






在电商平台中,用户评论是非常重要的数据,它可以帮助我们了解商品的优缺点、用户的使用体验等。本文将介绍如何使用 Python 爬取京东商品的评论数据,并将数据保存为 CSV 文件。我们将从京东商品评论页面获取评论内容、评分、用户昵称、评论时间等信息,并额外爬取每条评论的图片数量。
首先给出完成的源代码:
import requests
import csv
import json
import time
# 创建文件对象
f = open('data.csv', mode='w', encoding='utf-8-sig', newline='')
# 更新 fieldnames,添加 imageCount
csv_writer = csv.DictWriter(f, fieldnames=['nickname', 'score', 'content', 'productColor', 'creationTime', 'imageCount'])
csv_writer.writeheader()
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
# 基础URL
base_url = 'https://club.jd.com/comment/productPageComments.action'
# 构建循环爬取 1-5 分评论
for score in range(1, 6): # 1-5 分
print(f'正在采集 {score} 分的评论数据')
params = {
'productId': '100142621600', # 商品ID
'score': score, # 评分类型(1-5 分)
'sortType': 5, # 排序类型(5表示推荐排序)
'page': 0, # 页码
'pageSize': 10, # 每页评论数量
'isShadowSku': 0, # 是否影子商品
'fold': 1 # 是否折叠
}
# 构建循环翻页
for page in range(1, 6): # 每分爬取前 5 页
print(f'正在采集第{page}页的数据内容')
params['page'] = page
# 发送请求
response = requests.get(base_url, params=params, headers=headers)
if response.status_code != 200:
print(f'请求失败,状态码:{response.status_code}')
continue
# 解析JSON数据
json_data = response.json()
# 提取评论所在列表
comments = json_data['comments']
# 遍历评论
for index in comments:
# 提取具体评论信息, 保存字典
dit = {
'nickname': index.get('nickname', ''), # 昵称
'score': index.get('score', ''), # 评分
'content': index.get('content', ''), # 评论内容
'productColor': index.get('productColor', ''), # 产品颜色
'creationTime': index.get('creationTime', ''), # 评论时间
'imageCount': len(index.get('images', [])) # 图片数量
}
# 写入数据
csv_writer.writerow(dit)
print(dit)
# 防止请求过快,适当延时
time.sleep(1)
# 关闭文件
f.close()运行结果:
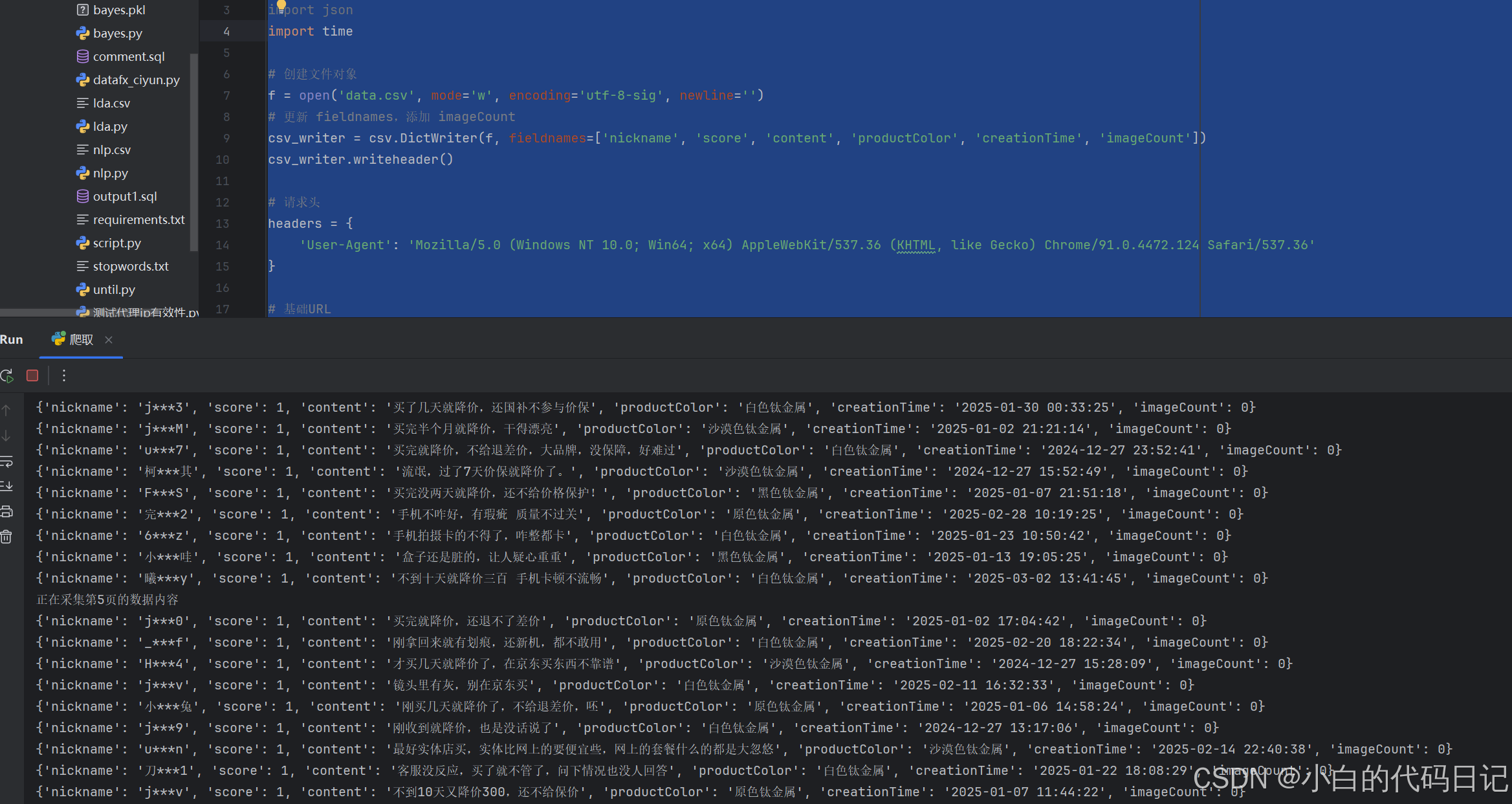
接下来我们一步步分析代码是如何生成的
1. 准备工作
在开始之前,我们需要安装以下 Python 库:
-
requests:用于发送 HTTP 请求。 -
csv:用于处理 CSV 文件。 -
json:用于解析 JSON 数据。 -
time:用于设置请求间隔,防止被封禁
你可以通过以下命令安装这些库:
pip install requests
2. 分析京东评论接口
京东的商品评论数据是通过 AJAX 请求加载的,我们可以通过浏览器的开发者工具(F12)找到评论数据的接口。经过分析,我们发现评论数据的接口如下:
https://club.jd.com/comment/productPageComments.action
