







- 查找算法
- 插值查找(按比例查找)
- 斐波那契查找(黄金分割法查找)
- 线性索引查找
以上部分知识比较简单就不特意做笔记了
重点学习一下 二叉排序树,平衡二叉树,多路查找树和哈希表。
二叉排序树(二叉查找树)
二叉排序树(Binary Sort Tree),它或者是一棵空树,或者是具有下列性质的二叉树:
- 若它的左子树不为空,则左子树上所有结点的值均小于它的根结构的值;
- 若它的右子树不为空,则右子树上所有结点的值均大于它的根结构的值;
- 它的左、右子树也分别为二叉排序树(递归)。
举例:下图就是用二叉排序树处理的一组数据
![]()

做出二叉排序表后,中序遍历(左根右)得到的序列就是有序序列了。
没写完 先空着,先跳过去学习哈希表
哈希表 (散列表)
为了避免一个一个比对,我们需要利用某种函数使得:
储存位置=f(关键字)
通过查找关键字不需要比较就可获得需要记录的储存位置——散列技术
散列技术是在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)。
这种对应关系f称为散列函数,又称为哈希( Hash )函数。采用散列技术将记录存储在一块连续的存储空间中 ,这块连续存储空间成为散列表或哈希表( Hash table )。
散列表的查找步骤
- 当存储记录时,通过散列函数计算出记录的散列地址
- 当查找记录时,我们通过同样的是散列函数计算记录的散列地址,并按此散列地址访问该记录
(数据之间没有任何逻辑关系,散列表主要是面向查找的存储结构)
两种情况不适合用散列表解决
- 同样的关键字对应多项纪录时
- 范围查找
还有一个问题就是——冲突 :简而言之就是地址相同,内容不同 ,我们应该尽可能的避免。
优秀散列表的特性
- 计算简单
- 分布均匀
散列函数的6种构造方法
1.直接定址法(最不常用)
取关键字的某个线性函数值为散列地址,即: f(key)= a*key + b。此方法简单但不常用。
2.数字分析法
抽取关键字的一部分来计算散列存储位置的方法。通常适合处理关键字位数比较多的情况。
3.平方取中法
知名达意,把关键字平方后取中间若干位数字作为散列地址。通常适用于不知道分布但位数不多的情况。
4.折叠法
将关键字从左到右分割成位数相等的几部分,然后将这几部分叠加求和,并按散列表表长取后几位作为散列地址。通常适用于不知道分布但位数比较多的情况。
5.除留余数法(最常用)
对于散列表长为m的散列函数计算公式为:
f(key) = key mod p (p<=m)
取好这个p至关重要!!!
若散列表表长为m,通常p为小于或等于表长(最好接近m)的最小质数或者不包含小于20质因子的合数。
6.随机数法
选择一个随机数,取关键字的随机函数值为它的散列地址。即:
f(key) = random(key)
这里的random是随机函数,当关键字的长度不等时,采用这个方法构造散列函数是比较合适的。
处理散列冲突的方法
1.开发定址法
一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入。
如果发生冲突再使用以下公式哦!
