





揭秘心跳与大脑的“密语”:从 0 到 1 实现睡眠期心电诱发电位(HEP)计算
引言:当你的大脑在“偷听”心跳
- 痛点切入: 你是否曾面对着海量的睡眠 EEG 数据,想要探究心与脑的神秘连接,却被复杂的信号伪迹和繁琐的处理流程劝退?心电信号(ECG)的伪迹像幽灵一样缠绕着你的脑电(EEG)数据,让你无法提取出微弱而宝贵的 HEP 信号。
- 核心观点: 计算心电诱发电位(HEP)是量化心脑交互的关键技术,尤其在睡眠研究中意义重大。尽管挑战重重,但遵循一个结构化的处理流程,我们可以系统性地从充满噪声的原始数据中“提炼”出清晰的 HEP。
- 收获预期: 读完本文,你将获得一个完整的、可实操的 HEP 计算流程图。你将学会如何:
- 预处理多模态生理数据(EEG, 心率, 睡眠分期)。
- 准确定位心跳事件(R-峰检测)。
- 从连续的 EEG 信号中分割(Epoching)出与心跳锁时的 HEP 片段。
- 为每个 HEP 片段打上准确的睡眠阶段标签,为后续的统计分析做好准备。
一、 HEP 是什么?为什么要在睡眠中研究它?
- 心脑交互的“信使”: 简单来说,HEP 就是你的大脑对每一次心跳的电位反应。它像是大脑在每一次心跳后产生的“回响”,反映了大脑对来自身体内部信号(特别是心脏)的感知能力,即“内感受”(Interoception)。
- 睡眠:研究“特质”的理想窗口: 白天,我们的大脑被各种外部信息轰炸。而睡眠,尤其是深度睡眠,提供了一个相对“纯净”的观测窗口。此时,外界干扰降到最低,计算出的 HEP更能反映个体稳定、持久的“特质性”心脑交互模式。

二、 挑战:在“风暴”中捕捉“蝴蝶”
计算睡眠期 HEP 就像在电闪雷鸣的暴风雨中,试图捕捉一只蝴蝶扇动翅膀的微小气流。
- 伪迹重重 (The Storm): 睡眠 EEG 充满了各种伪迹:
- 心电伪迹 (ECG Artifact): 心脏的电活动比大脑强得多,它的信号会直接“污染”EEG,尤其是在胸部附近的导联。
- 其他生理伪迹: 肌电 (EMG)、眼动 (EOG)、身体移动等都会产生远大于 HEP 信号的噪声。
- 信号微弱 (The Butterfly): HEP 本身的幅度非常小(微伏级别),很容易被噪声淹没。
- 多状态数据 (The Complexity): 一整晚的睡眠数据包含清醒、N1、N2、N3、REM 等多个阶段,需要将计算出的 HEP 与这些阶段精确对应。
三. 装备库:数据与工具概览
在开始之前,确保你拥有以下“装备”:
- 脑电数据:
.edf格式的原始 EEG 文件。 - 心率数据:
.csv格式的 RR 间期文件,记录了每次心跳(R-峰)的精确时间。 - 睡眠分期:
.txt或.csv格式的专家判读睡眠分期标签。 - 核心工具: 本文将以 Python 生态中的
MNE-Python或 MATLAB 中的FieldTrip/EEGLAB工具箱为例进行讲解。
四、HEP 计算实战:四步净化之旅
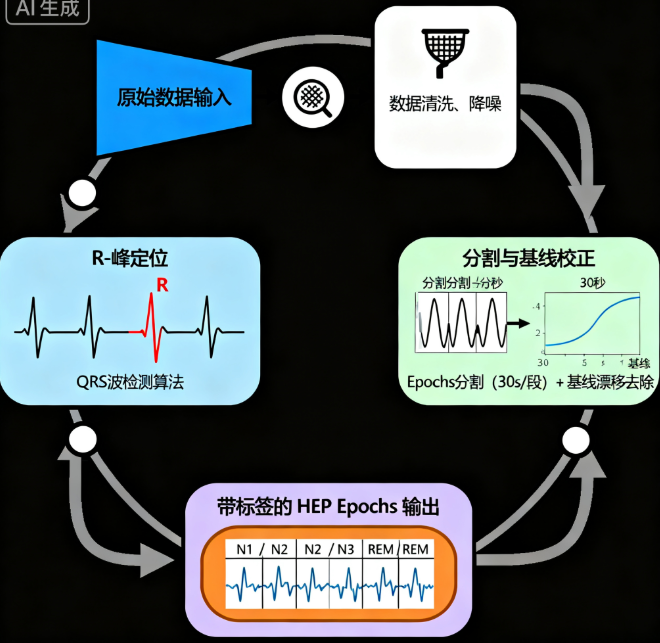
第 1 步:EEG 预处理 —— 大浪淘沙
这是整个流程中最关键的一步,目标是最大限度地去除噪声、保留有用信号。
- 数据加载: 读取
.edf文件,并指定电极导联位置。 - 滤波: 这是预处理的核心。
- 带阻滤波 (Notch Filter): 滤除 50Hz 或 60Hz 的工频干扰。
- 带通滤波 (Band-pass Filter): 通常设置为 0.3-35Hz,保留大部分神经活动,同时滤除低频漂移和高频肌肉噪声。
import mne
#假设 raw 是已加载的 MNE Raw 对象
raw.notch_filter(freqs=50) # 滤除 50Hz 工频干扰
raw.filter(l_freq=0.3, h_freq=35) # 0.3-35Hz 带通滤波
- 基线校正 (Baseline Correction): 对整个连续信号进行去基线处理,消除直流偏移。
第 2 步:R-峰检测 —— 定位心跳的“扳机”
我们需要精确知道每一次心跳发生的时间点,它就像是触发 HEP 事件的“扳机”。
- 如果已有 RR 间期数据: 这是最理想的情况。RR 间期数据已经包含了 R-峰的精确时间点。我们只需要将这些时间点加载进来即可。
- 如果只有原始 ECG/EEG 信号: 需要使用 R-峰自动检测算法。许多库(如
MNE、BioSPPy)都内置了成熟的算法。
import pandas as pd
#rr_intervals 是 R-R 间期的秒数列表
rr_df = pd.read_csv("rr_intervals.csv")
r_peak_times = rr_df['rr_interval_seconds'].cumsum() # 累加 R-R 间期得到每个 R 峰的时间点
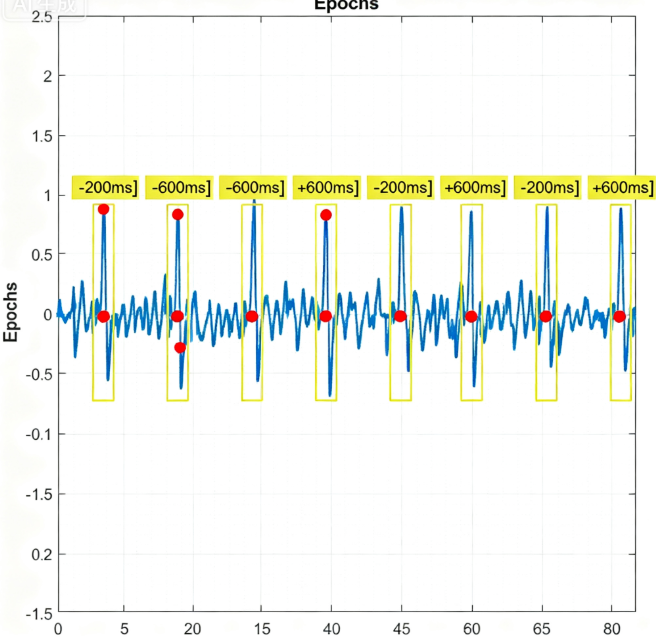
第 3 步:分段 (Epoching) —— 裁剪出 HEP 候选片段
现在,我们以每个 R-峰为中心,从预处理过的 EEG 数据中裁剪出一个个小片段。
-
定义时间窗口: HEP 的典型形态出现在 R-峰前后。一个常用的窗口是 R-峰前的 200ms 到 R-峰后的 600ms(即
