




课后大总结
01-学习心得
1.本章学到的知识点包括以下几部分:
(1)线程。
(2)队列
(3)线程锁。
(4)进程。
(5)线程池和进程池。
(6)协程。
其中学习难度最大的部分在线程锁,虽然理解了5种线程锁代码示例,但对其实际应用,一时难以做好熟练理解并应用,以后还要多加强此部分的理解和以及在开发中的应用。
笔记说明:
1.黑色字体是老师计件中内容原文。
2.蓝色字体内容是老师在课堂上口头讲述的内容。
3.灰色字体是自己学习时添加的内容,目的是为了增加对老师讲课的理解。
4.红色为老师总结的课堂笔记。
全课总结:
1.线程可以大大提高程序的运行效率。
2.线程的特点:
(1)
(2)主线程等所有子线程结束后才会结束,主线结束后才意味着程序真正结束。
(3)多线程执行任务的顺序是确定的。
3.线程的使用步骤。
第一部分 线程
P1 引入多任务
现实生活中
有很多的场景中的事情是同时进行的,比如开车的时候 手和脚共同来驾驶汽车,再比如唱歌跳舞也是同时进行的;

试想,如果把唱歌和跳舞这2件事情分开依次完成的话,估计就没有那么好的效果了(想一下场景:先唱歌,然后在跳舞,O(n_)O哈哈~)
程序中
如下程序,来模拟“唱歌跳舞”这件事情:
import time
def sing():
for i in range(3):
print(f"正在唱歌...{i}")
time.sleep(1)
def dance():
for i in range(3):
print(f"正在跳舞...{i}")
time.sleep(1)
if __name__=="__main__":
sing()
dance()很显然刚刚的程序并没有完成唱歌和跳舞同时进行的要求。
如果想要实现“唱歌跳舞”同时进行,那么就需要一个新的方法,叫做:多任务。
要想实现唱歌和跳舞同时进行,代码需要导入threading模块,并做如下调整。
import time,threading
def sing():
for i in range(3):
print(f"正在唱歌...{i}")
time.sleep(1)
def dance():
for i in range(3):
print(f"正在跳舞...{i}")
time.sleep(1)
if __name__=="__main__":
t1=threading.Thread(target=sing)
t2=threading.Thread(target=dance)
t1.start()
t2.start()学习总结
t1=threading.Thread(target=sing)
# 参数target=sing,sing函数后不带括号;如果加上括号,运行就会很慢。
见下面示例:
代码1没有括号,秒完成。
代码2加了括号,完成很慢。
代码1:
import time,threading
def say_sorry():
print("亲爱的,我错了,我能吃饭了吗?")
time.sleep(1)
for i in range(1000):
t=threading.Thread(target=say_sorry)
t.start() # 启动线程,即让线程开始执行:从say_sorry函数开始执行代码2:
import time,threading
def say_sorry():
print("亲爱的,我错了,我能吃饭了吗?")
time.sleep(1)
for i in range(1000):
t=threading.Thread(target=say_sorry())
t.start() # 启动线程,即让线程开始执行:从say_sorry函数开始执行P2 理解多任务
多任务的概念
1.什么是多任务
简单地说,就是同时可以运行多个任务。
打个比方,你一边在用浏览器上网,一边在听MP3,一边在用Word赶作业,这就是多任务。
电脑应不止有一个程序在运行,例如,你现在正在看着的屏幕,是一个程序。如果你在登录QQ,这是另外一个程序。如果QQ没有登录,你只要打开任何一个软件,那么都认为这是两个软件,三个软件,甚至四个软件。那么给大家说,现在的电脑啊,它同一时刻,是可以运行多个的。才能够出现今天,像你的电脑上,一边可以听着歌,一边可以听着迅雷下载,一边可以开着浏览器看电影,这才实现了这个功能。
什么是多任务?咱们简单理解,你的电脑上可以同时运行多个程序,那么我们就认为你的操作系统就是多任务的操作系统。那么再换一种说法,如果你写了一程序,你的程序当中,可以同时做很多个事情,那么我们把你的程序也认为是多任务的程序。

2.多任务执行原理
现在,多核CPU已经非常普及了,但是,即使过去的单核CPU,也可以执行多任务。由于CPU执行代码都是顺序执行的,那么,单核CPU是怎么执行多任务的呢 ?
答案就是:
操作系统轮流让各个任务交替执行。任务1执行0.01秒,切换到任务2,任2执行0.01秒,再切换到任务3执行0.01秒…….这样反复执行下去。表面上看,每个任务都是交替执行的,但是,由于CPU的执行透度实在是太快了,我们感觉就像所有任务都在同时执行一样。

3.注意
并发:指的是任务数多于cpu核数,通过操作系统的各种任务调度算法,实现用多个任务“一起”执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
并行:指的是任务数小于等于cpu核数,即任务真的是一起执行的。
4.课堂笔记(老师总结)
1.多任务:
1.如果一个操作系统上同时运行了多个程序,那么称这个操作系统是多任务的操作系统,Windows、Ubuntu、mac、Android、ios
2.如果一个程序,它可以同时执行多个事情,那么就称为 多任务的程序
2.理解多任务:
1.一个cpu是单核默认可以执行一个程序,如果想要多个程序一起执行,理论上将就需要多个cpu4核来执行
2.如果一个cpu是4核,理论上将 同时只能有4个任务一起执行,但是事实上却可以运行很多个程序,之所以有这个现象,是因为操作系统控制着cpu,让cpu做了一个特殊的事情,一会运行一个程序,然后快速的运行另外一个程序,再运行另外的程序,依次类推,实现了多个任务看上去“一起”运行。
3.并发、并行:
1.并发:是一个对假的多任务的描述
2.并行:是真的多任务的描述
P3 线程介绍
1.引入
如果一个程序想同时执行多个部分的代码,那么基本有2种方式实现:
1. 线程
2 进程
我们首先来研究线程。
2.什么是线程
线程是一个抽象的概念,可以把它想象成程序在执行代码时的那个执行流。
3.通过线程实现多任务
在Python中如果想使用线程实现多任务,可以使用thread模块 但是它比较底层,即意味着过程较为复杂不方便使用。推荐使用threading模块,它是对thread做了一些包装的,可以更加方便使用 。
4.课堂笔记(老师总结):
线程:
1.当一个程序运行时,默认有一个线程,这个线程我们称之为主线程
2.多任务也就可以理解为让你的代码再运行的过程中额外创建一些线程,让这些线程去执行代码。
P4 通过线程实现多任务
4.使用threading模块
4.1单线程执行
每个程序,默认存在一个主线程。
import time
def say_sorry():
print("亲爱的,我错了,我能吃饭了吗?")
time.sleep(1)
for i in range(5):
say_sorry()
4.2多线程执行
import time,threading
def say_sorry():
print("亲爱的,我错了,我能吃饭了吗?")
