






在实际工作中,经常有人问,7B、14B 或 70B 的模型需要多大的显存才能推理?如果微调他们又需要多大的显存呢?
为了回答这个问题整理一份训练或推理需要显存的计算方式。如果大家对具体细节不感兴趣,可以直接参考经验法则评估推理或训练所需要的资源。
更简单的方式可以通过工具或者 huggface 官网计算推理/训练需要的显存工具在线评估。
01
数据精度
开始介绍之前,先说一个重要的概念——数据精度。数据精度指的是信息表示的精细程度,在计算机中是由数据类型和其位数决定的。
如果想要计算显存,从“原子”层面来看,就需要知道我们的使用数据的精度,因为精度代表了数据存储的方式,决定了一个数据占多少 bit。
目前,精度主要有以下几种:
- 4 Bytes: FP32 / float32 / 32-bit
- 2 Bytes: FP16 / float16 / bfloat16 / 16-bit
- 1 Byte: int8 / 8-bit
- 0.5 Bytes: int4 / 4-bit
02
经验法则
推理: 参数量 * 精度。
例如,假设模型都是 16-bit 权重发布的,也就是说一个参数消耗 16-bit 或 2 Bytes 的内存,模型的参数量为 70B,基于上述经验法则,推理最低内存需要 70B * 2Bytes = 140G。
训练: 4 - 6 倍的推理资源。
03
推理
在模型推理阶段,需要的资源主要有三部分:
- 模型的权重
- KV Cache
- 激活(在推理过程中创建的张量)
(1)模型权重
加载模型权重(即模型大小)占用资源主要依赖于模型的参数量和精度。其中,参数量基本不变,精度可以通过模型量化技术进行优化。
尽管量化会影响模型的性能,但相比于选择更高精度的小模型来说,量化技术更受青睐。
公式:模型的大小 = 模型的参数量 * 精度
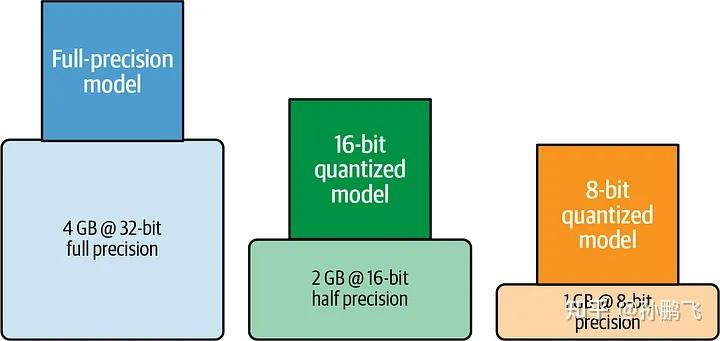
十亿参数模型在 32 位、16 位和 8 位精度下所需的近似 GPU 内存[2]
(2)KV Cache
在 Transformer 的解码阶段,每次推理生成一个 token,依赖于之前的 token 结果,如果每次都对所有 token 重新计算一次,代价非常大。为了避免重新计算,通过 KV Cache 技术将其缓存到 GPU 内存中。
**公式:**KV Cache = 2 * Batch Size * Sequence Length * Number of Layers * Hidden Size * Precision
注意:第一个因子 2 解释了 K 和 V 矩阵。通常,在 Transformer 中,Hidden Size 和 Number of Layers 的值可以在模型相关的配置文件中找到。
(3)激活内存
在模型的前向传播过程中,必须存储中间激活值。这些激活值代表了神经网络中每层的数据在向前传播时的输出。它们必须保持为 FP32 格式,以避免数值爆炸并确保收敛。
**公式 :**Activation Memory = Batch Size * Sequence Length * Hidden Size * (34 + (5 * Sequence Length * Number of attention heads) / (Hidden Size))
04
