




在存储系统的log日志中,经常会看到 check condition的字样,有中文界面直接翻译为“检查情况”,这个翻译太抽象了,不是很认可,还不如不翻译。下面是联想DE6000存储的日志部分截图:
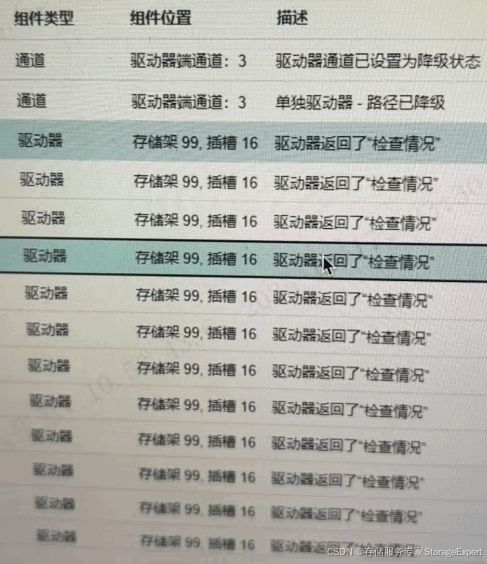
这个日志是说在插槽(slot)16位置的驱动器(driver),这里的驱动器就是HDD磁盘,磁盘架99就是机头扩展柜上有check conditon发生。那么问题来了,这个check condition是什么含义呢?出现这个代表了什么?是这个磁盘有故障吗?下面我们就对这个问题一一进行分析。
码字不易,欢迎点赞、转发、关注,添加v: StorageExpert,下次更新不迷路。
在存储系统中,"check condition" 是 SCSI(Small Computer System Interface)协议 中的一个重要状态码。Check Condition 是 SCSI 命令执行后返回的一种状态,表示:
- 命令本身是合法的(没有语法错误)
- 但在执行过程中发生了某种异常情况或错误条件
- 需要进一步查询详细信息
要说清楚SCSI,我们还要提一句SCSI 状态机。任何一个SCSI命令的执行结果无外乎是下面的四种之一:
- GOOD ← 完美执行
- CHECK CONDITION│ ← 有异常,查详情!
- BUSY ← 设备忙
- RESERVATION CONFLICT ← 锁定冲突
下面我们重点来理解下 check condition
Check Condition ≠ 错误
Check Condition = "命令执行异常,需要查看 Sense Data"
Sense Data 决定:错误/警告/信息/恢复成功
下面是Sense Data 的 4 大类含义
|
Sense Key |
含义 |
示例 |
|
0x00 NO SENSE |
正常,无错误 |
命令成功但有额外信息 |
|
0x01 RECOVERED ERROR |
已恢复,有警告 |
命令成功但有轻微问题 |
|
0x02-0x07 |
真正错误 |
硬件故障、参数错误等 |
|
0x08 BLANK CHECK |
介质问题 |
磁带/光盘空白 |
问题又来了,如果是sense key是 0x02-0x07,那么下一步怎么查问题呢?继续follow me。
为什么"任何 SCSI 报错都有 Check Condition"?