time.sleep(1)
for i in range(5):
t=threading.Thread(target=say_sorry)
t.start() # 启动线程,即让线程开始执行:从say_sorry函数开始执行for循环中,创建了线程对象t后并执行线程对象t。创建线程对象和执行线程对象并没有设置时间间隔。因此,并未等say_sorry函数执行完毕,即再一次重建线程对象t并执行。因此,相当于同时有多个say_sorry函数执行。因此该段代码秒完成。
4.3说明
1.可以明显看出使用了多线程并发的操作,花费时间要短很多。
2.当调用 start()时,才会真正的创建线程,并且开始执行。
4.4使用线程的步骤
1.导入threading模块
2.使用threading模块中的Thread创建一个对象
3.调用这个实例对象的start方法让这个线程开始运行
示例代码(结合老师讲解的步骤和课堂实例改编而来):
# 1.导入threading模块
import time,threading
def sing():
for i in range(3):
print(f"正在唱歌...{i}")
time.sleep(1)
def dance():
for i in range(3):
print(f"正在跳舞...{i}")
time.sleep(1)
if __name__=="__main__":
# 2.使用threading模块中的Thread创建一个对象
t1=threading.Thread(target=sing)
t2=threading.Thread(target=dance)
# 3.调用这个实例对象的start方法让这个线程开始运行
t1.start()
t2.start()P5 通过线程实现多任务2
小结(老师总结)
1.想要执行一个单独的任务,那么就需要创建一个新的线程。
2.在python中使用threading模块中的Thread类,就可以创建一个对象。这个对象标记着线程,创建出来的线程默认是不会执行的。
3.调用这个线程对象的start方法,就可以让这个新的线程开始执行代码。至于这个线程去执行哪里的代码,要看在用Thread创建对象的时候给target参数传递的是哪个函数的引用,即将来线程就会执行target参数指定的那个函数。
4.如果想在一个程序中有多个任务一起运行那么,就想办法创建多Thread对象即可。
课堂练习代码:
# 1.导入threading模块
import threading
import time
def task_1():
while True:
print("11111111")
time.sleep(1)
def task_2():
while True:
print("33333333")
time.sleep(0.2)
# 2.使用threading模块中的Thread创建一个对象
t1=threading.Thread(target=task_1)
t2=threading.Thread(target=task_2)
# 3.调用这个实例对象的start方法让这个线程开始运行
t1.start()
t2.start()
while True:
print("22222222")
time.sleep(1)P6 多个线程执行相同的代码
创建线程的时候,你指定的这个函数只要执行完,这个线程就死(结束)了。当所有的线程(包括主线程)都死了以后,这个程序才算真正的结束。主线程要等所有子线程结束以后才会结束。目的是将来有一些子线程它会产生一线垃圾。那么主线程额外的目的是回收这些垃圾,把这些垃圾清理干净,然后这个主线程才会结束。示例代码1中,虽然子线程后面没有代码,但是主线程依然会等待子线程结束。
示例代码1:
import time,threading
def say_sorry():
for i in range(5):
print("I am sorry")
time.sleep(1)
t1=threading.Thread(target=say_sorry)
t2=threading.Thread(target=say_sorry)
t1.start()
t2.start()小结(老师总结)
1.一个程序中,可以有多个线程,执行相同的代码。但是每个线程执行每个线程的功能,互不影响,仅仅是做的事情相同罢了。
2.当在创建Thread对象是target执行的函数 的代码 执行完之后,意味着这个子线程结束。
3.虽然主线程没有了代码,但是它依然会等待所有的子线程结束之后,它会真正的结束,原因是:主线程有个特殊的功能用来对子线程产生的垃圾进行回收处理。
4.当主线程接收之后,才意味着整个程序真正的结束。
P7 线程执行的顺序不确定
示例代码:
import time
import threading
def test1():
'''
这是一个单独任务。
'''
for i in range(10):
print(f"任务1...{i}")
time.sleep(0.1)
def test2():
'''
这是另外一个单独任务。
'''
for i in range(5):
print(f"任务2...{i}")
time.sleep(0.2)
t1=threading.Thread(target=test1)
t2=threading.Thread(target=test2)
t1.start()
t2.start()运行结果:
第一次运行后的结果 多次运行后的结果 是否运行 任务1...0 任务1...0 TRUE 任务2...0 任务2...0 TRUE 任务1...1 任务1...1 TRUE 任务2...1 任务1...2 FALSE 任务1...2 任务2...1 FALSE 任务1...3 任务1...3 TRUE 任务2...2 任务2...2 TRUE 任务1...4 任务1...4 TRUE 任务1...5 任务1...5 TRUE 任务2...3 任务2...3 TRUE 任务1...6 任务1...6 TRUE 任务1...7 任务1...7 TRUE 任务2...4 任务2...4 TRUE 任务1...8 任务1...8 TRUE 任务1...9 任务1...9 TRUE
结论
由上面的运行结果可以发现,线程执行的顺序是不确定的。
课堂笔记(老师总结)
多线程执行的顺序是不确定,因为在执行代码的时候 当前的运行环境可能不同,以及资源的分配可能不同,导致了操作系统在计算接下来应该调用那个程序的时候,得到了不一样的答案,因此顺序不确定。
P8 查看程序运行过程中的线程信息(了解内容)
课堂练习代码1
import threading
import time
print(threading.enumerate())
def task_1():
for i in range(5):
print("111111")
time.sleep(1)
t1=threading.Thread(target=task_1)
t1.start()
print(threading.enumerate())
time.sleep(6)
print(threading.enumerate())运行结果1
[<_MainThread(MainThread, started 31560)>]
111111
[<_MainThread(MainThread, started 31560)>, <Thread(Thread-1 (task_1), started 10284)>]
111111
111111
111111
111111
[<_MainThread(MainThread, started 31560)>]小结1(老师总结)
1.通过第4行的打印能够说明,当程序运行之后 默认有1个线程。
2.当第13行创建一个Thread对象,第14行运行这个对象,且在第16行打印的时候有2个线程,那么就说明 Thread真的是创建了一个线程。
3.当一个线程结束之后,在第19行打印时只有1个,那就表示刚刚那个子线程已经结束了。
课堂练习代码2
import threading
import time
print(threading.enumerate())
def task_1():
for i in range(5):
print("111111")
time.sleep(1)
t1=threading.Thread(target=task_1)
print(threading.enumerate())
t1.start()
print(threading.enumerate())
time.sleep(6)
print(threading.enumerate())运行结果2
[<_MainThread(MainThread, started 34972)>]
[<_MainThread(MainThread, started 34972)>]
111111[<_MainThread(MainThread, started 34972)>, <Thread(Thread-1 (task_1), started 22672)>]
111111
111111
111111
111111
[<_MainThread(MainThread, started 34972)>]小结2(老师总结)
小结:
1.通过第14行、第17行的打印不同说明了,创建一个Thread对象(时),根本不会创建一个线程,仅仅是一个对象罢了。而当调用它的start方法之后,才会真正创建一个新的子线程。
2.什么时候调用start什么时候才会真正的创建新线程。
扩展知识,线程对象信息的含义
查资料得出,来源于豆包。
这里面的 <_MainThread(MainThread, started 31560)> 表示的就是主线程对象相关的信息呢。
_MainThread表明这是主线程,它是程序一开始运行就存在的线程,后续创建的其他线程都是相对主线程而言的子线程。MainThread是这个线程的名称,在 Python 里默认主线程就叫这个名字。started 31560意味着这个线程已经启动了,并且31560可能是操作系统给这个线程分配的一个标识符(不同环境下具体数值会不一样),用于唯一标识该线程。
P9 创建线程对象时传递参数1
创建线程时传递参数
1.引入
为了能够在创建线程时,让这个线程执行不一样的事情,可以在使用threadingThread创建线程时,传递一些参数给它。这样就让这个线程更加通用了 。
2. 怎样实现
课堂练习代码:
import threading
import time
def print_lines(num):
for i in range(num):
print("111111")
time.sleep(0.1)
def print_lines2(num1,num2):
for i in range(num1):
print("111111")
time.sleep(0.1)
for i in range(num2):
print("111111")
time.sleep(0.1)
t1=threading.Thread(target=print_lines,args=(3,))
t2=threading.Thread(target=print_lines2,args=(3,4))
t1.start()
t2.start()小结(老师总结)
1.创建Thread对象的时候:
(参数)target指明线程将来去哪里执行代码,(参数)args指明线程去执行代码的时候(函数)所携带的参数,它是一个元组。
2.如果target指明的函数只有1个形参,那么args的元组中必须只有1个元素。如果target指明的函数 有2个形参,那么args的元组中必须有2个元素。
注意:
函数只有一个参数的传入时元组的书写形式中一定在第一个元素后点面加逗号,否则会报错,见下面的示例:
t1=threading.Thread(target=print_lines,args=(3,))P10 创建线程对象时传递参数2
课堂练习代码
依据老师讲课代码改编而来,可以达到相同的练习效果。
import threading
def work1(num1,num2,num3,n):
print(num1,num2,num3,n)
def work2(num1,num2,num3,n):
print(num1,num2,num3,n)
t1=threading.Thread(target=work1,args=(11,22,33),kwargs={"n":44})
t2=threading.Thread(target=work1,kwargs={"num1":11,"num2":22,"num3":33,"n":44})
t1.start()
t2.start()
课后小结(自己总结)
创建线程对象时,传递参数时,支持args、kargs、args和kargs并存,这三种传递方式。P11 案例:多线程版udp聊天程序(待学习过网络编程后再听此节课)
P12 之前创建线程的方式
1.引入
创建线程的另外一种方式。
之前创建线程的基本流程是:
使用threading.Thread0创建一个对象,并且在使用target来指定一个的函数,作为线程要执行的代码。
示例代码:
import threading
def task_1(num1,num2):
pass
t=threading.Thread(target=task_1,args=(11,),kwargs={"num2":22})
t.start() # 真正的创建线程P13 自定义类创建线程(Thread子类)
封装性更好的一种创建线程的方式是:
1.定义一个新的类·继承Thread类。
2.在这个类中实现run方法。
3. 在nun方法中写如要执行的代码。
4.当使用这个类创建一个对象后,调用对象的start方法就可以让这个线程执行,且会自动执行run方法的代码。
2.示例代码(老师演示代码)
import threading
import time
class Task(threading.Thread):
def run(self):
while True:
print(self.name)
print("111111")
time.sleep(1)
t=Task()
t.start()
while True:
print("main")
time.sleep(1)课堂疑问?
