




- cmp(a,b):比较;两个列表/元组的元素
- len(a):列表/元组元素个数
- max(a):返回列表/元组元素最大值
- min(a):返回列表/元组元素最小值
- sum(a):将列表/元组元素求和
- sorted(a):对列表的元素进行升序排列
列表的方法:
- a.append(1):将1添加到a列表的末尾
- a.count(1):统计列表a中1出现的次数
- a.extend([1,2]):将列表[1,2]的内容追加到列表a的末尾中
- a.index(1):从列表a中找出第一个1的索引位置
- a.insert(2,1):将1插入列表a的索引为2的位置
- a.pop(1):移除列表a中索引为1的元素
列表解析——能够简化我们队列表元素注意进行操作的代码:
a = [1,2,3]
b=[]
for i in a:
b.append(i+2)
print(b) #列表b=[3, 4, 5]
可简化为:
a=[1,2,3]
b=[i=2 for i in a]
print(b) #列表b=[3, 4, 5]
2.字典
通俗来讲,它也是一个列表,但是它的“下标”不再是以“0”开头的数字,而是让自己定义的“键”(key)开始。
创建一个字典的基本方法为:
d={'today':20,'tomorrow':30} #today/tomorrow就是字典的键,20/30则是键对应的值 d['today'] #该值为20 d['tomorrow'] #该值为30
通过dict()函数转换,或者通过dict.fromkeys来创建:
dict([['today',20],['tomorrow',30]]) #也相当于{'today':20,'tomorrow':30}
dict.fromkeys(['today','tomorrow'],20) #相当于{'today':20,'tomorrow':20}
3.集合
和数学概念上的集合基本上是一致的。它与列表的区别:
a.在于它的元素的不重合的,而且是无序的;
b.它不支持索引。
一般我们用大括号{}或者set()来创建集合。
s={1,2,2,3} #2会自动去重,得到{1,2,3} s=set([1,2,2,3]) #同样会将列表转换为集合,得到{1,2,3}
集合的运算:
a = t | s #并集
b = t & s #交集
c = t - s #差集(项在t中,但不在s中)
d = t ^ s #对称差集(项在t或s中,但不会同时出现在二者中)
4.函数式编程
函数式编程主要由几个函数构成:lambda()、map()、reduce()、filter()
a、lambda():主要用来定义“行内函数”
b、map():类似于列表解析,例如:列表解析可以这样写 b =[i+2 for i in a],但是利用map函数我们可以这么写:
a=[1,2,3]
b =map(lambda x: x+2,a)
b=list(b)
print(b) #结果是[3,4,5]
注:在3.x需要b = list(b)这一步,在2.x就不需要。是因为在3.x中map函数进进是创建一个待运行的命令容器,只有其他函数调用它的时候才会返回结果。
map()也接受多参数的函数,如map(lambda x,y:x*y,a,b) 表示将a、b两个列表的元素对应相乘,把结果返回给新列表。map()命令和for循环的对比:列表解析本身还是for命令,在Python中for命令的执行效率不高,而map函数实现了相同的功能,而效率更高
c、reduce()函数:与map函数类似,map()用于逐一遍历,reduce()函数用于递归计算。例如:
reduce(lambda x,y : x\*y,range(1,n+1)) #可以计算n的阶乘
注:在2.x中,上述命令可以直接运行,在3.x中,reduce函数已经被移除了全局命名空间,置于fuctools库中,可通过from fuctools import reduce引入reduce。
上述代码也可用循环语句写成:
s=1
for i in range(1,n+1):
s=s\*i
d、filter()函数:它是一个过滤器,用于筛选列表中符合条件的元素。例如:
b=filter(lambda x : x>5 and x<8,range(10))
b=list(b)
print(b) #结果为[6, 7]
上述语句也可以用列表解析写出:
b=[i for i in range(10) if i>5 and i<8]
我们使用map()、reduce()、filter()最终的目的是兼顾简洁和效率,因为map()、reduce()、filter()的循环速度比Python内置的while和for循环快的多。
(4)库的导入和添加
1.库的导入:例如:导入math库
import math
math.sin(1) #计算正弦
math.exp(1) #计算指数
math.pi #内置的圆周率常数
重命名库:
import math as m
m.sin(1)
指定导入某个函数:
from math import exp as e
e(1) help('modules') #获得已安装的所有模块名
2.导入futurn特征
使用2.x的用户可以通过引入futurn特征的方式兼容代码,如:
#将print变成函数形式,即用print(a)的方式输出:
from __futurn__ import print_function
#3.x的3/2=1.5,3//2=1;2.x的3/2=1
from __futurn__ import division
3.添加第三方库
