



AVOS
研究背景与问题
现有局限:传统声音源定位(SSL)等方法仅提供粗略的热力图,无法精确分割物体形状;现有数据集缺乏像素级标注,限制了精细的跨模态学习。
任务定义:AVS要求同时完成两个目标:
分割:生成发声物体的像素级掩码(二值或语义)。
语义分类:区分不同发声物体的类别(仅语义标签子集)。
贡献与创新
AVSBench数据集:
包含三个子集:
单源(S4):单发声物体,半监督(仅首帧标注)。
多源(MS3):多发声物体,全监督。
语义标签(AVSS):70类物体,全监督语义分割。
规模:总计12,356视频,82,972标注帧,涵盖丰富场景。
基线方法:
TPAVI模块(Temporal Pixel-wise Audio-Visual Interaction):通过时间维度的像素级跨模态交互,将音频特征作为视觉分割的语义引导。
正则化损失(LAVM):约束音频与视觉特征的分布一致性,增强跨模态对齐。
任务设置:
S4(半监督单源分割)、MS3(全监督多源分割)、AVSS(全监督语义分割)。
实验结果
性能优势:在S4和MS3任务中,TPAVI模型显著优于SSL、VOS和SOD方法(如PVT-v2在MS3的mIoU达54%)。
在AVSS任务中,模型在70类语义分割中表现优于视频对象分割方法(如AOT),验证了音频对语义分类的辅助作用。
关键发现:
TPAVI模块通过时间上下文提升分割精度,尤其在多源场景中效果显著。
预训练(单源到多源)和正则化损失(LAVM)均有效提升模型泛化性。
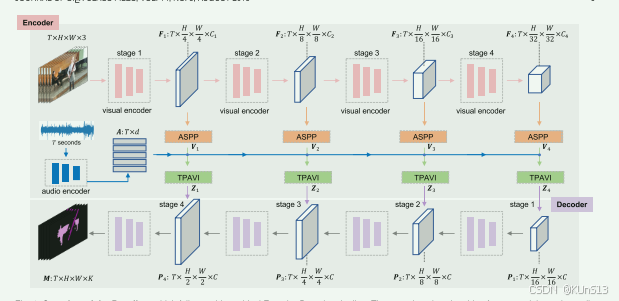
模型架构解析
-
编码器(Encoder)
- 视觉特征提取:
使用卷积网络(如ResNet-50)或视觉Transformer(如PVT-v2)提取多层级视觉特征。- 输出层级特征:Fi∈RT×hi×wi×Ci,其中(hi,wi)=(H,W)/2i+1,共4个层级(i=1,2,3,4)。
- 音频特征提取:
使用预训练的VGGish网络处理音频频谱图,输出音频特征A∈RT×d(d=128)。
- 视觉特征提取:
-
跨模态融合(Cross-Modal Fusion)
- 视觉特征后处理:
通过ASPP模块(Atrous Spatial Pyramid Pooling)增强视觉特征的感受野,生成多尺度特征Vi。 - 时序像素级音频-视觉交互(TPAVI模块):
- 音频特征对齐:将音频特征A线性变换后复制到与视觉特征Vi相同的空间维度。
- 注意力机制:通过点积计算音频与视觉特征的相似性矩阵αi,加权融合后更新视觉特征:Zi=Vi+μ(αig(Vi))
- 作用:通过时序关联增强像素级音频-视觉对齐,动态定位发声物体。
- 视觉特征后处理:
-
解码器(Decoder)
- 采用类似Panoptic-FPN的结构,逐级融合多层级特征(Z1,Z2,Z3,Z4)。
- 最终输出分割掩码M∈RT×H×W×K,其中K=1(S4/MS3任务)或类别数(AVSS任务)。
-
损失函数
- 主损失:二元交叉熵(BCE)监督分割结果。
- 正则化损失(LAVM):
通过KL散度约束掩码区域视觉特征与音频特征的分布一致性,增强跨模态关联。
关键设计亮点
-
TPAVI模块
- 实现时序维度的跨模态交互,解决多源声音动态变化问题。
- 通过像素级注意力机制,精准关联音频信号与视觉对象(如图12中的热力图所示)。
-
多任务适应性
- S4/MS3任务:输出二值掩码,通过Sigmoid激活。
- AVSS任务:输出语义分割图,通过Softmax分类,支持70类语义标签。
-
预训练策略
- 在单源数据上预训练模型,提升多源场景下的泛化能力(如表8所示,性能提升显著)。
解决的问题与优势
- 挑战:传统声音定位(SSL)仅提供模糊热力图,无法精确分割形状;视频分割(VOS)依赖视觉先验,难以处理动态声源。
- 创新:
- 首次实现像素级音频-视觉联合分割,支持语义类别预测。
- 通过TPAVI模块和AVM损失,显式建模跨模态时序依赖,提升复杂场景鲁棒性。
总结
图四的框架通过多模态特征融合和时序建模,实现了从粗定位到像素级分割的跨越。其设计兼顾了单源、多源及语义分割需求,为音频驱动的视觉理解提供了新思路。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