该接口支持以下参数:
-
productId:商品 ID。 -
score:评分类型(1-5 分)。 -
sortType:排序类型(5 表示推荐排序)。 -
page:页码。 -
pageSize:每页评论数量。 -
isShadowSku:是否影子商品。 -
fold:是否折叠。
3. 编写爬虫代码
接下来,我们编写 Python 代码来爬取评论数据并保存为 CSV 文件。
3.1 导入库
首先,导入所需的库:
import requests
import csv
import json
import time3.2 创建 CSV 文件
我们使用 csv.DictWriter 来创建一个 CSV 文件,并定义表头:
# 创建文件对象
f = open('data.csv', mode='w', encoding='utf-8-sig', newline='')
# 定义表头
csv_writer = csv.DictWriter(f, fieldnames=['nickname', 'score', 'content', 'productColor', 'creationTime', 'imageCount'])
csv_writer.writeheader()3.3 设置请求头
为了模拟浏览器请求,我们需要设置请求头:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
3.4 构建请求参数
我们使用循环来爬取 1-5 分的评论数据,并设置每页爬取 10 条评论,总共爬取 5 页:
# 基础URL
base_url = 'https://club.jd.com/comment/productPageComments.action'
# 构建循环爬取 1-5 分评论
for score in range(1, 6): # 1-5 分
print(f'正在采集 {score} 分的评论数据')
params = {
'productId': '100142621600', # 商品ID
'score': score, # 评分类型(1-5 分)
'sortType': 5, # 排序类型(5表示推荐排序)
'page': 0, # 页码
'pageSize': 10, # 每页评论数量
'isShadowSku': 0, # 是否影子商品
'fold': 1 # 是否折叠
}3.5 发送请求并解析数据
我们使用 requests.get 发送请求,并解析返回的 JSON 数据:
# 构建循环翻页
for page in range(1, 6): # 每分爬取前 5 页
print(f'正在采集第{page}页的数据内容')
params['page'] = page
# 发送请求
response = requests.get(base_url, params=params, headers=headers)
if response.status_code != 200:
print(f'请求失败,状态码:{response.status_code}')
continue
# 解析JSON数据
json_data = response.json()
# 提取评论所在列表
comments = json_data['comments']3.6 提取评论信息并保存到 CSV
我们遍历每条评论,提取所需的信息,并将其保存到 CSV 文件中:
# 遍历评论
for index in comments:
# 提取具体评论信息, 保存字典
dit = {
'nickname': index.get('nickname', ''), # 昵称
'score': index.get('score', ''), # 评分
'content': index.get('content', ''), # 评论内容
'productColor': index.get('productColor', ''), # 产品颜色
'creationTime': index.get('creationTime', ''), # 评论时间
'imageCount': len(index.get('images', [])) # 图片数量
}
# 写入数据
csv_writer.writerow(dit)
print(dit)
# 防止请求过快,适当延时
time.sleep(1)
3.7 关闭文件
最后,关闭 CSV 文件
制作不易,如果这篇文章帮到您,给博主一个小小的赞吧吧😃😃😃😃

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