训练
训练阶段所需的资源,除了上述介绍的模型权重、KV Cache 和激活内存之外,还需要存储优化器和梯度状态,因此,训练比推理需要更多的资源。
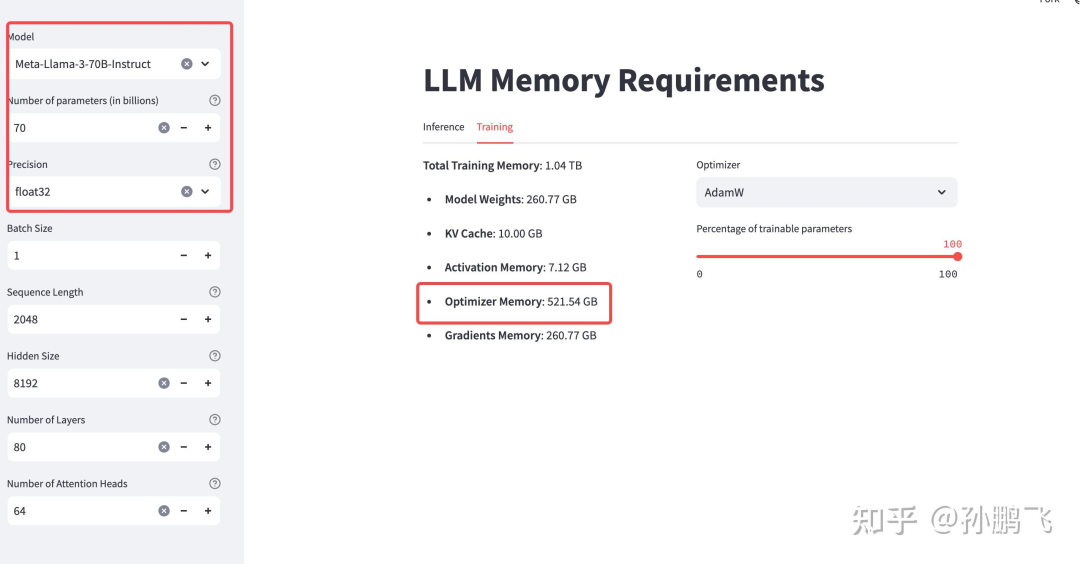
(1)优化器内存
优化器需要资源来存储参数和辅助变量。这些变量包括诸如 Adam 或 SGD 等优化算法使用的动量和方差等参数。这取决于优化状态的数量及其精度。
例如,AdamW 优化器是最流行的微调 llm,它为模型的每个参数创建并存储 2 个新参数。如果我们有一个 70B 的模型,优化器将创建 140B 的新参数!
假设优化器的参数为 float32,即每个参数占用 4 字节的内存。优化器至少需要 140B * 4 Bytes = 516 G 的资源。
其中,不同优化器的状态数量如下:
- AdamW (2 states): 8 Bytes per parameter
- AdamW (bitsandbytes Quantized): 2 Bytes per parameter
- SGD (1 state): 4 Bytes per parameter
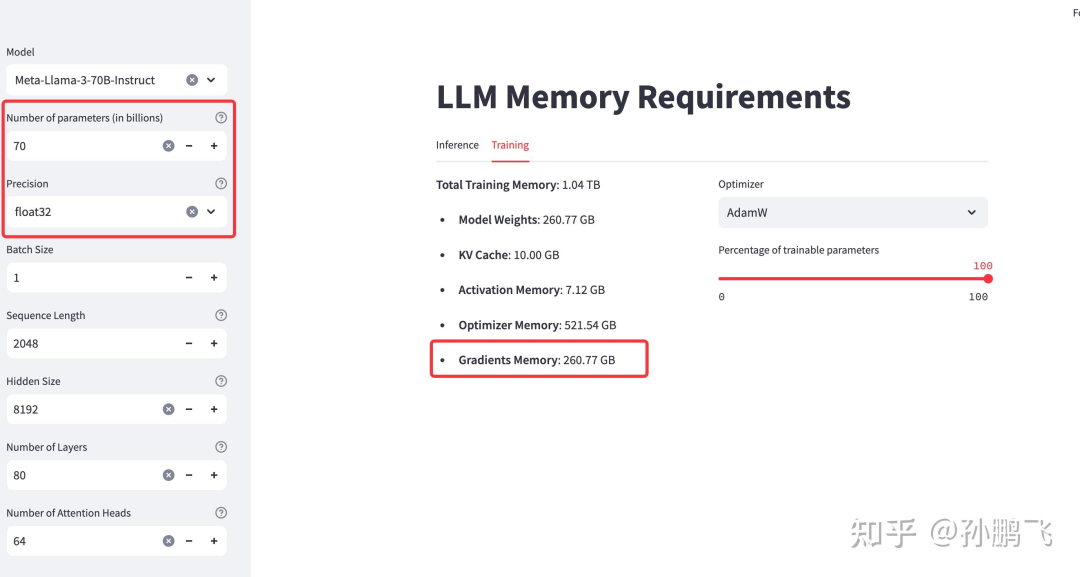
(2)梯度
在模型的反向传播过程中计算梯度值。它们表示损失函数相对于每个模型参数的变化率,对于在优化过程中更新参数至关重要。作为激活值,它们必须存储在 FP32 中以保持数值稳定性 。
因此,每个参数占用4字节的内存 。例如,一个 70B 的模型,计算梯度所需的内存需要 70B * 4 Bytes = 280 G左右。
05
总结
在本文中,我们介绍的评估方法,都是基于 Transformer 架构推算的,该评估方法不适合 Transformer 以外的其他体系结构。
同时,目前存在大量的框架、模型和优化技术,估计运行大型语言模型的确切内存可能很困难。然而,本文可作为估计执行 LLM 推理和训练所需内存资源的起点。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
😝有需要的小伙伴,可以VX扫描下方二维码免费领取🆓

👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型落地应用案例PPT👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)


👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习
这份完整版的 AI 大模型学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
😝有需要的小伙伴,可以Vx扫描下方二维码免费领取🆓
















 483
483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