自定义类Task中的方法为什么必须是run?换成别的名称就没有线程效果。答案:
细心观察后疑惑得以解决,原来run是父类的threading.Thread中一个方法,在自定义类中写上run方法,相当于重写父类的方法。 start自动调用run方法,个人感觉应在父类中有实现机制。
P14 通过self.name查看线程默认名字
1.课堂练习代码
import threading
import time
class Task(threading.Thread):
def run(self):
while True:
print(self.name)
print("111111")
time.sleep(1)
t=Task()
t.run()
while True:
print("main")
time.sleep(1)2.老师的讲义图片
3.小结(老师总结)
1.可以自己定义一个类,但是这个类要继承Thread
2.一定要实现run方法,即要定义一个run方法,并且实现线程需要执行的代码
3.当调用自己编写的类创建出来的实例对象的run方法时,会创建新的线程,并且线程会自动调用run方法。
4、如果出了run方法之外还定义了很多其他的方法,例如xx,那么这些方法需要在run方法中自己去调用。线程它不会自动调用。
2.2 说明(讲义内容)
1.python的threading.Thread类有一个run方法,用于定义线程的功能的数可以在自己的线程类中覆盖该方法。
2.创建线程对象后,调用start方法,可以启动该线程
3.当该线程获得执行的机会时,就会调用run方法执行线程的功能
4.run方法中可以编写本线程需要执行的代码
3.小结(讲义中的小结)
1.每个线程默认有一个名字,尽管上面的例子中没有指定线程对象的name,但是python会自动为线程指定一个名字。
2.当线程的run()方法结束时表示该线程结束
3.既然run方法是个示例方法,那么也就意味着可以调用本类中的其它实例方法,从而能够编写出较为复杂的功能。
P15 并发TCP服务器
案例:并发TCP服务器
1.引入
之前编写的TCP服务器虽然可以为多个客户端服务,但是它只能同一时刻为一个客户锅服务,只有当这个客户端关闭之后,才可以为下一个客户继服务"为了解决不能同时服务的问题,可以考虑使用多线程来完成TCP的服务器。
2.之前的单任务TCP服务器
参考代码
import socket
# 1.创建套接字
server_s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 2.绑定本地信息
server_s.bind(("",7890))
# 3.将套接字由默认的主动链接模式改为被动模式(监听模式)
server_s.listen(128)
# 4.等待客户端链接
new_s,client_info=server_s.accept()
print(client_info)
# 5.接收/发送数据
while True:
recv_content=new_s.recv(1024)
server_s.send('sc'.encode('utf-8'))
if len(recv_content) !=0:
print(recv_content)
else:
new_s.close()
break
# 6.关闭套接字
server_s.close()3.并发TCP服务
(1)服务器代码(老师课堂演示)
(1)最初版
import socket
import threading
class Handle(threading.Thread):
def __init__(self,client_socket):
super(Handle, self).__init__()
self.client_socket=client_socket
def run(self):
# 5.接收/发送数据
while True:
recv_content=self.client_socket.recv(1024)
if len(recv_content) !=0:
print(recv_content)
self.client_socket.send(recv_content)
else:
self.client_socket.close()
break
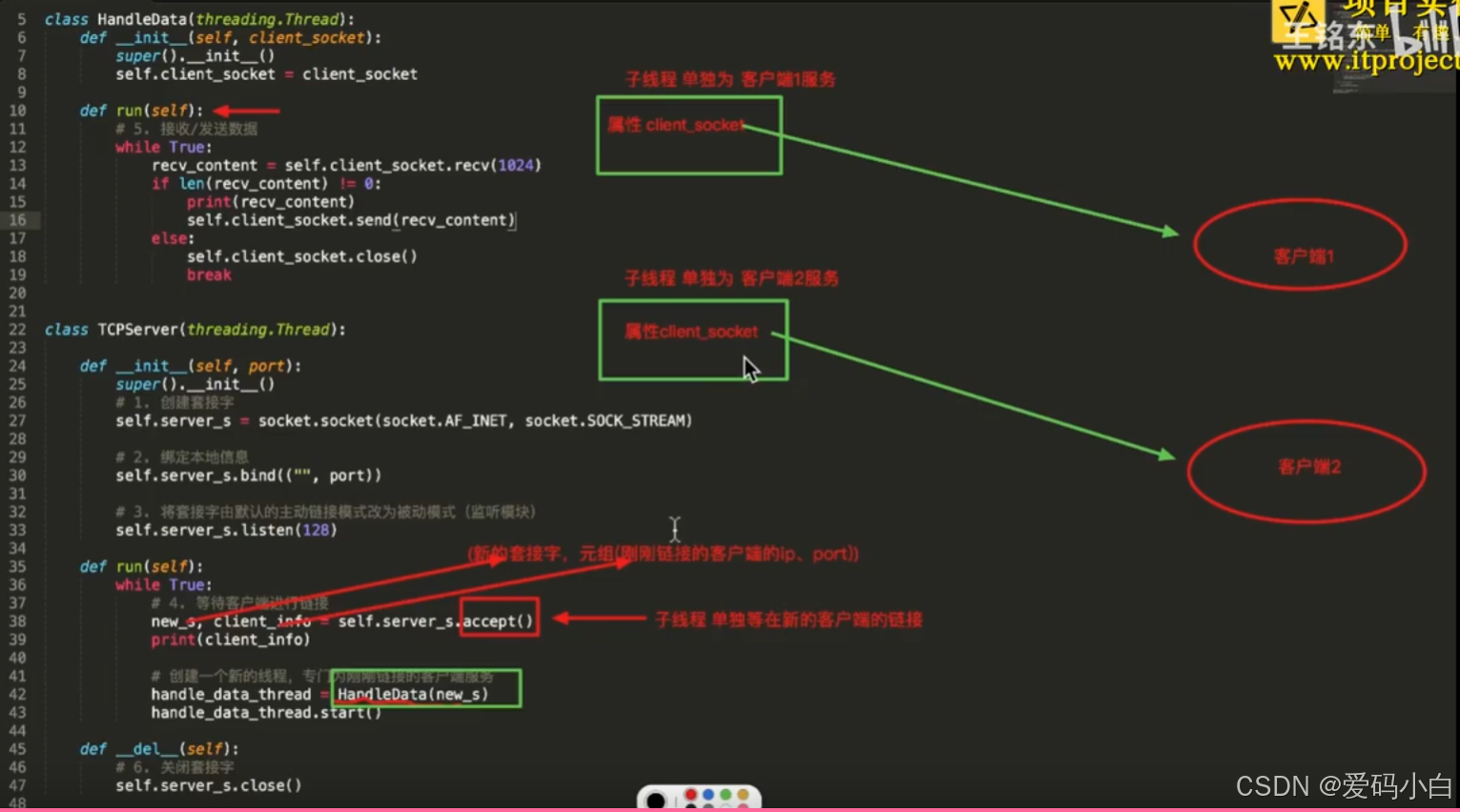
class TCPServer(threading.Thread):
def run(self):
# 1.创建套接字
server_s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 2.绑定本地信息
server_s.bind(("",7890))
# 3.将套接字由默认的主动链接模式改为被动模式(监听模式)
server_s.listen(128)
while True:
# 4.等待客户端链接
new_s,client_info=server_s.accept()
print(client_info)
# 创建一个新的线程,专门为刚刚链接的客户端服务
handle_data_thread = Handle(new_s)
handle_data_thread.start()
# 6.关闭套接字
server_s.close()
tcp_server = TCPServer()
tcp_server.start()
(2)升级版
import socket
import threading
class Handle(threading.Thread):
def __init__(self,client_socket):
super(Handle, self).__init__()
self.client_socket=client_socket
def run(self):
# 5.接收/发送数据
while True:
recv_content=self.client_socket.recv(1024)
if len(recv_content) !=0:
print(recv_content)
self.client_socket.send(recv_content)
else:
self.client_socket.close()
break
class TCPServer(threading.Thread):
def __init__(self,port):
super(TCPServer, self).__init__()
# 1.创建套接字
self.server_s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
# 2.绑定本地信息
self.server_s.bind(("",port))
# 3.将套接字由默认的主动链接模式改为被动模式(监听模式)
self.server_s.listen(128)
def run(self):
while True:
# 4.等待客户端链接
new_s,client_info=self.server_s.accept()
print(client_info)
# 创建一个新的线程,专门为刚刚链接的客户端服务
handle_data_thread = Handle(new_s)
handle_data_thread.start()
def __del__(self):
# 6.关闭套接字
self.server_s.close()
tcp_server = TCPServer(7890)
tcp_server.start()
(3)客户端代码(自己写的代码,为了同老师写的服务代码发数据)
import socket
# 1.创建socket对象
clientSocket=socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2.连接服务器
serverAdress=('192.168.43.152',7890)
clientSocket.connect(serverAdress)
# 3.发送数据
while True:
inputText=input("请输入发送信息内容:")
sentContent=inputText.encode("utf-8")
clientSocket.send(sentContent)
recvContent=clientSocket.recv(1024)
print(recvContent)
if inputText=="退出":
break
# 4.关闭对象
clientSocket.close()
(3)总结
a.老师在最初版代码中,实现了服务同时收发数据,并且自己在客户端代码参考老师的写法,也实现了收发数据。不管在服务器还是客户端的代码中,收发数据的对象原来都是客户端套接字socket,这一点同UDP不一样。
服务器收发代码(代码摘录):
# 5.接收/发送数据
while True:
recv_content=self.client_socket.recv(1024) # 服务器接收数据
if len(recv_content) !=0:
print(recv_content)
self.client_socket.send(recv_content) # 服务器发送数据
else:
self.client_socket.close()
break客户端收发代码(代码摘录):
while True:
inputText=input("请输入发送信息内容:")
sentContent=inputText.encode("utf-8") # 客户端发送数据
clientSocket.send(sentContent)
recvContent=clientSocket.recv(1024) # 客户端接收数据
print(recvContent)
if inputText=="退出":
breakb.在服务器升级版本代码中,王老师使用了魔法方法__del__() 关闭服务器对象server_s。自己这未掌握这一个魔法方法,课后需要好好学习一下,并将所学知识点补充至相应python笔记。
P16 再次理解并发TCP服务器
老师讲的这个案例有点绕,但是很精彩,要反复理解,感觉有点类似线程嵌套。
P17(补) threading中两种创建线程方式区别
两种创建线程的示例代码:
import time
import threading
def sing(name,num):
for i in range(num):
print(f"{name}正在唱歌,歌曲编号:{i+1}")
time.sleep(1)
class myThread(threading.Thread):
def __init__(self,name,num):
super(myThread, self).__init__()
self.name=name
self.num=num
def run(self):
sing(name=self.name,num=self.num)
# 创建线程方式1
t1=threading.Thread(target=sing,args=("张三",18))
t1.start()
# 创建线程方式2
t2=myThread("李四",26)
t2.start()
在Python中,使用threading.Thread创建线程的两种方式有以下区别:
1. 实现方式
-
方式1(直接使用
threading.Thread)
通过实例化threading.Thread类,直接指定target(目标函数)和args(参数)。线程启动时会调用target(*args)。python
复制
t1 = threading.Thread(target=sing, args=("张三", 18)) t1.start() -
方式2(自定义
Thread子类)
继承threading.Thread,重写run()方法,将线程逻辑封装在子类中。线程启动时自动调用重写的run()方法。python
复制
class myThread(threading.Thread): def __init__(self, name, num): super().__init__() self.name = name self.num = num def run(self): sing(name=self.name, num=self.num) t2 = myThread("李四", 26) t2.start()
2. 代码复用性
-
方式1
适合简单场景,逻辑直接绑定到函数sing。若需复用逻辑,需重复传递target和args,灵活性较低。 -
方式2
通过子类封装逻辑,可复用线程类。例如,多个线程共享相同逻辑时,只需创建不同实例并传递不同参数,代码更结构化。
3. 线程逻辑的封装
-
方式1
逻辑分散在外部函数中,适合简单任务。线程与目标函数解耦,但状态管理需依赖外部变量或参数。 -
方式2
逻辑和状态(如name、num)封装在类中,符合面向对象设计原则。适合复杂任务,尤其是需要维护内部状态或扩展功能(如添加额外方法)。
4. 扩展性
-
方式1
难以直接扩展线程行为(如添加生命周期钩子)。需通过包装函数或装饰器实现额外逻辑。 -
方式2
可重写start()、join()等方法,或在run()中添加异常处理、资源管理等逻辑,扩展性更强。
5. 代码风格
-
方式1
函数式编程风格,适合脚本或简单场景。 -
方式2
面向对象风格,适合模块化或大型项目。
总结
| 特性 | 方式1 | 方式2 |
|---|---|---|
| 实现复杂度 | 简单 | 稍复杂(需定义子类) |
| 复用性 | 低(依赖外部函数) | 高(通过实例化复用) |
| 封装性 | 低(逻辑与线程分离) | 高(逻辑和状态封装在类中) |
| 扩展性 | 弱(难以添加额外行为) | 强(可重写方法或添加功能) |
| 适用场景 | 简单任务、快速原型 | 复杂任务、需维护状态或扩展功能 |
选择建议
-
如果只是简单调用一个函数,方式1更简洁。
-
如果需要维护线程状态、扩展功能或复用逻辑,方式2更合适。
P18 threading.Thread和PyQt5中QThread区别
结合王铭东老师讲解,自己写的QTread练习代码(同老师课堂代码不同):
使用QThread的要点:
线程的变量名称必须设置为类属性,否则直接运行会出错误。这个调类似QTimer定义变量。
import sys
import time
from PyQt5.QtCore import QThread
from PyQt5.QtWidgets import *
def checkFile():
for i in range(20):
print(f"正在检查文件,编号:{i + 1}.........")
