







文章目录
前言
对urllib.request.urlopen()和requests.get()应用的区别
正文
提示:以下是本篇文章正文内容,下面案例可供参考
爬虫爬取时,我们可以使用urllib.urlopen()和requests.get()方法去请求或获取一个网页的源代码。
说明
urlopen打开URL网址,url参数可以是一个字符串url或者是一个Request对象,返回的是
http.client.HTTPResponse对象.http.client.HTTPResponse对象大概包括read()、readinto()、getheader()、getheaders()、fileno()、msg、version、status、reason、debuglevel和closed函数,其实一般而言使用read()函数后还需要decode()函数,返回的网页内容实际上是没有被解码或的,在read()得到内容后通过指定decode()函数参数,可以使用对应的解码方式。
requests.get()方法请求了站点的网址,然后打印出了返回结果的类型,状态码,编码方式,Cookies等内容
URL是什么
统一资源定位系统(uniform resource locator;URL)是因特网的万维网服务程序上用于指定信息位置的表示方法。就像是文件目录一样,可以理解为一个链接
Request库:
构造一个向服务器请求资源的url对象,这个对象是Request库内部生成的。这时候的r返回的是一个包含服务器资源的Response对象。包含从服务器返回的所有的相关资源。
get函数完整使用方法的三个参数:

url:获取url链接
params:url中的参数,字典格式,例如url链接后的path在下面举例
**kwargs:12个控制访问的参数
Response对象常用的属性:
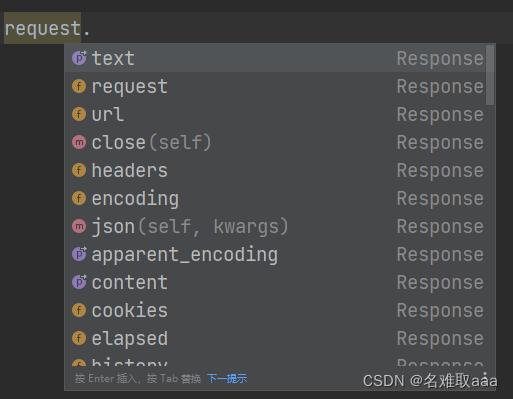
.text:响应内容的字符串形式,即url对应页面内容,可以看成页面源代码
.encoding:指定响应内容的编码形方式(在header里看,例如:)
.apparent_encoding:从内容中分析出响应内容的编码方式
.json():返回结果的JSON对象(如果结果是以JSON格式编写的,否则返回错误)
.close:关闭请求
.content:响应内容的二进制形式
.reason:状态原因
.cookies:返回cookies
post函数完整使用方法的三个参数
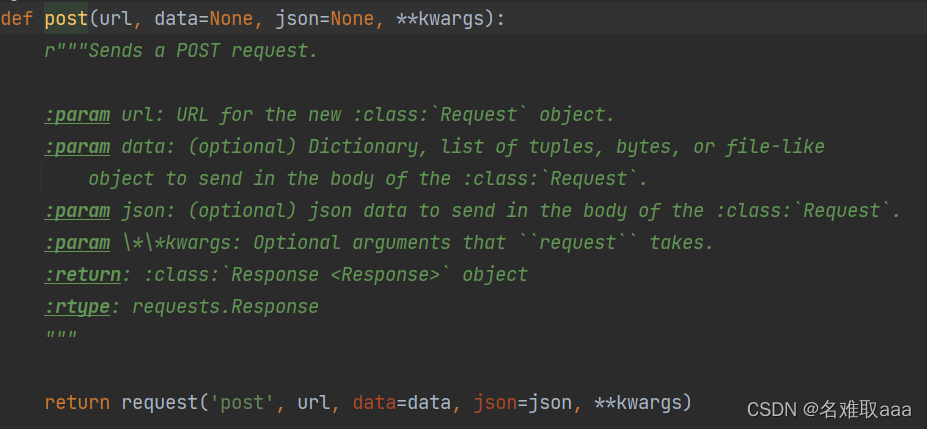
发送POST请求,发送的数据必须放在字典中,通过data参数进行传参
举例使用说明
GET
requests库
requests.get()简单用法
import requests
# GET
url = f"https://www.douban.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"
}
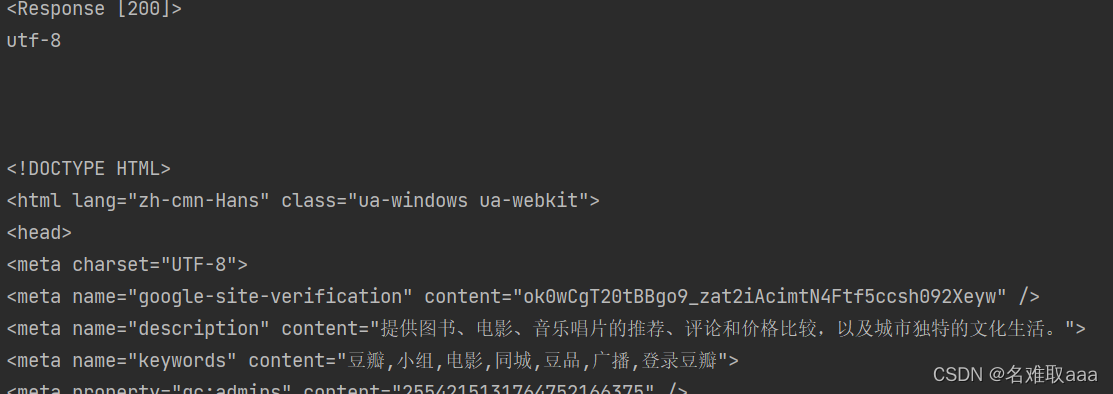
request = requests.get(url, headers=headers)
print(request)
print(request.apparent_encoding) # 从内容中分析出响应内容的编码方式
# request.encoding = "utf-8" # 指定字符集<meta charset="UTF-8">
print(request.text)
将url链接和封装好的headers字典(防止服务器拦截)传给requests.get()方法,例子中将状态码,编码方式和页面源代码分别打印出来,其他方法同理。
结果:
url拼接封装path
# url = "https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0&genres=喜剧" # 原网址
url = "https://movie.douban.com/j/new_search_subjects"
# 重新封装
param = {
"sort": "U",
"range": "0,10",
"tags": "",
"start": "0",
"genres": "喜剧",
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"
}
response = requests.get(url=url, params=param, headers=headers)
print(response.request.url)
print(response.json())
response.close() # 关掉response
将url链接和封装好的headers字典(防止服务器拦截)以及param(封装好Query String parameters中的参数)传给requests.get()方法,例子中打印拼接后的url和页面源代码以json打印出来,其他方法同理。
结果:

urllib库
import urllib
# GET
url = f"https://www.douban.com"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"
}
request = urllib.request.Request(url, headers=headers)
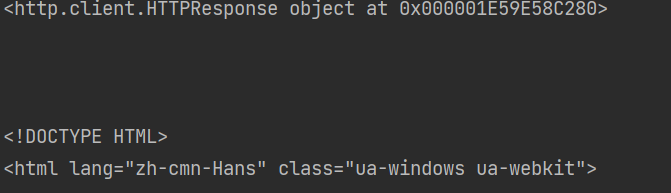
response = urllib.request.urlopen(request)
print(response)
print(response.read().decode("utf-8"))
将url链接和封装好的headers字典传给urllib.request.Request()方法打包(防止服务器拦截),将打包好的request对象传给urllib.request.urlopen()方法返回一个response对象,例子中打印response对象和用.read() 方法得到页面源代码用.decode()方法解码为utf-8(不然会有乱码)并打印出来
结果:
POST
requests库
requests.post()
# POST
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的英文单词:")
data = {
"kw": s
}
# 发送POST请求,发送的数据必须放在字典中,通过data参数进行传参
request = requests.post(url=url, data=data)
print(request.text, "\n")
print(request.json()) # 将服务器返回的内容直接处理成json() => dict
将url链接和封装好的data字典传给requests.get()方法,例子中将得到的源代码以text和.json()方法分别打印出来可以看出区别
结果:

urllib库
import urllib.parse
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36"
}
data = bytes(urllib.parse.urlencode({'kw':s}),encoding="utf-8")
request = urllib.request.Request(url=url,data=data,headers=headers,method="POST")
response = urllib.request.urlopen(request)
print(response.read().decode("utf-8"))
导入urllib.parse,用urllib.parse.urlencode()方法 将返回值转为bytes传给urllib.request.Request()封装为POST然后传给urllib.request.urlopen()并打印得到的数据
结果:

总结
以上就是今天要讲的内容,本文仅仅简单介绍了urllib.open和requests.get()的使用和区别,得到页面源代码是爬虫的第一步,python提供了大量能使我们快速便捷地处理数据的函数和方法。














 2120
2120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









