




 文章介绍了Hive中两种主要的列式存储文件格式——ORC和Parquet,强调了它们在查询性能和数据组织上的优势。ORC文件以条带形式存储数据,包含索引和编码信息,而Parquet文件通过行组和列块进行数据划分。此外,文章还讨论了Hive表数据的压缩方法,包括在建表时设定压缩格式以及在计算过程中使用压缩来优化性能。
文章介绍了Hive中两种主要的列式存储文件格式——ORC和Parquet,强调了它们在查询性能和数据组织上的优势。ORC文件以条带形式存储数据,包含索引和编码信息,而Parquet文件通过行组和列块进行数据划分。此外,文章还讨论了Hive表数据的压缩方法,包括在建表时设定压缩格式以及在计算过程中使用压缩来优化性能。

hive文件格式:
概述:
为Hive表中的数据选择一个合适的文件格式,对提高查询性能的提高是十分有益的。Hive表数据的存储格式,可以选择text file、orc、parquet、sequence file等。
文本文件:
文本文件就是txt文件,我们默认的文件类型就是txt文件
ORC文件:
ORC介绍:
ORC(Optimized Row Columnar)file format是Hive 0.11版里引入的一种列式存储的文件格式。ORC文件能够提高Hive读写数据和处理数据的性能。
我们文件一般都是一个二维表,行式存储就是以一行数据为一个单位,存储在相邻的位置,列示存储是以一列数据为单位,一个单位内的数据放在相邻的位置。
如下图两种方式的比较:
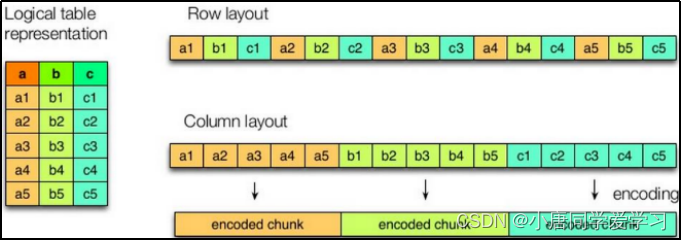
在日常使用的时候hive查询出来的大部分是大量列信息,少量使用where进行条件查询
orc格式在存储的过程中会在hive表上进行横向切分,分割成两次分别进行列式存储
对分割后的数据进行列式存储时,会把它存储到orc文件的一个strip(条带)中,剩下的数据存入其他条带中,条带中并不止存对应的列,还存有一个indexdata--索引(存放每列区(column)的最大值,最小值,行位置)(可以减少大量io操作)默认10000行记录一个索引。
在文件最后还存有一个StripeFooter(存放每个column的编码信息---在存入orc文件的时候并不会按照原表进行存储而是会进行编码存储)
在文件开头有一个header:ORC(可以用于判断文件类型)
文件的底部还有一个FileFooter(存储的有header的长度,各Strip的信息:strips的起始位置,索引长度,数据的长度,StripsFooter的长度等,还存储有各column的统计信息:最值,hashNull)
ORC文件还有一个PostScript,保存这FileFooter的长度,文件压缩的参数,文件的版本等信息。
还有一个区域用于保存Postscrip的长度(文件的最后一个字节)

读取ORC文件步骤:
一般读取ORC文件是从文件末尾开始,先进行读取最后一个字节(Postscript的长度),再通过得到的长度从倒数第二个字节进行向前推到Postscript的起始位置开始读取,从Postscript的数据中的得到File Footer的长度,再进行向前推进行访问,让后就可以根据File Footer中的内容进行定位。
建表语句:
create table orc_table
(column_specs)
stored as orc
tblproperties (property_name=property_value, ...);column_speccs是建表语句
tblproperties (property_name=property_v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1902
1902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











