:
import mechanize
# 创建一个浏览器对象
br = mechanize.Browser()
# 设置请求头,伪装成浏览器
br.addheaders = [('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36')]
# 设置各种处理器
br.set_handle_equiv(True) # 解析HTML文档中的meta http-equiv标签
br.set_handle_gzip(True) # 解压缩gzip编码的响应
br.set_handle_redirect(True) # 允许自动处理HTTP重定向
br.set_handle_referer(True) # 在请求头中添加Referer字段
br.set_handle_robots(False) # 不遵循robots.txt文件
# 设置自动刷新的处理,max_time是刷新等待的最长时间
br.set_handle_refresh(mechanize._http.HTTPRefreshProcessor(), max_time=1)
# 是否设置debug模式
br.set_debug_http(True)
br.set_debug_redirects(True)
br.set_debug_responses(True)
# 打开一个网页
br.open("https://mechanize.readthedocs.io/en/latest/")
# 选择搜索表单
br.select_form(id='rtd-search-form')
# 填写搜索关键词
br['q'] = 'python'
# 提交搜索表单
br.submit()
# 获取搜索结果页面内容
content = br.response().read()
# 打印
print(content)
运行后,打印的结果。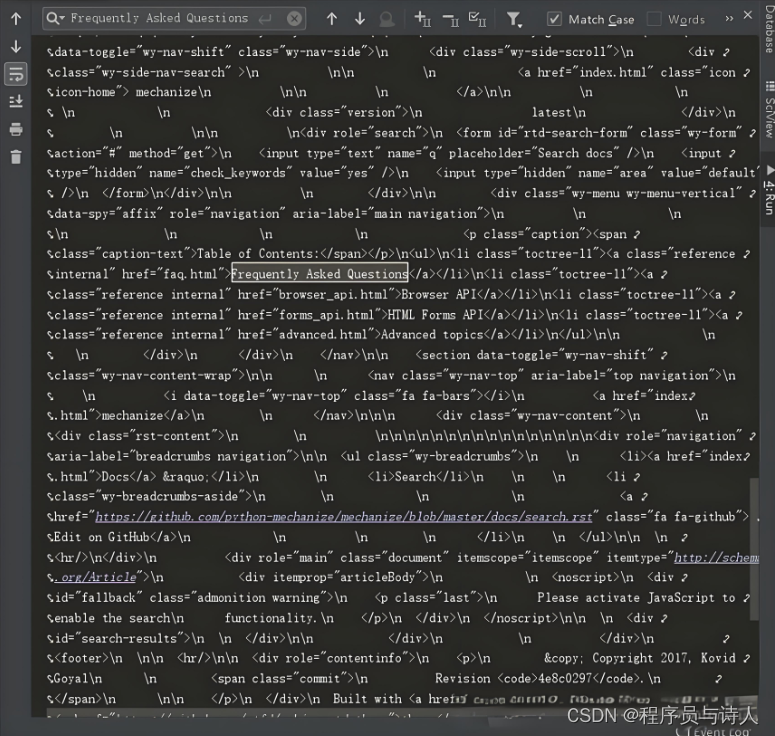
2、官方示例:
import re
import mechanize
br = mechanize.Browser()
br.open("http://www.example.com/")
# follow second link with element text matching regular expression
response1 = br.follow_link(text_regex=r"cheese\s*shop", nr=1)
print(br.title())
print(response1.geturl())
print(response1.info()) # headers
print(response1.read()) # body
br.select_form(name="order")
# Browser passes through unknown attributes (including methods)
# to the selected HTMLForm.
br["cheeses"] = ["mozzarella", "caerphilly"] # (the method here is __setitem__)
# Submit current form. Browser calls .close() on the current response on
# navigation, so this closes response1
response2 = br.submit()
# print currently selected form (don't call .submit() on this, use br.submit())
print(br.form)
response3 = br.back() # back to cheese shop (same data as response1)
# the history mechanism returns cached response objects
# we can still use the response, even though it was .close()d
response3.get_data() # like .seek(0) followed by .read()
response4 = br.reload() # fetches from server
for form in br.forms():
print(form)
# .links() optionally accepts the keyword args of .follow_/.find_link()
for link in br.links(url_regex="python.org"):
print(link)
br.follow_link(link) # takes EITHER Link instance OR keyword args
br.back()
Mechanize的最大优势在于其模拟浏览器的能力,允许开发者自动化地与网页进行交互。例如,开发者小王需要定期从某个网站抓取数据。通过使用Mechanize,他能够编写脚本自动登录网站,导航至特定页面,并抓取所需的数据。这不仅节省了大量的时间,还避免了手动操作的繁琐和重复
Mechanize库不仅简化了与HTTP Web服务器的交互操作,还为开发者提供了强大的自动化能力。通过使用Mechanize,开发者可以更高效地完成数据抓取、网站测试等任务,专注于更具创造性的开发工作。



















 692
692

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