公式:fi(key) = (f(key)+di) MOD m (di=1,2,3...,m-1) (线性探测法)
(tip:公式中的f(key)是原本的散列函数)
优化:fi(key) = (f(key)+di) MOD m (di=1^2,-1^2, 2, -2^2...,q^2,-q^2,q<=m/2) (二次探测法)
(tip:一正一负:双向寻找空位 平方:不让关键字都聚集再某一块区域)
法三:fi(key) = (f(key)+di) MOD m (di是 由一个随机函数获得的数列) (随机探测法)
(关于随机函数随机种子的知识写在了这篇博客中 C/C++怎样产生随机数_m0_62742402的博客-CSDN博客)
2.再散列函数法
事先准备多个散列函数,如果发生冲突就换一个散列函数,这种方法使得关键字不产生聚集,但是增加了计算的时间。(小声嘀咕:我觉得这方法不咋地)
公式:fi(key) =RHi(key) (i=1,2,3,..k)(这里的RHi就是不同的散列函数)
3.链地址法(运用单链表)
将所以关键字为同义词的记录储存在一个单链表中,这种表被称为同义词子表
在散列表中只储存所有同义词子表的头指针,遇到冲突直接增加结点即可,但是这样带来了查找时需要遍历单链表的性能损耗。
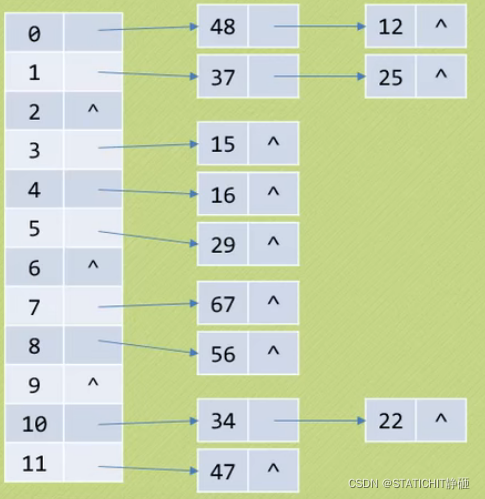
4.公共溢出区法
为所以的有冲突的关键字建立一个公共的溢出区来存放。在查找时,先于基本表的相应位置进行比对,如果不相等再去溢出表顺序查找,这种方法适合冲突不多的情况。

散列表的代码实现
首先来了解一个东西
c语言中status的定义为ypedef int status,status为int的一个同义词。
如:
typedef int status ;
#define ERROR -1
#define OK 1
第一,status在实际使用中是C语言规定的表示error,ok的标识符;
第二,status是为了表示一般性,实际使用时要把写status的地方换成对应的数据类型(如int,float,char等)
#define SUCCESS 1
#define UNSUCCESS 0
#define HASHSIZE 12 //定义散列表长度
#define NULLKEY -32768
typedef struct
{
int *elem; //数据元素的基址,动态分配数值
int count; //当前数据元素的个数
}HashTable;
//初始化散列表
Status IninHashTable(HashTable *H)
{
H->count = HASHSIZE;
H->elem = (int*)malloc(HASHSIZE * sizeod(int));
if(! H->elem)
{
return ERROR;
}
for(int i=0;i<HASHSIZE;i++)
{
H->elem[i] =NULLKEY;
}
return OK;
}
//散列函数
int Hash(int key)
{
return key % HASHSIZE; //使用除留余数法
}
//插入关键字到散列表
void InsertHash(HashTable *H,int key)
{
int addr;
addr=Hash(key); //求散列地址
while(H->elem[addr]!=NULLKEY)//如果不为空,则冲突出现
{
add =(addr + 1) % HASHSIZE;//开放定址法的线性探测
}
H->elem[addr]=key;
}
//散列表中查找关键字
Status SearchHash(HashTable *H,int key, int *addr)
{
*addr=Hash(key); //求散列地址
while(H.elem[*addr]!=key)
{
*addr=(*addr + 1) % HASHSIZE;
if(H.elem[*addr]==NULLKEY||*addr ==Hash(key))
return UNSUCCESS;
}
return SUCCESS;
}正好到此学完散列表,每次学完一个知识点都感觉懂得都懂了但还是不知道怎么下手做题,所以懂了不一定真的会用,so来做一道相关练习
(咱就是说我感觉书上学的东西做题完全不够用!!!!)