time.sleep(1)
def sing():
for i in range(20):
print(f"正在播放流行音乐,编号:{i + 1}.........")
time.sleep(1)
class MyThread(QThread):
def __init__(self,func):
self.func=func
super(MyThread, self).__init__()
def run(self):
self.func()
class MyWin(QWidget):
def __init__(self):
super(MyWin, self).__init__()
self.setWindowTitle("QThread")
self.setUI()
def setUI(self):
mainLay=QVBoxLayout()
self.setLayout(mainLay)
b1=QPushButton("检查文件")
b2=QPushButton("播放歌曲")
b1.clicked.connect(self.checkFile)
b2.clicked.connect(self.sing)
mainLay.addWidget(b1)
mainLay.addWidget(b2)
def checkFile(self):
self.t1=MyThread(func=checkFile) # todo 线程的变量必须设置为类属性,否则直接运行会出错误
self.t1.start() # todo 线程的变量必须设置为类属性,否则直接运行会出错误
def sing(self):
self.t2=MyThread(func=sing)
self.t2.start()
if __name__ == '__main__':
app = QApplication(sys.argv)
w = MyWin()
w.show()
app.exec()
另一个使用QThread案例
import sys
import os
import time
from PyQt5.QtWidgets import *
from PyQt5.QtCore import *
from PyQt5.QtGui import *
from datetime import datetime
class AppThread(QThread):
signal=pyqtSignal()
def __init__(self):
super(AppThread, self).__init__()
def run(self):
while True:
if datetime.now()>datetime(2025,6,14,18,12,0):
self.signal.emit()
break
time.sleep(1)
def stop(self):
self.running = False # 安全停止线程
self.wait(500) # 等待线程退出(500ms超时)
class MyWin(QWidget):
def __init__(self):
super(MyWin, self).__init__()
self.setUI()
def setUI(self):
mainlay=QVBoxLayout()
self.setLayout(mainlay)
self.button=QToolButton()
self.button.setText("检测VIP")
mainlay.addWidget(self.button)
self.t1=AppThread()
self.t1.start()
self.t1.signal.connect(self.setButtonText)
def setButtonText(self):
self.button.setText("VIP已失效")
if __name__ == '__main__':
app = QApplication(sys.argv)
window = MyWin()
window.show()
sys.exit(app.exec_())在Python中,threading.Thread(标准库)和PyQt5中的QThread(GUI框架的多线程模块)在多线程实现上有显著区别。以下是它们的核心差异分析:
1. 设计目的
-
threading.Thread-
是Python标准库提供的通用多线程工具,不依赖GUI框架。
-
用于非GUI场景下的多线程任务(如数据处理、网络请求)。
-
-
QThread-
是PyQt5框架的一部分,专为GUI应用设计。
-
核心目标是避免主线程(GUI线程)阻塞,确保界面响应流畅。
-
与Qt的事件循环(Event Loop)和信号槽机制深度集成。
-
2. 线程与事件循环
-
threading.Thread-
无内置事件循环,线程逻辑通过函数或类的
run()方法直接执行。 -
需要手动管理线程的执行和终止。
-
示例:
python
复制
import threading def task(): print("Thread running") t = threading.Thread(target=task) t.start()
-
-
QThread-
默认绑定Qt事件循环,通过重写
run()方法并调用exec_()启动事件循环。 -
可通过信号槽(Signals/Slots)与其他线程(如主线程)通信。
-
示例:
python
复制
from PyQt5.QtCore import QThread, pyqtSignal class Worker(QThread): finished = pyqtSignal() def run(self): print("QThread running") self.finished.emit() thread = Worker() thread.start()
-
3. 线程间通信
-
threading.Thread-
使用共享变量、
queue.Queue或同步原语(如锁Lock、信号量Semaphore)。 -
需要开发者手动处理线程安全,容易引发竞态条件(Race Condition)。
-
示例:通过队列传递数据:
python
复制
import queue q = queue.Queue() def producer(): q.put("Data") def consumer(): print(q.get())
-
-
QThread-
通过信号槽机制实现线程间通信,天然线程安全。
-
子线程通过信号通知主线程更新UI或传递数据,避免直接操作GUI组件。
-
示例:子线程发送信号,主线程更新界面:
python
复制
class Worker(QThread): result_ready = pyqtSignal(str) def run(self): data = "Result from QThread" self.result_ready.emit(data) class MainWindow(QMainWindow): def __init__(self): super().__init__() self.worker = Worker() self.worker.result_ready.connect(self.update_ui) def update_ui(self, data): self.label.setText(data)
-
4. 与GUI的交互
-
threading.Thread-
不能在非主线程中直接更新GUI(如PyQt5的控件操作),否则会导致程序崩溃或未定义行为。
-
需要通过
pyqtSignal或QMetaObject.invokeMethod将更新操作抛回主线程。
-
-
QThread-
与GUI线程完全解耦,通过信号槽机制自动将UI操作切换到主线程执行。
-
是PyQt5中唯一安全的更新UI的方式。
-
5. 资源管理
-
threading.Thread-
线程的生命周期由Python解释器管理,结束时自动释放资源。
-
需注意全局解释器锁(GIL)对CPU密集型任务的限制。
-
-
QThread-
需要显式管理线程的启动和终止(如调用
quit()和wait())。 -
推荐将耗时任务封装到
QObject子类中,并通过moveToThread将其移到新线程(更灵活)。
-
6. 异常处理
-
threading.Thread-
子线程中的异常不会传递到主线程,可能导致静默崩溃。
-
需通过
sys.excepthook或自定义异常捕获逻辑。
-
-
QThread-
可通过信号将异常传递到主线程统一处理。
-
示例:
python
复制
class Worker(QThread): error_occurred = pyqtSignal(Exception) def run(self): try: # 任务代码 except Exception as e: self.error_occurred.emit(e)
-
7. 适用场景对比
| 场景 | threading.Thread | QThread |
|---|---|---|
| 非GUI程序 | ✔️ 推荐 | ❌ 不必要 |
| PyQt5 GUI程序 | ❌ 需额外处理线程安全 | ✔️ 推荐(天然集成信号槽) |
| CPU密集型任务 | ❌ 受GIL限制 | ❌ 同样受GIL限制 |
| I/O密集型任务 | ✔️ 适合 | ✔️ 适合(需结合事件循环) |
| 跨线程更新UI | ❌ 不安全 | ✔️ 唯一安全方式 |
总结
-
threading.Thread:
适合简单的多线程任务(非GUI场景),需手动处理线程同步和通信。 -
QThread:
专为PyQt5设计,通过信号槽机制实现线程安全和UI更新,是GUI应用中处理耗时操作的唯一推荐方式。
核心优势:避免直接操作共享资源,简化线程间通信,天然集成Qt事件循环。
选择建议
-
如果开发PyQt5 GUI应用,优先使用
QThread,尤其是需要更新界面时。 -
如果编写非GUI脚本或需要跨平台兼容性,使用
threading.Thread。 -
在PyQt5中,避免混用两种线程模型,否则可能导致不可预见的错误。
第二部分 队列
01-队列Queue
队列(Queue),除了有单独的队列库,多进程库multiprocessing中也有一个类叫队列multiprocessing.Queue,进程间的通信,则会用到这个库。
1.为什么要用队列
多任务程序,有很多时候,需要相互配合才能完成一件有意义的事情。例如:
一个线程专门用来接收数据。
另外一个线程专门用来存储刚刚搜收的数据。
如果用要押以上2个线程相互配合。那么理论上来说,效率会很高。但是线程中的变量各自是各自的。为了能够让多个线程之间共享某些数据。就可以使用以列来实现数据共享。
2.什么是队列
现实生活中

程序中
一种特殊的存储数据的方式,可以实现先存入的数据,先出去。
3. 怎样使用
3.1队列Queue
代码演示:
import queue
q=queue.Queue()
q.put('11')
q.put(22)
q.put({"num":100})
print(q.get()) # 11
print(q.get()) # 22
print(q.get()) # {'num': 100}小结:
1.先进先出(FIFO)。
2.可以存放任意类型数据。
3.使用put放数据
4.使用get取数据(如果当前队列中没有数据,此时会堵塞)
3.2堆栈队列
代码演示:
import queue
q=queue.LifoQueue()
q.put('11')
q.put(22)
q.put({"num":100})
print(q.get()) # {'num': 100}
print(q.get()) # 22
print(q.get()) # 11小结:
1.后进先出(LIFO)。
2.可以存放任意数据类型。
3.3优先级队列
代码演示:
import queue
q=queue.PriorityQueue()
q.put((10,"Q"))
q.put((30,"Z"))
q.put((20,"A"))
print(q.get()) # (10, 'Q')
print(q.get()) # (20, 'A')
print(q.get()) # (30, 'Z')小结:
1.存放的数据是元组类型,第1个元素表示优先级,第2个元素表示存储的数据。
2.优先级数字越小优先级越高
3.数据优先级高的优先被取出
4.用于VIP用户数据优先被取出场景,因为上面两种都要挨个取出 。
5.(自己补充)取出的数据是元组,如果需要使用数据,则需要给元拆包。
02-分析:带有聊天记录的UDP聊天程序
03-实现:带有聊天记录的UDP聊天程序
第三部分 线程锁
学历历程:
1.线程锁这块内容,一开始学习的是王铭东老师的讲得,但是仅讲了一个互斥锁Lock,感觉讲得不够全面,查阅资料发现有5种线程锁需要学习。
2.在B站上面查了很多博主的课,发现很难找到讲得清晰易懂的。最后发现名为“这里有个橙(账号:20077378)”讲得很全面,但是不够深入。于是结合豆包查找找的资料,编写了这部分笔记。笔记中关于应用场部分的内容即来源于此。
3.经过思索,决定将关于王铭东老师部分的笔记,降级为学习线程锁的参考资料。
01-互斥锁