以安装pandas为例:
打开cmd,输入 pip install pandas,点击回车即可
2.3 Python数据分析工具
Python数据挖掘相关扩展库
- numpy:提供数组支持,以及相应的高效的处理函数
- sicpy:提供矩阵支持,以及矩阵相关的数值计算模块
- matplotlib:强大的数据可视化工具、作图库
- pandas:强大、灵活的数据分析和探索工具
- statsmodels:统计建模和计量经济学,包括描述统计、统计模型估计和推断
- scikit-learn:支持回归、分类、聚类等的强大的机器学习库
- keras:深度学习库,用于建立神经网络以及深度学习模型
- gensim:用来做文本主题模型的库,文本挖掘可以用到
2.3.1 numpy
Python并没有提供真正的数组功能,而numpy则提供了真正的数组功能,它还是很多更高级库的依赖库,,例如scipy、matplotlib、pandas等。numpy内置函数的处理速度是C语言级别的,因此在编写函数的时候应当尽量的使用它们内置的函数,避免出现效率瓶颈的问题(尤其是涉及循环问题)。
安装numpy:
pip install numpy #在Windows中可以像安装其他第三方库一样用pip完成 python setup.py install #Windows还可自行下载源代码,然后用此代码安装 sudo apt-get install python-numpy #在Linux的Ubuntu下安装
numpy的基本操作:
#-\*- coding :utf-8 -\*
import numpy as np #一般用np作为numpy的别名
a = np.array([2,0,1,5]) #创建数组
print(a) #打印结果
print(a[:3]) #引用前3个数字(切片)
print(a.min()) #输出a的最小值
a.sort() #将a的元素从小到大排列,此操作直接修改a,print(a)为[0,1,2,5]
print(a)
b = np.array([[1,2,3],[4,5,6]]) #创建二维数组
print(b\*b) #输出数组的平方阵[[1,4,9],[16,25,36]]
numpy官网:http://www.numpy.org/或者http://reverland.org/python/2012/08/12/numpy/
2.3.2 SciPy
SciPy包含的功能有最优化、线性代数、几份、插值、拟合、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科学与工程中常用的计算。SciPy依赖于numpy,因此安装它之前需要先安装numpy,安装scipy和安装numpy在Windows平台上是一样的,直接用pip进行安装即可,sudo apt-get install python-scipy 在Linux的Ubuntu下安装。
SciPy求解非线性方程组和数值积分:
#-\*-coding:utf-8 -\*
#求解非线性方程组2x1-x2^2=1,x1^2-x2=2
from scipy.optimize import fsolve #导入求解方程组的函数
def f(x): #定义要求解的方程组
x1=x[0]
x2=x[1]
return [2\*x1-x2\*\*2-1,x1\*\*2-x2-2]
result = fsolve(f,[1,1]) #输出初值[1,1]并求解
print(result) #数值积分
from scipy import integrate #导入积分函数
def g(x): #定义被积函数
return (1-x\*\*2)\*\*0.5
pi_2,err = integrate.quad(g,-1,1) #积分结果和误差
print(pi_2\*2) #有微积分知识知道积分结果为圆周率pi的一半
2.3.3 Matplotlib
主要用于绘制二维图,也可以进行简单的三维绘图。安装方法也和上述两个库的安装方法一致。
注:matplotlib对上级库的依赖较多,手动安装的时候需要吧这些库也逐一安装完成
matplotlib绘图的基本代码:
#-\*-coding:utf-8 -\*
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib
x = np.linspace(0,10,1000) #作图的变量自变量
y = np.sin(x)+1 #因变量y
z = np.cos(x\*\*2)+1 #因变量z
plt.figure(figsize=(8,4)) #设置图像大小
plt.plot(x,y,label= '$\sin x+1$',color='red',linewidth=2) #作图,设置标签,线条颜色,线条大小
plt.plot(x,z,'b--',label='$\cos x^2+1$') #作图,设置标签,线条类型
plt.xlabel('Time(s)') #X轴名称
plt.ylabel('Volt') #Y轴名称
plt.title('A Simple Example') #标题
plt.ylim(0,2.2) #显示Y轴范围
plt.legend() #显示图例
plt.show()
做出来的图如下:
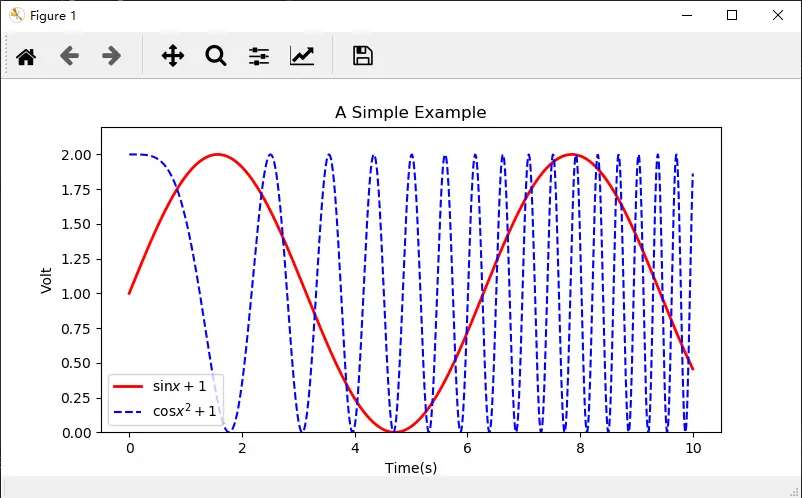
以上代码做出来的图
如果使用的是中文标签,会发现中文标签无法正常显示。这是由于matplotlib的默认字体是英文导致的,解决办法是在作图之前手动将默认字体设置为中文字体,如黑体(SimHei):
