




C++ 内存模型是规范程序中对象存储、访问及线程交互的核心底层逻辑,其对符号解析、地址绑定的约束直接影响多文件协作的正确性。
在并发编程中,若未采用同步机制(如互斥锁/原子操作)直接进行多线程共享变量访问,程序将面临不可预测的行为。
这种不确定性源于三个关键因素:编译器的指令重排优化、CPU的乱序执行特性,以及多级缓存架构导致的内存可见性问题。
这些底层机制使得代码中的读写顺序与实际硬件执行的内存访问顺序可能出现偏差。
平时咱们写程序,大多时候不用特意去琢磨 memory order 这个概念,用 mutex 这类并发编程的工具就够了。但要是涉及到 Kernel 开发、虚拟机、编译器及相关基础库,还有无锁设计的系统编程,那 memory order 的概念就用得上了,所以搞明白它还是挺有必要的。
Part1内存分区
C++内存管理采用多区域划分机制,常说的 C++ 内存,大致能分成 5 个区域
1、堆(heap):这部分内存是靠 new 来分配的,编译器才不管它啥时候释放,得咱们自己在程序里把控 —— 一个 new 就得对应一个 delete。要是程序员忘了释放,也不用太慌,等程序跑完了,操作系统会自动把这部分内存收回去。不过跟堆相关的问题也不少,比如 “缓冲区溢出” 和 “内存泄露”,都是开发中得留意的。
2、栈(stack):这是编译器按需分配、不用了就自动清理的地方。像局部变量、函数参数这些,都存这儿。栈里的数据有个特点,只在当前函数和下一层调用的函数里有效,一旦函数执行完返回了,这些数据也就跟着自动释放了,不用咱们额外操心。
3、全局 / 静态存储区:它对应着.bss 段和.data 段。全局变量和静态变量就待在这一块内存里。在 C 语言里,没初始化的会放在.bss 段,初始化了的搁在.data 段;到了 C++ 里,就不这么区分啦,都归到这儿。
4、常量存储区(.rodata 段):听名字就知道,这儿是放常量的地方,正常情况下不允许修改,当然,用些不正当的手段也能改,但咱可不提倡这么做。
5、代码区(.text 段):函数这类代码就存放在这。它跟常量存储区一样,不允许随便修改,但有个重要区别 —— 代码区的内容是可以执行的。
有时候内存也按“生命周期”分三类:
- 自由存储区:其实就是栈(局部非静态变量),变量跟着函数“出生”(调用时创建),“死亡”(返回时销毁)。
- 动态区:堆的同义词,变量由new/malloc“制造”,手动delete/free“销毁”,或者等程序结束被系统回收。
- 静态区:全局/静态变量+字符串常量的地盘,从程序启动活到程序结束,堪称“内存寿星”。
Part2为什么需要内存模型
要理解为什么需要C++内存模型,咱们可以从多线程的实际情况一步步捋。
多线程技术的出现,本意是为了把 CPU 的能力榨到极致,提升整体的计算效率。
但从单核到多核时代,线程运行的环境变了 —— 单核时,多线程看着是并行,实则微观上是串行的,还能共享 CPU 的缓存和寄存器;可到了多核时代,不同线程可能跑在不同的核上,每个 CPU 都有自己的缓存和寄存器,一个核上的线程压根碰不到另一个核的,这就为数据访问埋下了 “乱子的种子”。
更麻烦的是 “指令重排”。CPU 会按自己的规则重新排机器指令的内存交互顺序,还允许每个处理器延迟存储、从不同地方装数据;编译器也会按自己的逻辑优化代码,同样可能打乱代码顺序。这些重排在单线程里没问题,反正不影响执行结果,可到了多线程环境,麻烦就来了。编译器把它们的操作乱序后,当前线程跑着没毛病,但要是其他线程的操作依赖 A 和 B 的原有顺序,数据竞争(Data Race)的问题就会被加剧,最后可能跑出谁也想不到的结果 —— 这就是多线程下数据访问的 “不确定性”。
为了应对这种不确定性,咱们开发时常会用信号量或者锁来做同步。但这些东西算是接近操作系统的底层原语,每次加锁、解锁可能要在用户态和内核态之间切换,数据访问的开销并不小。要是锁用得不合适,还可能拖慢整体性能,甚至造成严重的性能问题。
所以咱们就需要一种 “语言层面的机制”:它不用像锁那样付出大开销,又能满足数据访问一致性的需求。其实 Java 早在 2004 年的 5.0 版本就引入了适用于多线程的内存模型,而 C++ 直到 C++11 才跟上,引入了自己的内存模型 —— 说到底,就是为了在多线程场景下,既高效又稳妥地管好内存访问这件事。
Part3C++中内存模型规则
C++11 引入的现代内存模型是多线程编程的基础,其核心目标是通过标准化内存访问规则,解决多线程环境下共享数据的可见性、有序性和原子性问题。
1、顺序一致性 (默认):保证单线程代码按顺序执行。
举个栗子:
线程A执行 a = 1; x = y;,线程B执行 b = 2; y = x;。
如果按顺序一致性,不管两个线程怎么“并发”,所有线程看到的操作顺序都是:
a=1 → x=y(线程A)和 b=2 → y=x(线程B)这两个序列的“全局顺序”完全一致(比如线程A的x=y一定在线程B的y=x之前,或者之后,但所有线程都看到同样的顺序)。
需注意:顺序一致性仅在多线程显式使用同步机制(如std::mutex或std::atomic配合memory_order_seq_cst)时生效。如果没有同步,编译器/CPU可能偷偷重排指令,破坏这种一致性。
2、数据竞争(Data Race):
无同步机制的并发读写同一位置(至少一个写操作)导致未定义行为。需用互斥锁 (std::mutex) 或原子操作 (std::atomic) 避免。
举个危险的栗子:
int counter = 0; // 共享变量
// 线程A:循环10000次自增
void threadA() {
for (int i = 0; i < 10000; ++i) {
counter++; // 等价于:counter = counter + 1(读+改+写三步)
}
}
// 线程B:同样循环10000次自增
void threadB() {
for (int i = 0; i < 10000; ++i) {
counter++;
}
}如果两个线程同时运行且无同步,counter++的三步操作(读旧值→加1→写回新值)可能被交叉执行:
- 线程A读counter=0,还没写回时,线程B也读counter=0;
- 两个线程都加1后写回,最终counter可能只增加1(而不是2)。
这就是典型的数据竞争,结果是不可预测的。
3、内存序(Memory Order):给原子操作“松绑”的“灵活开关”
为了避免数据竞争,C++提供了std::atomic模板(原子类型),配合内存序(memory_order枚举),在保证原子性的同时,允许开发者根据场景需求灵活控制内存操作的顺序,避免锁的高开销。
4、顺序一致性(std::memory_order_seq_cst):
最严格的内存序,保证所有线程的内存操作顺序一致。
5、获取(std::memory_order_acquire)和释放(std::memory_order_release):
用于同步多个线程,确保在一个线程释放锁(或数据)之前的写入操作对另一个获取锁的线程可见。
6、松散顺序(std::memory_order_relaxed):
不保证顺序,仅适用于无竞争条件的并发操作,如计数器的递增。
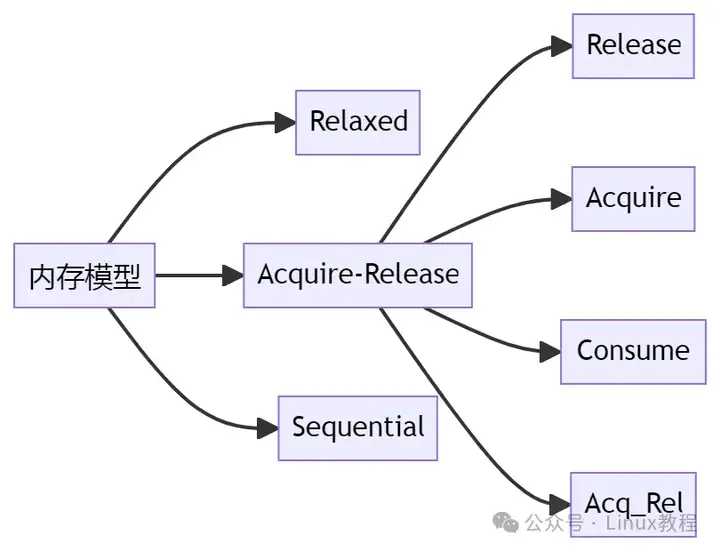
这六种内存约束符从读/写的角度进行划分的话,可以分为以下三种:
- • 读操作(memory_order_acquire memory_order_consume)
- • 写操作(memory_order_release)
- • 读-修改-写操作(memory_order_acq_rel memory_order_seq_cst)
- ps: 因为memory_order_relaxed没有定义同步和排序约束,所以它不适合这个分类。
- 从访问控制的角度可以分为以下三种:
- • Sequential consistency模型(memory_order_seq_cst)
- • Relax模型(memory_order_relaxed)
- • Acquire-Release模型(memory_order_consume memory_order_acquire memory_order_release memory_order_acq_rel)
- 从从访问控制的强弱排序,Sequential consistency模型最强,Acquire-Release模型次之,Relax模型最弱。
- 在后面的内容中,将结合这6种约束符来进一步分析内存模型。
- Part4C++内存模型深度解析
1、Sequential consistency 模型
Sequential consistency 模型(又称顺序一致性模型)是内存模型中控制粒度最严格的一种。其概念最早可追溯至 Leslie Lamport 在 1979 年 9 月发表的论文《How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs》,文中首次提出了 Sequential consistency 的定义:
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program
通俗来说,在顺序一致性模型下,程序的执行顺序与代码指定的顺序严格一致—— 不存在指令乱序的情况。
该模型对应的约束符号是memory_order_seq_cst,它对内存访问顺序的一致性控制最强,类似直观的 “互斥锁模式”:先获取 “顺序控制权” 的操作先执行。
以两个线程(线程 A、线程 B)为例,其执行情况可分为三类:
- 线程 A 完全执行后,线程 B 再执行;
- 线程 B 完全执行后,线程 A 再执行;