1.代码示例
import time
from threading import Thread,Lock
gvar=0
def childTask(i,lock:Lock):
lock.acquire()
global gvar
gvar=i
time.sleep(0.005)
print(f"{gvar} is {i}")
lock.release()
if __name__=="__main__":
l = Lock()
threads=[Thread(target=childTask,args=(i,l)) for i in range(100)]
for thread in threads:
thread.start()2.方法解析
(1)lock.acquire()
(2)lock.release()
3.应用场景
Lock 是 Python threading 模块中的一个类,它是一种基本的同步原语,用于在多线程环境中实现互斥锁,确保同一时间只有一个线程可以访问共享资源或执行临界区代码。以下是 Lock 的一些常见应用场景:
1. 保护共享资源
在多线程环境中,当多个线程需要访问或修改共享资源(如全局变量、文件、网络连接等)时,使用 Lock 可以确保每次只有一个线程对其进行操作,防止数据竞争和不一致性。
收起
python
import threading
def increment(counter, lock):
for _ in range(1000):
with lock:
counter[0] += 1
if __name__ == "__main__":
counter = [0]
lock = threading.Lock()
threads = []
for _ in range(10):
t = threading.Thread(target=increment, args=(counter, lock))
threads.append(t)
t.start()
for t in threads:
t.join()
print(f"Counter value: {counter[0]}")
在这个例子中,多个线程尝试递增 counter 的值。使用 Lock 可以确保每次只有一个线程执行 counter[0] += 1,避免了并发修改导致的结果不一致。
2. 保护临界区代码
临界区是指一段代码,在同一时间只能由一个线程执行。Lock 可以用来保护这些代码块,防止多个线程同时进入临界区。
收起
python
import threading
def critical_section(lock):
with lock:
print(f"{threading.current_thread().name} is in critical section")
if __name__ == "__main__":
lock = threading.Lock()
threads = []
for i in range(5):
t = threading.Thread(target=critical_section, args=(lock,))
threads.append(t)
t.start()
for t in threads:
t.join()
3. 避免死锁
在多个锁的情况下,需要确保线程以相同的顺序获取锁,以避免死锁。Lock 可以帮助你实现这一点,虽然它本身不能解决死锁问题,但合理使用可以避免因竞争条件导致的死锁。
收起
python
import threading
def task1(lock1, lock2):
with lock1:
print(f"{threading.current_thread().name} acquired lock1")
with lock2:
print(f"{threading.current_thread().name} acquired lock2")
def task2(lock1, lock2):
with lock2:
print(f"{threading.current_thread().name} acquired lock2")
with lock1:
print(f"{threading.current_thread().name} acquired lock1")
if __name__ == "__main__":
lock1 = threading.Lock()
lock2 = threading.Lock()
t1 = threading.Thread(target=task1, args=(lock1, lock2))
t2 = threading.Thread(target=task2, args=(lock1, lock2))
t1.start()
t2.start()
t1.join()
t2.join()
4. 线程间通信
在一些情况下,Lock 可以作为线程间通信的一部分,例如,当一个线程需要等待另一个线程完成某项操作时,可以使用 Lock 来实现简单的信号机制。
收起
python
import threading
def worker(lock):
print(f"{threading.current_thread().name} is working")
# 模拟工作
time.sleep(1)
lock.release()
if __name__ == "__main__":
lock = threading.Lock()
lock.acquire()
t = threading.Thread(target=worker, args=(lock,))
t.start()
lock.acquire() # 等待 worker 线程释放锁
print(f"{threading.current_thread().name} is done waiting")
t.join()
总结
- 保护共享资源:确保对共享资源的操作是线程安全的,避免数据竞争。
- 保护临界区代码:确保同一时间只有一个线程进入临界区,防止并发执行导致的问题。
- 避免死锁:通过合理使用锁顺序,避免多个锁之间的死锁。
- 线程间通信:可作为简单的信号机制,使线程可以等待其他线程的操作完成。
使用 Lock 可以帮助你在多线程环境中避免各种并发问题,如数据竞争、不一致性和死锁等。但要注意,在使用 Lock 时,需要确保锁的获取和释放操作的正确性,避免出现死锁或长时间等待的情况。同时,对于更复杂的线程同步需求,可能需要使用 RLock、Semaphore、Condition 或 Event 等其他同步原语。
02-重复锁
1.示例代码
import time
from threading import Thread,RLock
gvar=0
def childTask(i,lock:RLock):
lock.acquire()
lock.acquire()
global gvar
gvar=i
time.sleep(0.005)
print(f"{gvar} is {i}")
lock.release()
lock.release()
if __name__=="__main__":
l = RLock() # 可重复锁,使用时上锁次数必须同解锁次数相同;如果加锁的次数大于解锁的次数,程序阻塞;如果加锁次数小于解锁次数,则程序报错。
threads=[Thread(target=childTask,args=(i,l)) for i in range(100)]
for thread in threads:
thread.start()2.方法解析
lock.acquire()和lock.release()这两个方法同Lock中的方法用途相同,分别是上锁和解锁的意思。 RLock和Lock的区别之处在于:RLock可重复锁,使用时上锁次数必须同解锁次数相同;如果加锁的次数大于解锁的次数,程序阻塞;如果加锁次数小于解锁次数,则程序报错。
3.应用场景
RLock(可重入锁)是 Python threading 模块中的一种锁,它允许同一个线程多次获取同一个锁而不会导致死锁。以下是 RLock 的一些常见应用场景:
1. 递归函数中的锁
在递归函数中,如果需要对共享资源进行加锁操作,RLock 可以确保在递归调用时不会出现死锁。
收起
python
import threading
def recursive_function(lock, depth):
if depth == 0:
return
with lock:
print(f"Depth: {depth}")
recursive_function(lock, depth - 1)
if __name__ == "__main__":
rlock = threading.RLock()
thread = threading.Thread(target=recursive_function, args=(rlock, 5))
thread.start()
thread.join()
在这个例子中,recursive_function 是一个递归函数,它会多次获取 rlock。使用 RLock 可以确保在递归调用时不会因为重复获取锁而导致死锁。
2. 复杂的类方法调用
当一个类的多个方法需要加锁,且这些方法可能相互调用时,RLock 可以避免死锁。
收起
python
import threading
class MyClass:
def __init__(self):
self.lock = threading.RLock()
def method_a(self):
with self.lock:
print("Method A")
self.method_b()
def method_b(self):
with self.lock:
print("Method B")
if __name__ == "__main__":
obj = MyClass()
thread = threading.Thread(target=obj.method_a)
thread.start()
thread.join()
在这个例子中,method_a 调用了 method_b,并且它们都需要加锁。使用 RLock 可以确保在 method_a 调用 method_b 时不会发生死锁。
3. 多个相关操作的原子性
当多个操作需要作为一个整体原子操作执行,并且这些操作可能调用其他需要相同锁的操作时,RLock 可以保证它们的原子性。
收起
python
import threading
class Counter:
def __init__(self):
self.value = 0
self.lock = threading.RLock()
def increment(self):
with self.lock:
self.value += 1
self.print_value()
def print_value(self):
with self.lock:
print(f"Value: {self.value}")
if __name__ == "__main__":
counter = Counter()
threads = []
for i in range(5):
t = threading.Thread(target=counter.increment)
threads.append(t)
t.start()
for t in threads:
t.join()
4. 保护共享数据结构
在多线程环境中,当对共享数据结构进行修改和访问时,RLock 可以确保数据的一致性。
收起
python
import threading
class SharedList:
def __init__(self):
self.data = []
self.lock = threading.RLock()
def append(self, item):
with self.lock:
self.data.append(item)
self.print_list()
def print_list(self):
with self.lock:
print(f"List: {self.data}")
if __name__ == "__main__":
shared_list = SharedList()
threads = []
for i in range(5):
t = threading.Thread(target=shared_list.append, args=(i,))
threads.append(t)
t.start()
for t in threads:
t.join()
总结
- 递归函数:确保在递归调用时不会因为重复获取锁而死锁。
- 类方法调用:当类的多个方法需要加锁且相互调用时,避免死锁。
- 多个相关操作的原子性:保证多个操作作为一个整体原子操作,即使这些操作相互调用。
- 保护共享数据结构:确保在多线程环境中对共享数据结构的修改和访问的一致性。
RLock 是一个很有用的工具,它允许同一个线程多次获取锁,避免了在复杂的多线程代码中出现死锁的情况,提高了程序的稳定性和可靠性。它尤其适用于涉及递归、类的复杂方法调用以及需要保证多个操作原子性的场景。
解释一下什么是锁以及它在多线程编程中的作用
除了`RLock`,Python中还有哪些类型的锁?