SCSI 的错误报告机制(注意呀,这是SCSI协议,就是国际标准组织定义的,不是某个厂家的某个程序员自己发挥出来的):
1. 命令 → 执行
2. 异常发生 → 不直接返回错误码
3. 返回 CHECK CONDITION + Sense Data ← 详细信息在 Sense Data 中
对比其他协议:
- ATA: 直接返回错误寄存器值
- NVMe: 直接返回 Status Code
- SCSI: 分两步走 → Status + Sense Data
遇到 Check Condition 的标准处理流程,这个是程序开发的流程,理解下
1. 立即发送 REQUEST SENSE 命令
echo "REQUEST SENSE" | sg_raw /dev/sdX
2. 解析 Sense Data 结构
Sense Data 关键字段:
- Response Code│ 0x70/0x71=固定格式
- Sense Key │ 0x00-0x0B=错误类型
- ASC/ASCQ │ 具体错误代码
估计小白们要晕菜了,这TMD的还要我发命令吗?上面是原理,在存储系统中不需要我们发命令,如果SCSI命令报错了,会自动做request sense的命令,我们不用关心。下面是存储系统中的做法,可以说所有的存储系统基本上都是这样设计的。
传统 SCSI:
命令 → CHECK CONDITION → REQUEST SENSE → 解析
现代存储系统中的优化:
命令 → 自动内联 Sense Data(在 CDB 返回中)
应用 → 直接解析,无需额外命令
开始实战一下,下面是个实际的DE6000 磁盘报check condition的日志,跟着老司机带您畅游SCSI的世界。
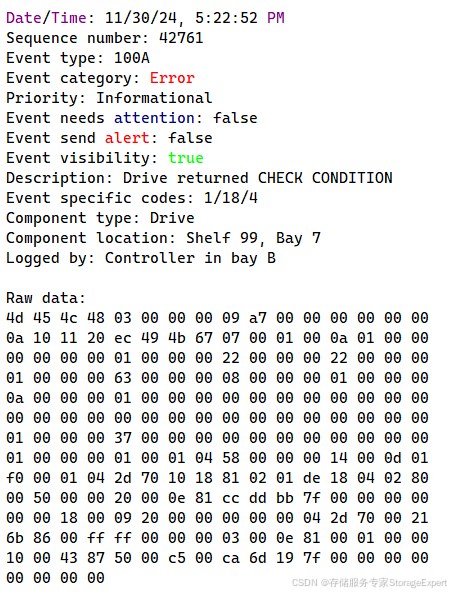
这是一个典型的 NetApp E-Series 存储阵列 的 Major Event Log (MEL) 条目,记录了硬盘驱动器(Drive)在执行 SCSI 命令时返回的异常状态。以下是关键字段的逐一解读:
|
字段 |
值 |
解释 |
|
Date/Time |
11/30/24, 5:22:52 PM |
事件发生时间:2024年11月30日 下午5:22:52。 |
|
Sequence number |
42761 |
事件的序列号,用于日志排序和追踪(非错误码)。 |
|
Event type |
100A |
固定事件类型,表示“Drive returned CHECK CONDITION”。这是 E-Series 中硬盘报告 SCSI 异常的标准事件码。它本身不是严重故障,而是需要进一步检查 Sense Data 的信号。 |
|
Event category |
Error |
分类为错误,但不一定是致命的(结合优先级判断)。 |
|
Priority |
Informational |
信息级优先级,表示这是一个可恢复的警告或已处理的问题,不需要立即警报。系统可以继续运行。 |
|
Event needs attention |
false |
不需要人工干预(系统已自动处理或恢复)。 |
|
Event send alert |
false |
不触发警报通知(如邮件/SNMP)。 |
|
Event visibility |
true |
事件在日志中可见,可供管理员查看。 |
|
Description |