- 两线程并发执行(代码序列交替执行)。
无论哪种情况,单个线程的执行顺序必须与自身代码顺序一致。总结来说:
- 每个线程的执行顺序与代码顺序严格一致;
- 线程间可能交替执行,但单线程视角下仍为顺序执行。
为便于理解,举如下示例:
x = y = 0;
thread1:
x = 1;
r1 = y;
thread2:
y = 1;
r2 = x;多线程环境下,执行顺序可能交错(如以下几种情况):
- x = 1; r1 = y; y = 1; r2 = x
- y = 1; r2 = x; x = 1; r1 = y
- x = 1; y = 1; r1 = y; r2 = x
- x = 1; r2 = x; y = 1; r1 = y
- y = 1; x = 1; r1 = y; r2 = x
- y = 1; x = 1; r2 = x; r1 = y
但从单线程视角看,线程 1 始终遵循 “x=1→r1=y” 的顺序,线程 2 始终遵循 “y=1→r2=x” 的顺序。
在 C++ 中,std::atomic的操作默认使用memory_order_seq_cst。若不确定应使用哪种内存访问模型,选择memory_order_seq_cst可确保程序正确性。不过,这种严格的排序会限制现代 CPU 的并行处理能力,可能导致系统性能下降。
2、Relax 模型
Relax 模型对应memory_order中的memory_order_relaxed,是对内存序限制最小的模型。它仅保证当前数据访问是原子操作(不会被其他线程打断),但不约束内存访问顺序—— 不同数据的读写可能被重新排序。
示例解析
以下代码可直观体现 Relax 模型的特性:
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<bool> x{false};
int a = 0;
void fun1() { // 线程1
a = 1; // L9
x.store(true, std::memory_order_relaxed); // L10
}
void func2() { // 线程2
while(!x.load(std::memory_order_relaxed)); // L13
if(a) { // L14
std::cout << "a = 1" << std::endl;
}
}
int main() {
std::thread t1(fun1);
std::thread t2(fun2);
t1.join();
t2.join();
return 0;
}- 线程 1 中,L9(普通赋值)与 L10(原子写操作)的顺序可能因 “指令重排” 交换 —— 无法保证 L9 一定先于 L10 执行;
- 线程 2 中,L13(原子读操作)与 L14(判断输出)的顺序由 while 循环语义保证(L13 happens-before L14),不会被重排。
因此,该示例可能不输出 “a=1”:若线程 1 中 L10 先执行,线程 2 会通过 L13 跳出循环并执行 L14,此时 L9(a=1)尚未执行,a的值仍为 0。
适用场景
memory_order_relaxed的核心价值在于 “仅保证原子性”,适合统计计数等无需依赖操作顺序的场景。例如:
#include <cassert>
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> cnt = {0};
void fun1() {
for (int n = 0; n < 100; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
void fun2() {
for (int n = 0; n < 900; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
int main() {
std::thread t1(fun1);
std::thread t2(fun2);
t1.join();
t2.join();
return 0;
}无论操作顺序如何,cnt的最终值一定是 1000(原子操作保证计数准确)。
宽松内存序的同步开销最小,但因不保证顺序会引入不确定性,需根据实际场景选择。
3、Acquire-Release 模型
Acquire-Release 模型的控制力度介于 Relax 模型与 Sequential consistency 模型之间。其核心定义如下:
- Acquire:若操作 X 带有 acquire 语义,则 X 之后的所有读写指令不会被重排到 X 之前;
- Release:若操作 X 带有 release 语义,则 X 之前的所有读写指令不会被重排到 X 之后。
