






前言
最近准备学习行为识别相关的内容,而人体关键点检测算法一类行为识别算法的前置任务,因此决定先学习人体关键点检测相关算法。
本文先对人体关键点检测进行简单的介绍,直观说明关键点检测是什么;然后对人体关键点检测算法进行分类,并列举一些典型的、重要的算法,方便读者进一步学习;最后对各个算法进行理论和创新点的总结,抛砖引玉
在图像中检测人类是一项具有挑战性的任务,因为他们的外表多变,姿势多样。首先需要的是一个健壮的特征集,即使在困难的光照下,即使在杂乱无章的背景中,也可以清晰地分辨出人体的形状。对检测器性能的各种实现选择,采取“行人检测”(检测最多可见)。人在或多或少直立的姿势)作为一个测试用例。
话不多说,让我们进入人体姿态检测的学习吧!

一、人体关键点检测是什么?
人体关键点检测(Human Keypoints Detection)又称为人体姿态估计,是计算机视觉中一个相对基础的任务,是人体动作识别、行为分析、人机交互等的前置任务。一般情况下可以将人体关键点检测细分为单人/多人关键点检测、2D/3D关键点检测,同时有算法在完成关键点检测之后还会进行关键点的跟踪,也被称为人体姿态跟踪。
目前COCO keypoint track是人体关键点检测的权威公开比赛之一,COCO数据集中把人体关键点表示为17个关节,分别是鼻子,左右眼,左右耳,左右肩,左右肘,左右腕,左右臀,左右膝,左右脚踝。而人体关键点检测的任务就是从输入的图片中检测到人体及对应的关键点位置。
我从CPN和Objects as Points论文中随后截取了几张2D人体关键点检测的效果图,如下图所示。

二、人体关键点检测算法步骤
1.引入库
所需要的库如下:

2.算法概述
多人人体骨骼关键点检测主要有两个方向,一种是自上而下,一种是自下而上,其中自上而上的人体骨骼关键点定位算法主要包含两个部分,人体检测和单人人体关键点检测,即首先通过目标检测算法将每一个人检测出来,然后在检测框的基础上针对单个人做人体骨骼关键点检测,其中代表性算法有G-RMI, CFN, RMPE, Mask R-CNN, and CPN,目前在MSCOCO数据集上最好的效果是72.6%;自下而上的方法也包含两个部分,关键点检测和关键点聚类,即首先需要将图片中所有的关键点都检测出来,然后通过相关策略将所有的关键点聚类成不同的个体,其中对关键点之间关系进行建模的代表性算法有PAF, Associative Embedding, Part Segmentation, Mid-Range offsets,目前在MSCOCO数据集上最好的效果是68.7%。
Coordinate、Heatmap和Heatmap + Offsets
在介绍多人人体骨骼关键点检测算法之间,首先介绍一下关键点回归的Ground Truth的构建问题,主要有两种思路,Coordinate和Heatmap,Coordinate即直接将关键点坐标作为最后网络需要回归的目标,这种情况下可以直接得到每个坐标点的直接位置信息;Heatmap即将每一类坐标用一个概率图来表示,对图片中的每个像素位置都给一个概率,表示该点属于对应类别关键点的概率,比较自然的是,距离关键点位置越近的像素点的概率越接近1,距离关键点越远的像素点的概率越接近0,具体可以通过相应函数进行模拟,如Gaussian等,如果同一个像素位置距离不同关键点的距离大小不同,即相对于不同关键点该位置的概率不一样,这时可以取Max或Average,如下图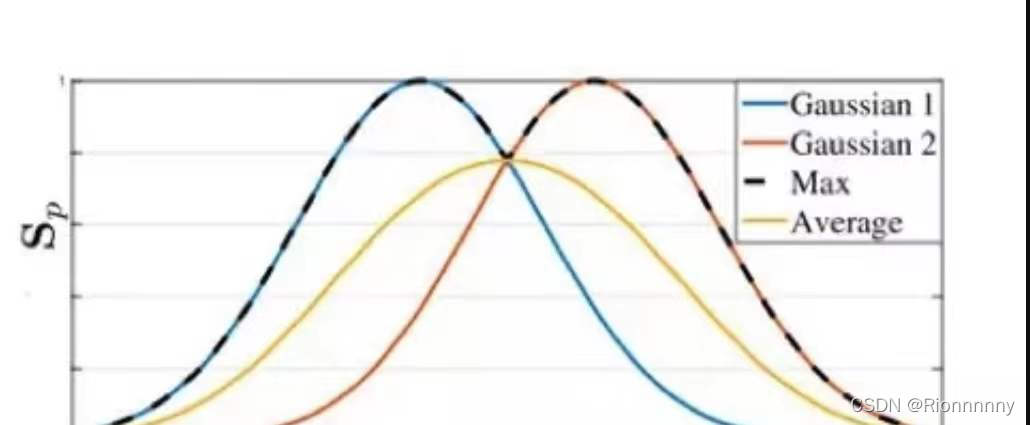
3.算法分析
对于两种Ground Truth的差别,Coordinate网络在本质上来说,需要回归的是每个关键点的一个相对于图片的offset,而长距离offset在实际学习过程中是很难回归的,误差较大,同时在训练中的过程,提供的监督信息较少,整个网络的收敛速度较慢;Heatmap网络直接回归出每一类关键点的概率,在一定程度上每一个点都提供了监督信息,网络能够较快的收敛,同时对每一个像素位置进行预测能够提高关键点的定位精度,在可视化方面,Heatmap也要优于Coordinate,除此之外,实践证明,Heatmap确实要远优于Coordinate,具体结构如下图所示。
自上而下(Top-Down)的人体骨骼关键点检测算法主要包含两个部分,目标检测和单人人体骨骼关键点检测,对于目标检测算法,这里不再进行描述,而对于关键点检测算法,首先需要注意的是关键点局部信息的区分性很弱,即背景中很容易会出现同样的局部区域造成混淆,所以需要考虑较大的感受野区域;其次人体不同关键点的检测的难易程度是不一样的,对于腰部、腿部这类关键点的检测要明显难于头部附近关键点的检测,所以不同的关键点可能需要区别对待;最后自上而下的人体关键点定位依赖于检测算法的提出的Proposals,会出现检测不准和重复检测等现象,大部分相关论文都是基于这三个特征去进行相关改进,接下来我将简要介绍其中几种经典的算法思路。