题目如下 :
奶牛们非常享受在牛栏中哞叫,因为她们可以听到她们哞声的回音。虽然有时候并不能完全听到完整的回音。Bessie曾经是一个出色的秘书,所以她精确地纪录了所有的哞叫声及其回声。她很好奇到底两个声音的重复部份有多长。
输入两个字符串(长度为1到80个字母),表示两个哞叫声。你要确定最长的重复部份的长度。两个字符串的重复部份指的是同时是一个字符串的前缀和另一个字符串的后缀的字符串。
我们通过一个例子来理解题目。考虑下面的两个哞声:
moyooyoxyzooo
yzoooqyasdfljkamo
第一个串的最后的部份"yzooo"跟第二个串的第一部份重复。第二个串的最后的部份"mo"跟第一个串的第一部份重复。所以"yzooo"跟"mo"都是这2个串的重复部份。其中,"yzooo"比较长,所以最长的重复部份的长度就是5。
输入格式
* 一共两行:每行都有moo的叫声或其回声
输出格式
* 共一行:具有单个整数的单行,该整数是一个字符串的前面和另一个字符串的末尾之间最长重叠的长度。
输入输出样例
输入 #1复制
abcxxxxabcxabcd abcdxabcxxxxabcx输出 #1复制
11说明/提示
'abcxxxxabcx' 是第一个字符串的前缀和第二个字符串的后缀。
思路:题目说的很明确,就是要找其中一个字符串的前缀和另一个字符串的后缀的最长重复部分长度,那么就只有两种情况。
- 第一个字符串的前缀与第二个字符串的后缀相同部分,得到一个长度len1.
- 第二个字符串的前缀与第一个字符串的后缀相同部分,得到一个长度len2.
然后再比较一下len1和len2即可。
这道题乍一看第一秒就会有思路,关键在于查找一个字符串的前缀和另一个字符串的后缀的最长重复部分的代码如何实现。
我想了下 与这个操作相似的是我们书上学的kmp中字串自己和自己匹配找前后缀相似度的部分。
那么这道题是找两个串之间的,然后前缀的开头是固定的,所以我们把第一个字符串定住,移动第二个字符串来找相匹配的最长后缀。
想到这里我写出来的是这个代码,乍一看好像有点道理,但是咱就是说,答案都输出不了😓
#include<bits/stdc++.h>
using namespace std;
char s1[100],s2[100];
int same[100];
int len1,len2,ans1,ans2,ans;
int fun(char *s1,int l1,char *s2,int l2)
{
int i=-1,j=0,m=0;
same[1]=-1;
while(i<l1 && j<l2)
{
if(i == -1 ||s1[i] == s2[j])
{
i++;
j++;
same[j]=i;
m=max(m,same[j]);
}
else
j=same[j];
}
return m;
}
int main()
{
cin>>s1>>s2;
len1=strlen(s1);
len2=strlen(s2);
//情况1:s1前缀,s2后缀
ans1=fun(s1,len1,s2,len2);
//情况2:s2前缀,s1后缀
ans2=fun(s2,len2,s1,len1);
ans=max(ans1,ans2);
cout<<ans;
return 0;
}
所以我觉得我每次对知识点的理解都不是真的理解了呜呜,我要能做出题来才是真的理解了吧。
然后很离谱的事情就发生了,我发现我上面写的是学完了哈希表来做一道题,然而我在想这道题的时候满脑子都说kmp,然后我就回想了下为什么我会把这道题写在哈希表的知识点下面,我发现是因为当时我扫了一眼这道题的标签是:

(我。。。。。。。。。。。。。。)
然后我发现题解里全是用哈希做的!!???????????!!!