简单来说:对原子变量 A,“带 release 语义的写操作” 与 “带 acquire 语义的读操作” 可实现同步并建立排序约束 —— 写操作前的指令不会被重排到写操作后,读操作后的指令不会被重排到读操作前。
该模型对应四种约束符:memory_order_consume、memory_order_acquire(仅用于读操作)、memory_order_release(仅用于写操作)、memory_order_acq_rel(可读可写)。
4、memory_order_release
若对原子变量 A 的写操作 X 使用memory_order_release,则在当前线程 T1 中,X 之前的所有读写指令不会被重排到 X 之后。
当其他线程 T2 对 A 执行读操作时:
- 若读操作使用memory_order_acquire,则 T1 中 X 之前的所有读写操作对 T2可见;
- 若读操作使用memory_order_consume,则 T1 中与 A 有 “依赖关系” 的读写操作对 T2可见(无依赖的操作不保证顺序)。
需注意:上述 “不重排” 的前提是其他线程对该原子变量执行了带memory_order_acquire或memory_order_consume的读操作。
5、memory_order_acquire
若对原子变量 A 的 load 操作 X 使用memory_order_acquire,则在当前线程 T1 中,X 之后的所有读写指令不会被重排到 X 之前。
若其他线程 T2 对 A 执行了带memory_order_release的写操作 Y,则 Y 之前的所有读写操作对 T1可见(符合 happens-before 原则,即操作已完成且不会被重排)。
示例:acquire 与 release 的配合
以下是 cppreference 中的经典示例,体现两者的协同作用:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer() {
std::string* p = new std::string("Hello"); // L10
data = 42; // L11
ptr.store(p, std::memory_order_release); // L12(release写)
}
void consumer() {
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire))); // L17(acquire读)
assert(*p2 == "Hello"); // L18
assert(data == 42); // L19
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}- 线程 producer 中,L12(release 写)保证 L10、L11 不会被重排到 L12 之后;
- 线程 consumer 中,L17(acquire 读)保证 L18、L19 不会被重排到 L17 之前。
因此,当 L17 读到非空的ptr时,producer 中的 L10、L11 已执行完毕,两个assert均成立。
6、memory_order_consume
若对原子变量 A 的 load 操作 X 使用memory_order_consume,则在当前线程 T1 中,X 之后 “依赖于 A” 的读写指令不会被重排到 X 之前。
若其他线程 T2 对 A 执行了带memory_order_release的写操作,则该写操作及 “与 A 有依赖关系” 的操作对 T1 可见。
“依赖关系” 指变量间的直接关联(如指针指向)。例如:
std::atomic<std::string*> ptr;
int data;
std::string* p = new std::string("Hello");
data = 42;
ptr.store(p, std::memory_order_release);其中,ptr依赖于p(ptr存储p的地址),但不依赖data,p与data也无依赖。
将前文示例中consumer的load改为memory_order_consume:
void consumer() {
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_consume))); // L17(consume读)
assert(*p2 == "Hello"); // L18
assert(data == 42); // L19
}此时:
- ptr与p有依赖,故p(L10)不会被重排到 L12 之后,L18 的assert成立;
- ptr与data无依赖,故data(L11)可能被重排到 L12 之后,L19 的assert可能失败。
注意:consume 的实现现状