如何正确使用`RLock`来避免死锁?
03-信号量锁
1.示例代码
import time
from threading import Thread,Semaphore
gvar=0
def childTask(i, semaphore:Semaphore):
semaphore.acquire() # lock.acquire():尝试获取信号量,如果信号量的值大于 0,则将其减 1 并继续执行;如果信号量的值为 0,则阻塞,直到有其他线程释放信号量。
global gvar
gvar=i
time.sleep(0.005)
print(f"{gvar} is {i}")
semaphore.release() # lock.release():释放信号量,将信号量的值加 1,允许其他等待的线程获取信号量。
if __name__=="__main__":
s = Semaphore(value=5) # windows系统自带的机制,信号量为0时解锁,默认参数的value的初始值是1
threads=[Thread(target=childTask, args=(i, s)) for i in range(100)]
for thread in threads:
thread.start()2.使用方法
(1)s = Semaphore(value=5)
s = Semaphore(value=5)
# 创建流量锁。value的默认参数值为1。
# (个人理解)此例相当于使用该时,最多一允许5个线程同时运行。(2)semaphore.acquire()
semaphore.acquire()
# 作用:尝试获取信号量,如果信号量的值大于 0,则将其减 1 并继续执行;如果信号量的值
为 0,则阻塞,直到有其他线程释放信号量。(3)semaphore.release()
semaphore.release()
# 作用:释放信号量,将信号量的值加 1,允许其他等待的线程获取信号量。3.应用场景
以下是 Python 中 Semaphore 的一些常见应用场景:
一、资源池管理
Semaphore 可用于管理有限的资源池,例如数据库连接池、线程池或文件句柄池。你可以将 Semaphore 的初始值设置为资源的数量,当线程需要使用资源时,获取信号量;使用完资源后,释放信号量。这样可以确保同时使用资源的线程数量不超过资源的总量。
import threading
import time
class ResourcePool:
def __init__(self, size):
self.semaphore = threading.Semaphore(size)
self.resources = [f"Resource-{i}" for i in range(size)]
def acquire_resource(self):
self.semaphore.acquire()
resource = self.resources.pop()
return resource
def release_resource(self, resource):
self.resources.append(resource)
self.semaphore.release()
def worker(pool, worker_id):
resource = pool.acquire_resource()
print(f"Worker {worker_id} acquired {resource}")
time.sleep(1) # 模拟使用资源
pool.release_resource(resource)
print(f"Worker {worker_id} released {resource}")
if __name__ == "__main__":
pool = ResourcePool(3)
threads = []
for i in range(10):
t = threading.Thread(target=worker, args=(pool, i))
threads.append(t)
t.start()
for t in threads:
t.join()代码解释: ResourcePool 类管理资源池,self.semaphore = threading.Semaphore(size) 创建一个初始值为 size 的信号量。 acquire_resource 方法中,self.semaphore.acquire() 尝试获取信号量,如果没有可用资源,线程将阻塞。 release_resource 方法中,self.semaphore.release() 释放信号量,使其他线程可以使用资源。 在 worker 函数中,线程尝试获取和释放资源,模拟资源的使用。
二、流量控制
Semaphore 可以用于限制并发访问某些服务或 API 的线程数量,以避免服务过载。例如,限制同时访问某个外部 API 的并发请求数量。
import threading
import requests
import time
semaphore = threading.Semaphore(5)
def fetch_url(url):
with semaphore:
print(f"Fetching {url}")
response = requests.get(url)
print(f"Received {response.status_code} from {url}")
time.sleep(1)
if __name__ == "__main__":
urls = ["https://example.com"] * 20
threads = []
for url in urls:
t = threading.Thread(target=fetch_url, args=(url,))
threads.append(t)
t.start()
for t in threads:
t.join()代码解释: semaphore = threading.Semaphore(5) 限制了最多 5 个线程同时访问 fetch_url 函数。 with semaphore: 语句会自动获取和释放信号量,确保最多 5 个线程同时调用 requests.get(url),避免同时发送过多请求导致的服务过载。
三、生产者 - 消费者问题的变体
在生产者 - 消费者问题中,如果生产者的速度远快于消费者,可以使用 Semaphore 来限制生产者的速度,防止缓冲区溢出。
import threading
import queue
import time
q = queue.Queue(maxsize=10)
semaphore = threading.Semaphore(10)
def producer():
for i in range(20):
semaphore.acquire()
q.put(i)
print(f"Produced {i}")
time.sleep(0.1)
def consumer():
while True:
if not q.empty():
item = q.get()
print(f"Consumed {item}")
semaphore.release()
time.sleep(0.2)
if __name__ == "__main__":
t1 = threading.Thread(target=producer)
t2 = threading.Thread(target=consumer)
t1.start()
t2.start()
t1.join()
t2.join()代码解释: semaphore = threading.Semaphore(10) 用于限制队列中元素的数量不超过 10。 生产者线程在 producer 函数中,使用 semaphore.acquire() 来确保队列元素不超过 10。 消费者线程在 consumer 函数中,使用 semaphore.release() 释放信号量,允许生产者继续生产。
四、多线程任务调度
当你有多个任务需要在有限的线程中执行时,可以使用 Semaphore 来调度这些任务。
import threading
import time
semaphore = threading.Semaphore(3)
def task(id):
with semaphore:
print(f"Task {id} started")
time.sleep(2)
print(f"Task {id} finished")
if __name__ == "__main__":
tasks = [threading.Thread(target=task, args=(i,)) for i in range(10)]
for t in tasks:
t.start()
for t in tasks:
t.join()代码解释: semaphore = threading.Semaphore(3) 限制同时执行的任务数量为 3。 with semaphore: 确保同时只有 3 个任务在执行,其他任务将等待。
五、注意事项
确保在使用 Semaphore 时,调用 acquire 后,一定会在适当的时候调用 release,否则可能会导致死锁或资源泄漏。 对于复杂的同步需求,可能需要结合其他同步原语(如 Lock、Condition 等)来实现更精确的控制。 考虑使用 BoundedSemaphore 来避免信号量的值超过初始值,防止一些逻辑错误。 通过合理使用 Semaphore,可以有效地控制并发资源的使用,防止资源耗尽或服务过载,同时确保程序的性能和稳定性。
04 条件锁
1.示例代码
from threading import Thread,Condition
g_num=0
def consumer(con:Condition,id):
global g_num
with con:
print(f"消费者{id}正在等待...")
con.wait()
g_num-=1
print(f"消费者{id}消费了1个商品")
def producer(con:Condition):
global g_num
with con:
print("厂家生产了10个商品")
g_num+=10
con.notify_all() # 唤醒所有等待的线程
# con.notify() # 唤醒参数为n的等待线程
if __name__=="__main__":
condition = Condition()
cs=[Thread(target=consumer,args=(condition,i)) for i in range(5)]
for c in cs:
c.start()
p=Thread(target=producer,args=(condition,))
p.start()
2.方法解析
(1)con.wait(timeout)
con.wait(timeout=None)
# 作用timeout:让线程处于阻塞状态。
如果不传入参数值,则程序会一直处于阻塞状态,直至事件锁被唤醒。
如果传入参数值,则事件锁让线程阻塞timeout秒。(2)con.notify(n)
# 作用:唤醒n个等待的的线程,使其继续向下运行。n的默认值为1.(3)con.notify_all() # 唤醒所有等待的线程
con.notify_all()
# 作用:唤醒所有等待的线程,使其继续向下运行。3. 应用场景
在 Python 的 threading 模块中,Condition 是一个非常强大的同步原语,它结合了 Lock 和 Event 的功能,为线程间的通信和同步提供了更高级和灵活的机制。以下是 Condition 的一些主要应用场景:
1. 生产者 - 消费者问题:
收起
python
from threading import Thread, Condition, Lock
import time
def consumer(condition, id):
with condition:
while True:
print(f"Consumer {id} is waiting...")