plt.rcParams['font.sans-serif']=['SimHei'] #这句用来正常显示中文字体
如果保存图像负号不显示则可以用以下代码解决:
plt.rcParams['axes.unicode\_minus']=False #解决保存图像是负号“-”显示为方块的问题
建议:有空多去matplotlib提供的“画廊”欣赏他做出来的漂亮效果,链接如下:https://matplotlib.org/gallery.html
2.3.4 pandas
pandas是Python下最强大的数据分析和探索工具,pandas构建在numpy之上,使得以numpy为中心的应用很容易使用。pandas的功能非常强大,支持类似于SQL的增删改查,并带有丰富的数据处理函数。支持时间序列分析功能;支持灵活处理缺失数据等。
(1)安装
安装方法和以上的库均一样,但是在使用pandas之前需要先安装numpy才能使用。pandas本身是不支持Excel文件的读写的,需要安装xlrd(读)和xlwt(写)库才能支持Excel的读写。
(2)使用
pandas基本的数据结构是Series和DataFrame,Series是序列类似一堆数组;DataFrame则是相当于一张二维的表格,类似于二维数组,它的每一列就是一个Series。为了定位Series中的元素,pandas提供了Index对象,每个Series都会带有一个对应的Index,用来标记不同的元素。Index类似于SQL中的主键DataFrame相当于对个带有Index的Series的组合(本质是Series的容器),每一个Series都带有唯一的表头,用来标识不同的Series。
pandas的简单例子:
#-\*-coding:utf-8 -\*
import pandas as pd #通常用pd作为pandas的别名
s = pd.Series([1,2,3],index = ['a','b','c']) #创建一个序列s
d = pd.DataFrame([[1,2,3],[4,5,6]],columns=['a','b','c']) #创建一个表
d2 = pd.DataFrame(s) # 也可以用已有的序列来创建表格
print(d.head()) #预览前5行数据,3.x版本需要加上print
print(d.describe()) #数据的基本统计量,3.x版本需要加上print
#读取文件,注意文件的路径不能有中文,否则读取可能出错
pd.read_excel('data.xls') #读取Excel文件,创建DataFrame
pd.read_csv('data.csv',encoding='utf-8') #读取文本格式的数据,一般用encoding指定编码
2.3.5 StatsModels
相比于pandas而言,StatsModels更加注重数据的统计建模分析,使得Python有了一丝R语言的味道。StatsModels支持与pandas进行数据交互,与pandas进行组合,成为了Python下强大的数据挖掘组合。StatsModels依赖于pandas,也依赖于pandas所依赖的,同时还依赖于pasty(一个描述统计的库)。
使用StatsModels来进行ADF平稳性检验的例子:
#-\*-coding:utf-8 -\*
from statsmodels.tsa.stattools import adfuller as ADF #导入ADF检验
import numpy as np
print(ADF(np.random.rand(100))) #返回的结果是ADF值、p值等
2.3.6 Scikit-Learn
Scikit-Learn是Python下的一个强大的机器学习包,提供了完善的机器学习工具箱,包括数据预处理、分类、回归、聚类、预测、和模型分析等。Scikit-Learn依赖于numpy、SciPy、matplotlib,因此只要提前安装好这几个库然后按照Scikit-Learn基本上没有什么问题,安装方法和之前一样。
使用Scikit-Learn创建一个机器学习的模型:
#-\*-coding:utf-8 -\*
from sklearn.linear_model import LinearRegression #导入线性回归模型
model=LinearRegression() #建立线性回归模型
print(model)
(1)所有模型提供的接口有:
- model.fit():训练模型,对于监督模型来说是fit(X,y),对于非监督模型是fit(X)。
(2)监督模型提供的接口有:
- model.predict(X_new):预测新样本
- model.predict_proda(X_new):预测概率,仅对某些模型有用(比如LR)
- model.score():得分越高,fit越好
(3)非监督模型提供的接口有:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

**
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)
[外链图片转存中…(img-b5d7GYI2-1712950080623)]
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-cZRp4Q1C-1712950080623)]

















 471
471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