(我。。。。。。。。。。。。。。)
然后终于我找到了一篇用kmp写的题解(!!!),我开始查看我方法为什么有问题。

然后我发现!前面这个想法是错的
“我想了下 与这个操作相似的是我们书上学的kmp中字串自己和自己匹配找前后缀相似度的部分。”
是因为本身kmp的创建前缀表and主子串匹配两个部分很像所以我误以为这道题和创建前缀表的部分相似,这实际上是个完整的kmp过程,分别讨论两种情况时,我们要把其中一个字符串作为主串,另一个字符串作为字串。
而且是用子串去匹配主串,当主串匹配完,此时子串的匹配长度就是我们要求的长度值
#include<bits/stdc++.h>
using namespace std;
char s1[100],s2[100];
int nextt[100];
int len1,len2,ans1,ans2;
void get_next(char str[],int len)
{
int i=0,j=-1;
nextt[0]=-1;
while(i<len)
{
if(j == -1 ||str[i] == str[j])
{
++i;
++j;
nextt[i]=j;
}
else
j=nextt[j];
}
}
int KMP(char *s1,int l1,char *s2,int l2)
{
get_next(s2,l2);
int i,j;
i=0;
j=0;
while(i<l1)
{
if(j == -1 ||s1[i] == s2[j])
{
i++;
j++;
}
else
j=nextt[j];
}
return j;
}
int main()
{
cin>>s1>>s2;
len1=strlen(s1);
len2=strlen(s2);
//情况1:s1前缀,s2后缀
ans1=KMP(s1,len1,s2,len2);
//情况2:s2前缀,s1后缀
ans2=KMP(s2,len2,s1,len1);
cout<<max(ans1,ans2);
return 0;
}等有时间再去琢磨下这道题怎么用哈希表解决吧。--2022.2.8
2020.2.9
又一天的学习后我发现还有个东西叫字符串哈希,书上的例子呀都是数字的哈希,然后上面这道题我也终于有了用哈希解决的思路:
就是两个字符串一个从前面开始逐个字符加上算哈希值一个从后面开始逐个加字符算哈希值,前后缀哈希值相等了说明找到相等部分的前后缀了。
然后呢对于这个哈希函数怎么设定大有其奥妙在里面。
先梳理一下字符串怎么算哈希值吧。
不需要用二维数组先把每个字符串存下来,可以输入一个字符串算一个哈希值,而哈希值也不是一次算出来而是一个一个字符添加进去算出整个字符串的哈希值,为了尽可能的避免冲突,这个哈希函数就会比较复杂,我们可以又取模又加乘数的,而用到的数最好用质数,这样更好避免冲突。
就比如拿下面这题为例
题目描述
如题,给定 N 个字符串(第 i 个字符串长度为 Mi,字符串内包含数字、大小写字母,大小写敏感),请求出 N 个字符串中共有多少个不同的字符串。
输入格式
第一行包含一个整数 N,为字符串的个数。
接下来 N 行每行包含一个字符串,为所提供的字符串。
输出格式
输出包含一行,包含一个整数,为不同的字符串个数。
输入输出样例
输入
5
abc
aaaa
abc
abcc
12345
输出
4
就面向题给样例吧
写好基本框架之后我们要有一个哈希函数 long long Hash(String s)返回的值就是字符串对应的哈希值(因为哈希值可能会很大所以要用long long或者unsigned long long)
long long hashs(char *s)
{
}主函数中输入n个字符串,每输入一次就求出他的哈希值存储在一个数组中,之后这个字符串也不需要再保留了直接丢了就行,所以放心地再次输入下一个字符串即可。
cin>>n;
for(int i=0;i<n;i++)
{
cin>>str[i];
ha[i]=hashs(str);
}怎么得到哈希值呢,前面说了一个一个字符弄进去(有一点点像前缀和的思想吧,原理像,公式完全不一样哦)
long long hashs(char s[])
{
int len=strlen(s);
long long hs=0;
for(int i=0;i<len;i++)//前缀和的思想
{
hs=(hs*base+(long long)s[i])%mod;
}
return hs;
}其中
#define base 131
#define mod 19260817这好像是个什么进制选择,我也不太清楚我都不知道他们取这个数是怎么想来的,难道就是依据质数和大一点的想法嘛,然后×的这个数base我看大家都用131 那我也用131吧
我感觉好像就是把字符串的字符用ascall码代入然后转换进制的样子..是这样嘛(?)