Convolutional Pose Machines:本论文将深度学习应用于人体姿态分析,同时用卷积图层表达纹理信息和空间信息。主要网络结构分为多个stage,其中第一个stage会产生初步的关键点的检测效果,接下来的几个stage均以前一个stage的预测输出和从原图提取的特征作为输入,进一步提高关键点的检测效果。具体的流程图如下图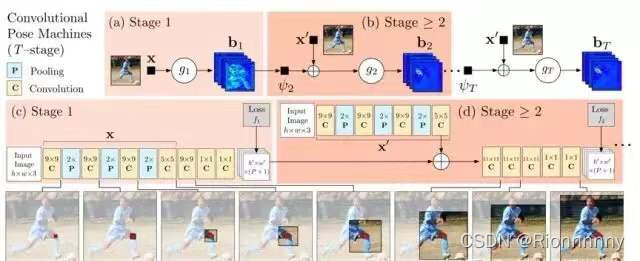
用各部件响应图来表达各部件之间的空间约束,响应图和特征图一起作为数据在网络中传递。人体关键点在空间上的先验分布会指导网络的学习,假如stage 1的预测结果中右肩关键点的预测结果是正确的,而右肘关键点的预测是错误的,那么在接下来的stage中肩和肘在空间上的先验分布会指导网络的学习。如下图
自下而上的人体关键点检测算法
自下而上(Bottom-Up)的人体骨骼关键点检测算法主要包含两个部分,关键点检测和关键点聚类,其中关键点检测和单人的关键点检测方法上是差不多的,区别在于这里的关键点检测需要将图片中所有类别的所有关键点全部检测出来,然后对这些关键点进行聚类处理,将不同人的不同关键点连接在一块,从而聚类产生不同的个体。而这方面的论文主要侧重于对关键点聚类方法的探索,即如何去构建不同关键点之间的关系,接下来我将介绍几种经典的方法。
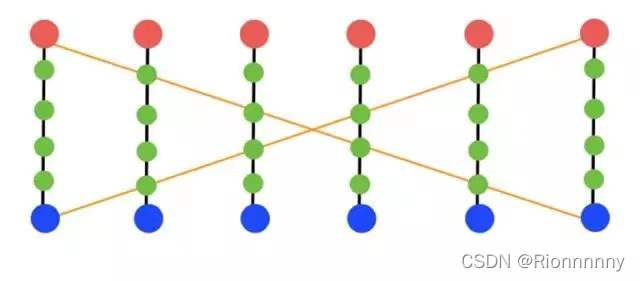
Part Segmentation:即对人体进行不同部位分割,而关键点都落在分割区域的特定位置,通过部位分割对关键点之间的关系进行建模,既可以显式的提供人体关键点的空间先验知识,指导网络的学习,同时在最后对不同人体关键点进行聚类时也能起到相应的连接关键点的作用。如下图
Part Affinity Fields:该方法通过对人体的不同肢体结构进行建模,使用向量场来模拟不同肢体结构,解决了单纯使用中间点是否在肢干上造成的错连问题。
4.代码展示
class ImageReader(object):
def __init__(self, file_names):
self.file_names = file_names
self.max_idx = len(file_names)
def __iter__(self):
self.idx = 0
return self
def __next__(self):
if self.idx == self.max_idx:
raise StopIteration
img = cv2.imread(self.file_names[self.idx], cv2.IMREAD_COLOR)
if img.size == 0:
raise IOError('Image {} cannot be read'.format(self.file_names[self.idx]))
self.idx = self.idx + 1
return img
class VideoReader(object):
def __init__(self, file_name):
self.file_name = file_name
try: # OpenCV needs int to read from webcam
self.file_name = int(file_name)
except ValueError:
pass
def __iter__(self):
self.cap = cv2.VideoCapture(self.file_name)
if not self.cap.isOpened():
raise IOError('Video {} cannot be opened'.format(self.file_name))
return self
def __next__(self):
was_read, img = self.cap.read()
if not was_read:
raise StopIteration
return img
def infer_fast(net, img, net_input_height_size, stride, upsample_ratio, cpu,
pad_value=(0, 0, 0), img_mean=np.array([128, 128, 128], np.float32), img_scale=np.float32(1/256)):
height, width, _ = img.shape
scale = net_input_height_size / height
scaled_img = cv2.resize(img, (0, 0), fx=scale, fy=scale, interpolation=cv2.INTER_LINEAR)
scaled_img = normalize(scaled_img, img_mean, img_scale)
min_dims = [net_input_height_size, max(scaled_img.shape[1], net_input_height_size)]