condition.wait()
print(f"Consumer {id} consumed an item")
def producer(condition):
with condition:
for i in range(10):
print(f"Producer produced item {i}")
condition.notify()
time.sleep(1)
if __name__ == "__main__":
condition = Condition()
consumers = [Thread(target=consumer, args=(condition, i)) for i in range(3)]
producer_thread = Thread(target=producer, args=(condition,))
for c in consumers:
c.start()
producer_thread.start()
解释:
- 在这个场景中,生产者线程会产生一些数据或资源,而消费者线程会消耗这些数据或资源。
- 消费者线程调用
condition.wait()等待生产者的通知。 - 生产者线程在生产数据后调用
condition.notify()或condition.notify_all()通知消费者线程。
2. 资源池管理:
收起
python
from threading import Thread, Condition, Lock
import time
class ResourcePool:
def __init__(self, size):
self.size = size
self.available = size
self.condition = Condition(Lock())
def acquire(self):
with self.condition:
while self.available == 0:
print("No resources available. Waiting...")
self.condition.wait()
self.available -= 1
print(f"Resource acquired. Available: {self.available}")
def release(self):
with self.condition:
self.available += 1
print(f"Resource released. Available: {self.available}")
self.condition.notify()
def worker(pool, id):
for i in range(3):
pool.acquire()
print(f"Worker {id} is using resource")
time.sleep(1)
pool.release()
if __name__ == "__main__":
pool = ResourcePool(2)
threads = [Thread(target=worker, args=(pool, i)) for i in range(5)]
for t in threads:
t.start()
解释:
ResourcePool类管理一定数量的资源。acquire()方法会在没有可用资源时阻塞线程,直到有资源释放。release()方法会释放资源并通知等待的线程。
3. 任务调度和依赖:
收起
python
from threading import Thread, Condition, Lock
import time
def task1(condition):
with condition:
print("Task 1 is running")
time.sleep(2)
condition.notify()
def task2(condition):
with condition:
print("Task 2 is waiting for Task 1")
condition.wait()
print("Task 2 is running after Task 1")
if __name__ == "__main__":
condition = Condition()
t1 = Thread(target=task1, args=(condition,))
t2 = Thread(target=task2, args=(condition,))
t2.start()
t1.start()
解释:
task2依赖于task1的完成。task2会等待,直到task1完成并调用condition.notify()通知它。
4. 多线程数据处理:
收起
python
from threading import Thread, Condition, Lock
import time
def data_processor(condition, input_data, processed_data):
with condition:
while not input_data:
print("Waiting for data...")
condition.wait()
data = input_data.pop(0)
processed_data.append(data * 2)
print(f"Processed data: {data * 2}")
condition.notify()
if __name__ == "__main__":
input_data = []
processed_data = []
condition = Condition()
threads = [Thread(target=data_processor, args=(condition, input_data, processed_data)) for _ in range(3)]
for t in threads:
t.start()
with condition:
for i in range(5):
input_data.append(i)
condition.notify()
time.sleep(1)
解释:
- 多个线程在
data_processor函数中等待数据。 - 主线程将数据添加到
input_data列表并通知处理器线程。
5. 线程间的有序执行:
收起
python
from threading import Thread, Condition, Lock
def thread1(condition):
with condition:
print("Thread 1 is running")
condition.notify()
condition.wait()
print("Thread 1 is running again")
def thread2(condition):
with condition:
condition.wait()
print("Thread 2 is running")
condition.notify()
if __name__ == "__main__":
condition = Condition()
t1 = Thread(target=thread1, args=(condition,))
t2 = Thread(target=thread2, args=(condition,))
t2.start()
t1.start()
解释:
- 确保
thread2在线程t1完成第一部分后开始运行,并且thread1在thread2完成后继续运行。
总结:
Condition提供了一种灵活的方式,使线程可以在某些条件下等待和唤醒。- 它可以用于协调多个线程之间的执行顺序、资源共享和任务依赖。
- 它通常与
with语句结合使用,以确保锁的正确获取和释放。 - 可以使用
notify()唤醒一个等待的线程,或notify_all()唤醒所有等待的线程。
使用 Condition 时,需要注意以下几点:
- 调用
wait()会释放锁,让其他线程可以获取锁并修改共享资源。 - 调用
notify()或notify_all()时,必须在持有锁的情况下进行,以确保通知的线程能够正确地获取锁和继续执行。 - 确保
wait()和notify()/notify_all()的调用顺序和逻辑正确,避免死锁和饥饿。
05 事件锁
1.示例代码
from threading import Thread,Event
g_num=0
def consumer(e:Event, id):
global g_num
print(f"消费者{id}正在等待...")
e.wait()
g_num -= 1
print(f"消费者{id}消费了1个商品")
def producer(con:Event):
global g_num
print("厂家生产了10个商品")
g_num += 10
con.set()
if __name__=="__main__":
event = Event()
cs=[Thread(target=consumer, args=(event, i)) for i in range(5)]
for c in cs:
c.start()
p=Thread(target=producer, args=(event,))
p.start()
2.方法解析
(1)event.wait(timeout=None)
event.wait(timeout=None)
# 作用timeout:让线程处于阻塞状态。
如果不传入参数值,则程序会一直处于阻塞状态,直至事件锁被唤醒。
如果传入参数值,则事件锁让线程阻塞timeout秒。(2)event.set()
event.set()
# 作用:调用此方法时,所有调用了event.wait()的线程将被唤醒,即允许向下运行。3.应用场景
Event 类在以下场景中非常有用:
(1)线程同步:例如,一个线程需要等待另一个线程完成某个操作后才能继续执行。
(2)条件等待:线程可以等待某个条件的发生,一旦条件满足,通过 set() 方法通知等待的线程。
4.豆包资料:python Evevt().set()含义
在 Python 的 threading 模块中,Event 类是一种线程间通信的机制,Event().set() 方法的含义如下:
1. 创建 Event 对象:
收起
python
event = Event()
当你调用 Event() 时,会创建一个新的 Event 对象。这个对象内部有一个标志(通常称为 “内部标志” 或 “信号标志”),初始状态是未设置的(False)。
2. set() 方法的作用:
收起
python
event.set()
set()方法将Event对象的内部标志设置为True。- 一旦
Event对象的内部标志被设置为True,所有调用了event.wait()并正在等待这个Event的线程将被唤醒。 - 当一个线程调用
event.wait()时,它会阻塞,直到event的内部标志为True。当你调用event.set()时,就相当于给那些正在等待的线程发送了一个信号,让它们可以继续执行。
以下是一个简单的示例代码,演示了 Event 的使用:
收起
python
from threading import Thread, Event
import time
def worker(event):
print("Worker is waiting for the event.")
event.wait()
print("Worker has received the event and is now running.")
if __name__ == "__main__":
# 创建一个 Event 对象
event = Event()
# 创建一个工作线程
t = Thread(target=worker, args=(event,))
t.start()
# 模拟一些其他操作
print("Main thread is doing something else.")
time.sleep(2)
# 设置 Event,唤醒等待的线程
event.set()
代码解释:
- 首先,导入
Thread和Event类以及time模块。 - 定义了一个
worker函数,它将被线程调用。- 该函数首先打印出它正在等待事件。
- 然后调用
event.wait(),线程将阻塞在这里,等待事件的发生。
- 在主程序中:
- 创建一个
Event对象event。 - 创建一个线程
t,并将event作为参数传递给worker函数,然后启动该线程。 - 主程序模拟一些其他操作(这里使用
time.sleep(2)来表示)。 - 最后调用
event.set(),将Event的内部标志设置为True,从而唤醒等待的worker线程。
- 创建一个
Event 类在以下场景中非常有用:
- 线程同步:例如,一个线程需要等待另一个线程完成某个操作后才能继续执行。
- 条件等待:线程可以等待某个条件的发生,一旦条件满足,通过
set()方法通知等待的线程。
需要注意的是,Event 的内部标志一旦被 set() 为 True,它将保持为 True,除非你显式地调用 event.clear() 将其重置为 False。如果需要反复使用 Event 进行线程间的同步,可以在适当的时候调用 event.clear() 重置标志,以便再次使用 event.wait() 让线程等待。
以下是一个更复杂的示例,展示了如何多次使用 Event:
收起
python
from threading import Thread, Event
import time
def worker(event):
while True:
print("Worker is waiting for the event.")
event.wait()
print("Worker has received the event and is now running.")
event.clear() # 重置 Event 标志
if __name__ == "__main__":
event = Event()
t = Thread(target=worker, args=(event,))
t.start()
for i in range(5):
print(f"Main thread is triggering the event for the {i+1}th time.")