tmin=-0.2,tmax=0.6)。- R-峰前的时段用于基线校正,可以消除每个片段自身的直流偏移。
- R-峰后的时段则包含了我们关心的 HEP 成分。
-
执行分段: 使用 R-峰时间点,在 EEG 数据上进行切割。
import mne
#r_peak_events 是一个符合 MNE 格式的事件数组
#tmin, tmax 定义了时间窗口
epochs = mne.Epochs(raw, events=r_peak_events, tmin=-0.2, tmax=0.6,
baseline=(-0.2, 0), preload=True)
注意:
baseline=(-0.2, 0)参数至关重要,它会用 R-峰前 200ms 的信号均值作为基线,并从整个片段中减去,确保了每个 HEP 的可比性。
第 4 步:打上标签 —— 每个 HEP 片段的“身份证明”
最后一步,我们需要知道每个 HEP 片段属于哪个睡眠阶段。
- 加载分期数据: 读取睡眠专家判读的分期结果。通常,这个文件会告诉我们每 30 秒属于哪个阶段(W, N1, N2, N3, REM)。
- 时间匹配: 遍历每一个 HEP Epoch,根据其发生的时间点,去睡眠分期文件中查找对应的睡眠阶段,并将其作为标签附加到这个 Epoch 上。
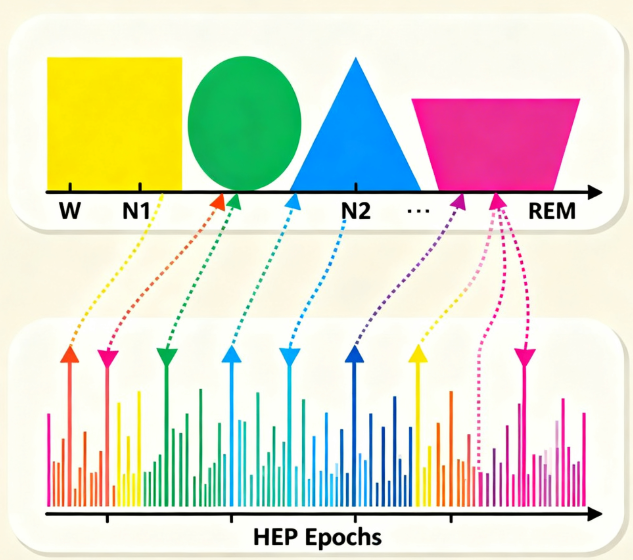
至此,你就得到了一组包含了干净信号、并且带有明确睡眠阶段标签的 HEP Epochs 数据。它们是后续进行统计分析、可视化和机器学习建模的宝贵“原料”。
总结与展望
本文我们完整地走了一遍从原始睡眠数据中计算 HEP 的核心流程,可以总结为“预处理 -> R-峰定位 -> 分段 -> 打标签”这四大步。每一步都像是精密的过滤和提纯,最终目的是从充满噪声的背景中,提取出反映心脑交互的微弱信号。
- 核心回顾:
- 滤波和基线校正是保证信号质量的基石。
- 精确的 R-峰检测 是所有后续分析的起点。
- Epoching 并进行片段基线校正,是形成可比性 HEP 的关键。
- 与睡眠分期的匹配,赋予了 HEP 生理意义。
这只是探索心脑交互的开始。有了这些处理好的 HEP 数据,你接下来可以探索更多有趣的问题,例如:不同睡眠阶段的 HEP 形态有何差异?HEP 的幅度或潜伏期是否与某些临床指标相关?
希望这篇指南能为你点亮在数据丛林中探索心脑奥秘的火把。

















 5
5

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