Drive returned CHECK CONDITION |
硬盘返回了 SCSI CHECK CONDITION 状态码。这意味着命令执行中遇到异常,但硬盘已尝试恢复。 |
|
Event specific codes |
1/18/4 |
关键诊断码:Sense Key = 1(十六进制 0x01),ASC = 18(0x12),ASCQ = 4(0x04)。这是 SCSI Sense Data 的核心部分,用于精确描述异常。 |
|
Component type |
Drive |
受影响组件:硬盘驱动器。 |
|
Component location |
Shelf 99, Bay 7 |
位置:shelf 99,槽位(Bay)7。Shelf 99 一般都是机头,没有人把一个扩展柜的ID变成99的。 |
|
Logged by |
Controller in bay B |
记录者:控制器 B。 |
|
Raw data |
十六进制数据 |
原始二进制数据,包含完整 Sense Data 和命令上下文。 |
Raw data的数据这里就不解析了,这个16进制数据其实是可以解析出完整的sense Data,对应的磁盘的LBA的位置,还有上下文的,需要研究深入的朋友可以单独探讨。
重点来看check condition返回的sense data的数据:
Event Specific Codes 1/18/4:直接对应 Sense Key 1 / ASC 18 / ASCQ 4(十进制表示,便于日志记录)。NetApp 使用这种格式简化输出。
我们来查询下scsi 的sense key和asc的定义
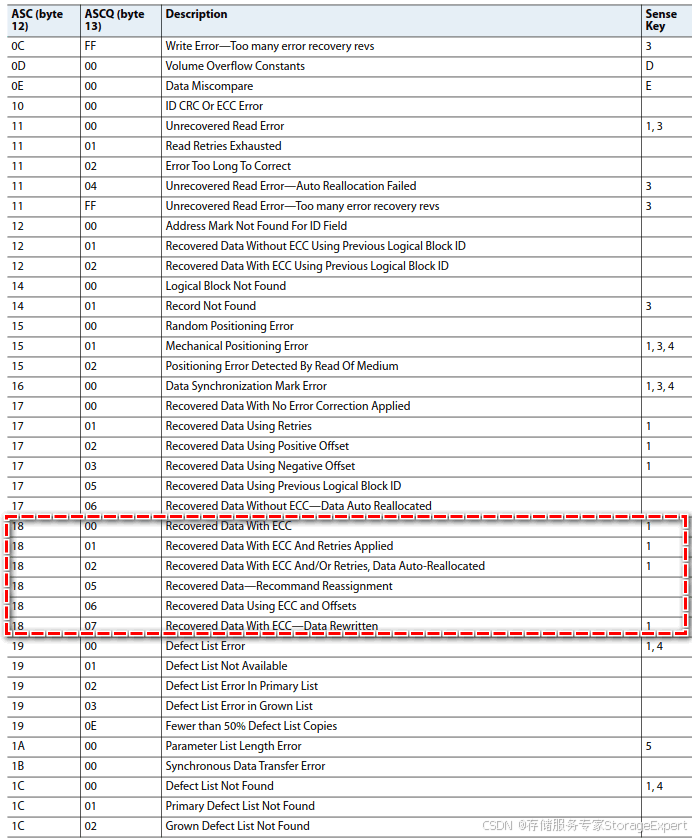
从上面的表格可以看到 sense key是1的ASC是 18的,都是关于recovered data的。 ASCQ这个表格中没有 04,估计这个版本低吧,偷懒,我就不再找了,但大方向一定是 recovered data方面的问题。
问题诊断
- 严重程度:低(Informational)。这是一个 可恢复的读错误:
- 驱动器在 LBA ~0x00104de 处检测到数据问题(可能坏扇区、ECC 错误或介质缺陷),。这个LBA的位置是从RAW data中解析出来的。
- 系统自动重试或将数据从备用位置(备用扇区)恢复,无需干预。
- 无数据丢失:RECOVERED ERROR + ASC/ASCQ 组合确认数据完整性已维护。
- 根本原因:
- 硬盘介质有些问题(常见于使用中的 HDD/SSD),但不是大问题,还不构成坏道。
- 读操作触发了内部纠错机制(驱动器固件处理)。
- 影响:不影响任何阵列可用性或数据访问。
这样的类似事件在 E-Series 中常见于后台扫描(Media Scan)期间,这是一个常规动作,就是定期对磁盘进行扫描。这是一个正常的可恢复的读错误,驱动器已自我修复。系统正常,继续观察日志即可。
写在最后
如果遇到新的CDB该如何处理呢?网上下载一个scsi command 之类的文档,这是标准协议,很多地方都可以下载到,有专门的章节可以查询 sense key, ASC和ASCQ的组合代表什么含义。根据这个含义再来看check condition到底遇到了什么问题。


















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