因memory_order_consume的实现复杂,自 2016 年 6 月起(参考《P0371R1: Temporarily discourage memory_order_consume》),主流编译器中memory_order_consume与memory_order_acquire功能完全一致。
7、memory_order_acq_rel
memory_order_acq_rel是 “acquire+release” 的组合,既可约束读操作,也可约束写操作:
- 对当前线程:操作之前的读写指令不会被重排到操作之后,操作之后的读写指令也不会被重排到操作之前;
- 对其他线程:若其他线程用memory_order_release写,则其写之前的操作对当前线程可见;若其他线程用memory_order_acquire读,则当前线程的写操作对其可见。
示例:acq_rel 的多线程同步
#include <thread>
#include <atomic>
#include <cassert>
#include <vector>
std::vector<int> data;
std::atomic<int> flag = {0};
void thread_1() {
data.push_back(42); // L10
flag.store(1, std::memory_order_release); // L11(release写)
}
void thread_2() {
int expected=1; // L15
// 用acq_rel保证读-改-写的顺序约束
while (!flag.compare_exchange_strong(expected, 2, std::memory_order_acq_rel)) { // L18
expected = 1;
}
}
void thread_3() {
while (flag.load(std::memory_order_acquire) < 2); // L24(acquire读)
assert(data.at(0) == 42); // L26
}
int main() {
std::thread a(thread_1);
std::thread b(thread_2);
std::thread c(thread_3);
a.join();
b.join();
c.join();
return 0;
}- thread_2中,compare_exchange_strong(acq_rel)保证 L15 不会被重排到 L18 之后,确保expected为 1 时完成替换(flag=2);
- thread_1中,L11(release 写)保证 L10(data 写入)不会被重排到 L11 之后,故thread_2读取 flag 时 L10 已完成;
- thread_3中,L24(acquire 读)读到 flag=2 时,thread_2的 L18 及thread_1的 L10 均已可见,故 L26 的assert成立。
memory_order_acq_rel也可单独用于读或写,与 “acquire+release” 组合等效。例如:
// 示例1:用acq_rel
// Thread-1:
a = y.load(memory_order_acq_rel); // A
x.store(a, memory_order_acq_rel); // B
// Thread-2:
b = x.load(memory_order_acq_rel); // C
y.store(1, memory_order_acq_rel); // D
// 示例2:用acquire+release
// Thread-1:
a = y.load(memory_order_acquire); // A
x.store(a, memory_order_release); // B
// Thread-2:
b = x.load(memory_order_acquire); // C
y.store(1, memory_order_release); // D两者效果完全一致,均保证 A 先于 B、C 先于 D 执行。
总结
Qt C++ 实现无边框窗体/自定义标题栏/圆角/窗口拖拽拉升和阴影
腾讯 Linux C/C++ 后端开发岗全记录:真实问题+解析
顺时针螺旋移动法 | 彻底弄懂复杂C/C++嵌套声明、const常量声明!!!
小米C++校招二面:epoll和poll还有select区别,底层方式?
C++11 auto 与 decltype:用法、区别与实战
C++ std::function:从类型擦除实现到高性能实践

















 4465
4465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