padded_img, pad = pad_width(scaled_img, stride, pad_value, min_dims)
tensor_img = torch.from_numpy(padded_img).permute(2, 0, 1).unsqueeze(0).float()
if not cpu:
tensor_img = tensor_img.cuda()
stages_output = net(tensor_img)
stage2_heatmaps = stages_output[-2]
heatmaps = np.transpose(stage2_heatmaps.squeeze().cpu().data.numpy(), (1, 2, 0))
heatmaps = cv2.resize(heatmaps, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
stage2_pafs = stages_output[-1]
pafs = np.transpose(stage2_pafs.squeeze().cpu().data.numpy(), (1, 2, 0))
pafs = cv2.resize(pafs, (0, 0), fx=upsample_ratio, fy=upsample_ratio, interpolation=cv2.INTER_CUBIC)
return heatmaps, pafs, scale, pad
def run_demo(net, image_provider, height_size, cpu, track, smooth):
net = net.eval()
if not cpu:
net = net.cuda()
stride = 8
upsample_ratio = 4
num_keypoints = Pose.num_kpts
previous_poses = []
delay = 1
for img in image_provider:
orig_img = img.copy()
heatmaps, pafs, scale, pad = infer_fast(net, img, height_size, stride, upsample_ratio, cpu)
total_keypoints_num = 0
all_keypoints_by_type = []
for kpt_idx in range(num_keypoints): # 19th for bg
total_keypoints_num += extract_keypoints(heatmaps[:, :, kpt_idx], all_keypoints_by_type, total_keypoints_num)
pose_entries, all_keypoints = group_keypoints(all_keypoints_by_type, pafs)
for kpt_id in range(all_keypoints.shape[0]):
all_keypoints[kpt_id, 0] = (all_keypoints[kpt_id, 0] * stride / upsample_ratio - pad[1]) / scale
all_keypoints[kpt_id, 1] = (all_keypoints[kpt_id, 1] * stride / upsample_ratio - pad[0]) / scale
current_poses = []
for n in range(len(pose_entries)):
if len(pose_entries[n]) == 0:
continue
pose_keypoints = np.ones((num_keypoints, 2), dtype=np.int32) * -1
for kpt_id in range(num_keypoints):
if pose_entries[n][kpt_id] != -1.0: # keypoint was found
pose_keypoints[kpt_id, 0] = int(all_keypoints[int(pose_entries[n][kpt_id]), 0])
pose_keypoints[kpt_id, 1] = int(all_keypoints[int(pose_entries[n][kpt_id]), 1])
pose = Pose(pose_keypoints, pose_entries[n][18])
current_poses.append(pose)
if track:
track_poses(previous_poses, current_poses, smooth=smooth)
previous_poses = current_poses
for pose in current_poses:
pose.draw(img)
img = cv2.addWeighted(orig_img, 0.6, img, 0.4, 0)
for pose in current_poses:
cv2.rectangle(img, (pose.bbox[0], pose.bbox[1]),
(pose.bbox[0] + pose.bbox[2], pose.bbox[1] + pose.bbox[3]), (0, 255, 0))
if track:
cv2.putText(img, 'id: {}'.format(pose.id), (pose.bbox[0], pose.bbox[1] - 16),
cv2.FONT_HERSHEY_COMPLEX, 0.5, (0, 0, 255))
cv2.imshow('Lightweight Human Pose Estimation Python Demo', img)
key = cv2.waitKey(delay)
if key == 27: # esc
return
elif key == 112: # 'p'
if delay == 1:
delay = 0
else:
delay = 1
if __name__ == '__main__':
parser = argparse.ArgumentParser(
description='''Lightweight human pose estimation python demo.
This is just for quick results preview.
Please, consider c++ demo for the best performance.''')
parser.add_argument('--checkpoint-path', type=str, required=True, help='path to the checkpoint')
parser.add_argument('--height-size', type=int, default=256, help='network input layer height size')
parser.add_argument('--video', type=str, default='', help='path to video file or camera id')
parser.add_argument('--images', nargs='+', default='', help='path to input image(s)')
parser.add_argument('--cpu', action='store_true', help='run network inference on cpu')
parser.add_argument('--track', type=int, default=1, help='track pose id in video')
parser.add_argument('--smooth', type=int, default=1, help='smooth pose keypoints')
args = parser.parse_args()
if args.video == '' and args.images == '':
raise ValueError('Either --video or --image has to be provided')
net = PoseEstimationWithMobileNet()
checkpoint = torch.load(args.checkpoint_path, map_location='cpu')
load_state(net, checkpoint)
frame_provider = ImageReader(args.images)
if args.video != '':
frame_provider = VideoReader(args.video)
else:
args.track = 0
run_demo(net, frame_provider, args.height_size, args.cpu, args.track, args.smooth)
总结
人体关键点检测至今仍然是计算机视觉领域较为活跃的一个研究方向,人体关键点检测算法还没有达到比较完美的效果,在较为复杂的场景下仍然会出现很多错误的检测结果。自上而下的关键点检测算法在效果上要明显好于自下而上的关键点检测算法,因为自上而下的检测方法加入了整个人体的一个空间先验。个人认为,自下而上的关键点定位算法没有显示的去建模整个人体的空间关系,而只是建模了局部的空间关系,以至于在效果上目前还远低于自上而上的关键点检测方法。














 1745
1745











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









