




我当时是跟着3D Gaussian Splatting复现-CSDN博客进行的项目复现,本文主要记录一些对3DGS的项目理解。
代码中关键步骤主要是以下两部:
python convert.py -s datapython train.py -s data -m data/output一、convert.py
其中convert.py中流程大致可分为以下五步
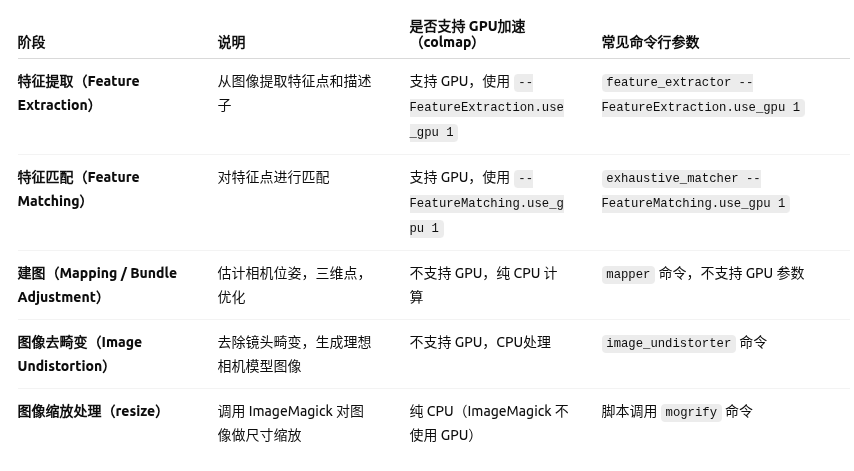
以上前四步都是对colmap的调用,其中前两部可以调用gpu,后三部纯cpu运算。
第一步、特征提取
从输入图像中提取特征点,将图像元信息(大小、相机)、关键点、描述子写入database.db

第二部、特征匹配
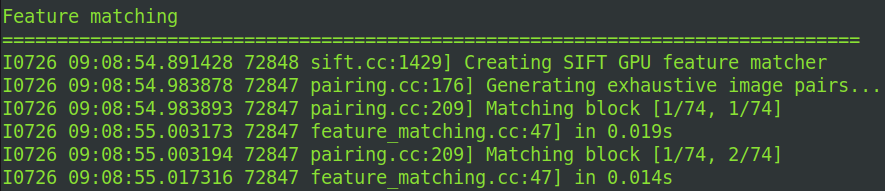
在不同图像间匹配特征点,将图像对之间的匹配信息(匹配点对)写入database.db。我当时很好奇为什么我输入了3669张图,但是进行匹配的时候只有74张,后来了解到这是COLMAP在特征匹配阶段将图像对分组后的 块数量(Blocks),用于 并行匹配优化,而非筛选后的图像数。74是分块数量,由COLMAP根据图像数量和硬件资源自动计算得出。COLMAP的 Exhaustive Matching(穷举匹配) 会:
- 计算所有可能的图像对:对于3669张图,理论上有
3669×3668/2 ≈ 6.7百万对需要匹配。 - 分块处理:为避免内存爆炸和加速匹配,COLMAP将图像对划分为多个块(Blocks),每个块包含一定数量的图像对:
- 日志中的
Matching block [1/74, 1/74]表示当前正在匹配 第1个块与第1个块 的图像对。 - 这里的 74×74 是分块策略的结果(总块数=74,每个块包含约
3669/74≈50张图像)。
- 日志中的
避免一次性加载所有特征点导致OOM(尤其对GPU内存)。便于并行加速,不同块可分配到多个线程或GPU核心同时处理。
 第三部、稀疏建图
第三部、稀疏建图
COLMAP 使用 Ceres Solver (非线性优化库)来执行非线性最小二乘优化,而 Ceres 是一个 纯 CPU 的库。稀疏重建是COLMAP的核心步骤,通过 捆绑调整(Bundle Adj
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