总之就是通过这么一个好复杂的函数把字符串给转化了,并且尽可能的减小了冲突的可能,然后每个字符串都对应了一个哈希值了(存在数组中),如果关键词本身一模一样哈希值就会一样,所以我们可以把各个哈希值排个序(一键sort!)题目只问我们有多少个不同的字符串,那么从第二个起如果当前哈希值和前一个不一样就加一就好了!(最后的答案记得还要加1)
补充:
map函数
map的底层原理是很多个散列表。map可以把一种类型数据转换为另一种类型数据,也可以同类型转换,一键加密。可以把字符串作为下标合理化。非常灵活。
- 进制hash(字符串hash)
学习过程中常遇到的base指的是进制,处理方法是把字符串中的每一个字符当作进制上的一位数字,通过进制转换操作把字符串变成一个base进制值,该值也作为字符串的哈希值
公式:ha=(ha*base+(long long)s[i])% mod;
base通常取131或13131,mod尽可能取大,也可以最后将ha值再&0x7ffff以保证不溢出。
#include<bits/stdc++.h>
using namespace std;
#define base 131
#define mod 19260817
int n,ans;
char str[11000];
long long int ha[11000];
long long hashs(char s[])
{
int len=strlen(s);
long long hs=0;
for(int i=0;i<len;i++)//前缀和的思想
{
hs=(hs*base+(long long)s[i])%mod;
}
return hs;
}
int main()
{
cin>>n;
for(int i=0;i<n;i++)
{
cin>>str;
ha[i]=hashs(str);
cout<<ha[i]<<endl;
}
sort(ha,ha+n);
//for(int i=0;i<5;i++)
// cout<<ha[i]<<endl;
for(int i=1;i<n;i++)
{
if(ha[i]!=ha[i-1])
ans++;
}
cout<<ans+1;
return 0;
}
然后!
不知道为什么只ac80!!!!!!!!!!
然后我都准备去睡觉了,然后我随便在mod也就是19260817这个数字中间加了几个数字,然后就ac100了!!!离谱,看来这个数是要越大越好啊!,所以上面这个代码,第四行再多打几个数字就能过了!完事!
--2022.2.10--
然后又是一道哈希题:
题目背景
XS中学化学竞赛组教练是一个酷爱炉石的人。
他会一边搓炉石一边点名以至于有一天他连续点到了某个同学两次,然后正好被路过的校长发现了然后就是一顿欧拉欧拉欧拉(详情请见已结束比赛 CON900)。
题目描述
这之后校长任命你为特派探员,每天记录他的点名。校长会提供化学竞赛学生的人数和名单,而你需要告诉校长他有没有点错名。(为什么不直接不让他玩炉石。)
输入格式
第一行一个整数 nn,表示班上人数。
接下来 nn 行,每行一个字符串表示其名字(互不相同,且只含小写字母,长度不超过 5050)。
第 n+2n+2 行一个整数 mm,表示教练报的名字个数。
接下来 mm 行,每行一个字符串表示教练报的名字(只含小写字母,且长度不超过 5050)。
输出格式
对于每个教练报的名字,输出一行。
如果该名字正确且是第一次出现,输出
OK,如果该名字错误,输出WRONG,如果该名字正确但不是第一次出现,输出REPEAT。输入输出样例
输入
5 a b c ad acd 3 a a e输出
OK REPEAT WRONG
这道题想要不时间超限肯定是要建立哈希表的,可是我只会数字的哈希表创建,不会字符串的哈希表创建,我改代码改的我都要郁郁了,心情非常的烦躁结果这个时候又跑题了!!!!
我发现了一个好东西----------map映射
(使用map要加#include<map>)
简而言之 他的用法之一(我举例子来体现)

这东西可太好用了吧,map yyds好吧!!
这道折磨我的题直接变成一道小天使
#include<bits/stdc++.h>
using namespace std;
#include<map>
map<string,int>word;//初始化默认int值为0
string s;
int n,m;
int main()
{
cin>>n;
while(n--)
{
cin>>s;
word[s]=1;//存在的名字都对应1
}
cin>>m;
while(m--)
{
cin>>s;
if(word[s] == 1)
{
cout<<"OK"<<endl;
word[s]=2;//喊过这个名字了就把他对应为2
}
else if(word[s] == 2)
cout<<"REPEAT"<<endl;
else
cout<<"WRONG"<<endl;
}
return 0;
}














 547
547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