event.set()
time.sleep(1)
代码解释:
worker函数包含一个while True循环,使其可以多次等待Event。- 每次调用
event.wait()等待事件。 - 当收到事件后,执行操作,然后调用
event.clear()重置Event标志。
- 每次调用
- 在主程序中,使用一个
for循环多次触发Event,每次触发后等待 1 秒。
这样,worker 线程会不断地等待事件、接收事件、执行操作、重置事件,循环进行,而主程序可以多次触发事件。
06 参考资料:王铭东讲课内容
01-线程之间共享全局变量
1.老师课堂演示代码
import threading
import time
# 1.定义一个全局变量
g_num=0
#2.定义2个函数,用他们来充当线程要执行的代码
def task1():
global g_num
g_num=100
print(f'在task1中g_num:{g_num}')
def task2():
print(f'在task2中g_num:{g_num}')
# 3.创建线程对象
t1=threading.Thread(target=task1)
t2=threading.Thread(target=task1)
# 4.调用start创建线程,让线程开始适行
t1.start()
time.sleep(1) # 让主线程延时一会儿,保证让task1这个任务先执行完毕
t2.start()2.自己用类写同样功能代码
import threading
import time
g_num=0
class Task1(threading.Thread):
def run(self):
global g_num
g_num=100
print(f'在Task1中g_num:{g_num}')
class Task2(threading.Thread):
def run(self):
print(f"在Task2中g_num:{g_num}")
t1=Task1()
t1.start()
time.sleep(1) # 为了保证让线程t1先运行,从而保存t2运行时g_num已经被修改成100
t2=Task2()
t2.start()
3.小结
1.如果一个程序有多个线程,每个线程可以单独执行自己的任务。
2.如果多个线程之间需要数据共享,最简单的方式是,通过全局变量来实现。
(1)一个线程修改全局变量。
(2)另外一个线程从全局变量中获取数据。
02-线程共享全局变量:资源竞争问题1
03-线程共享全局变量:资源竞争问题2
多线程-共享全局变量问题
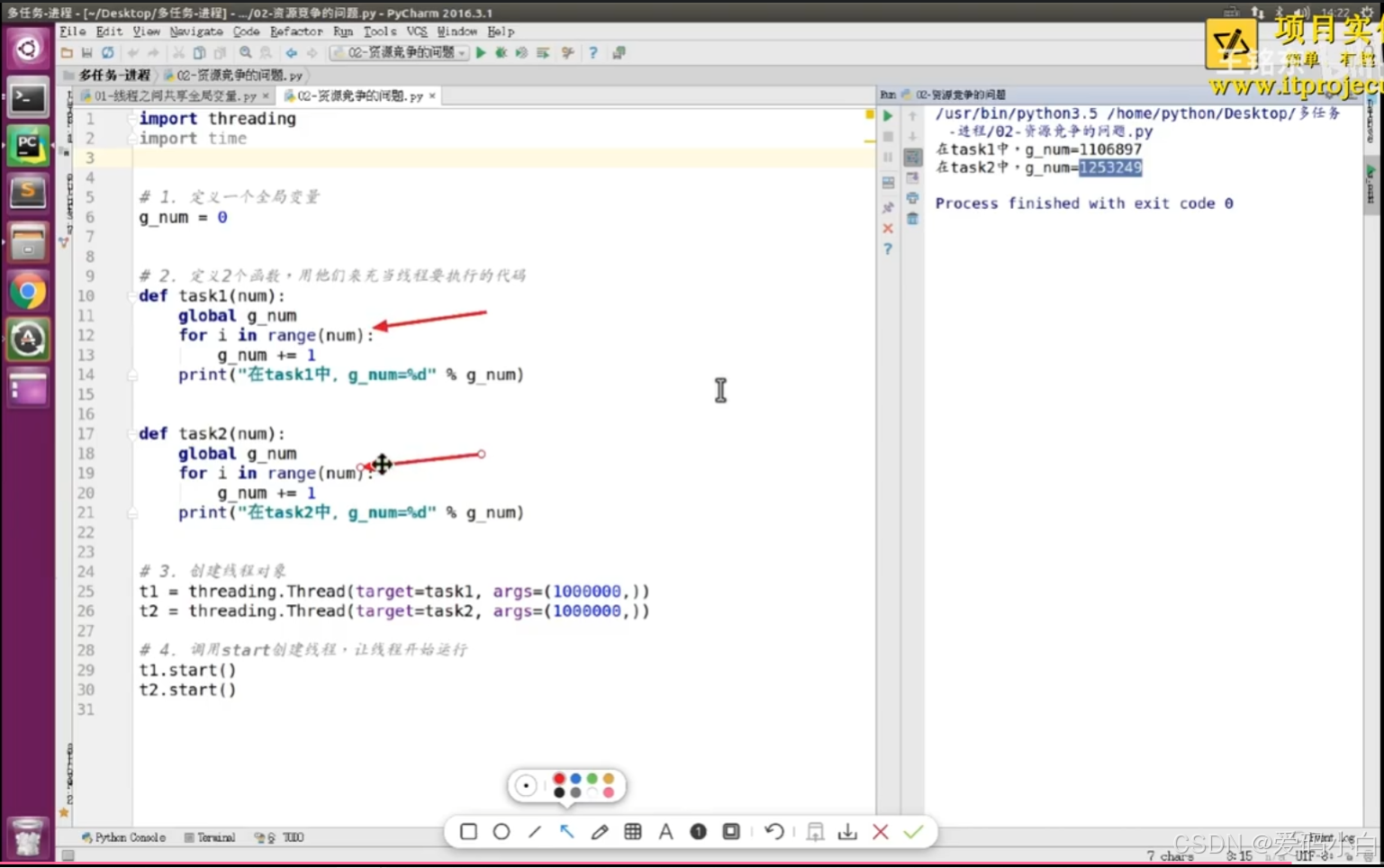
1.多线程开发可能遇到的问题
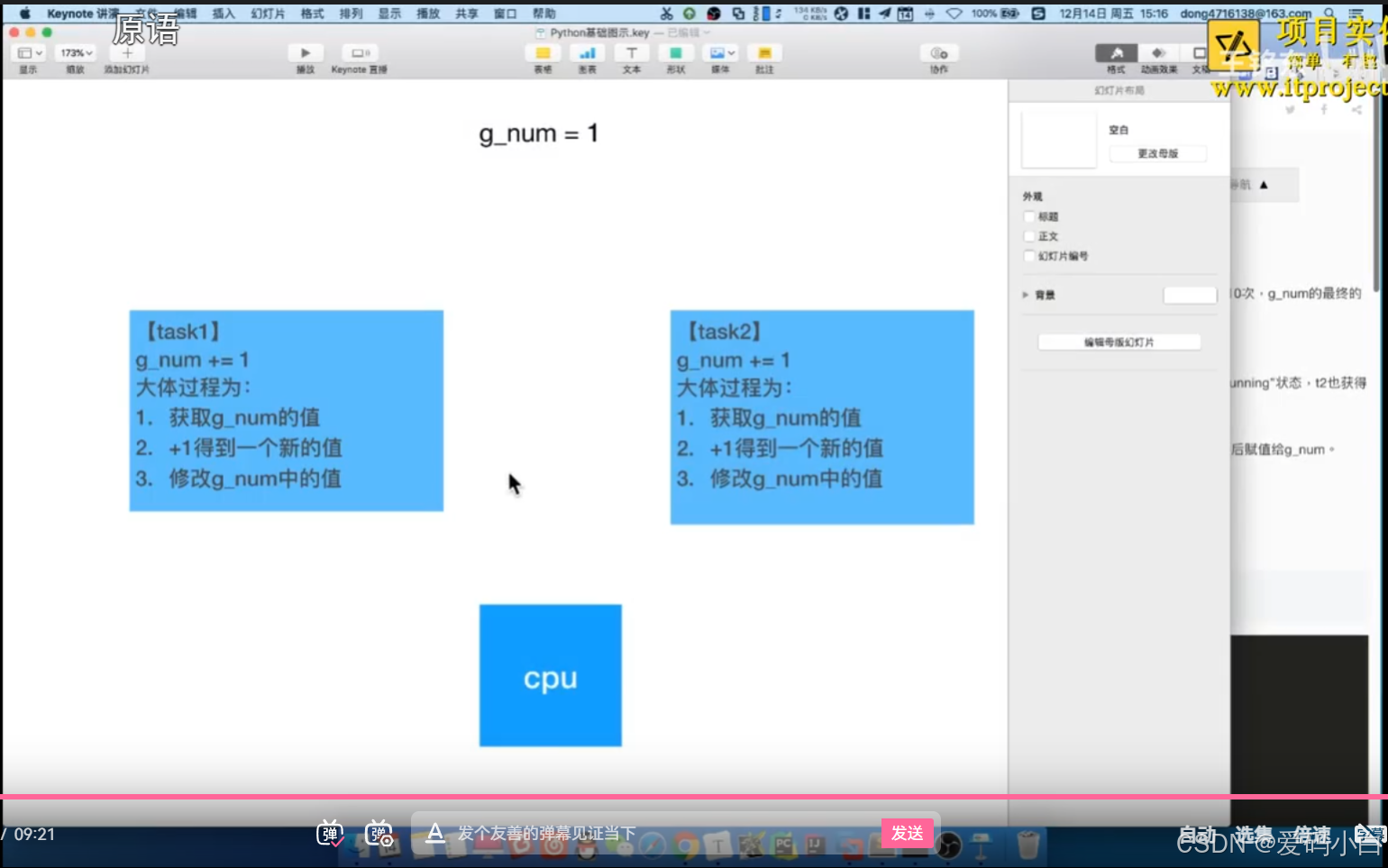
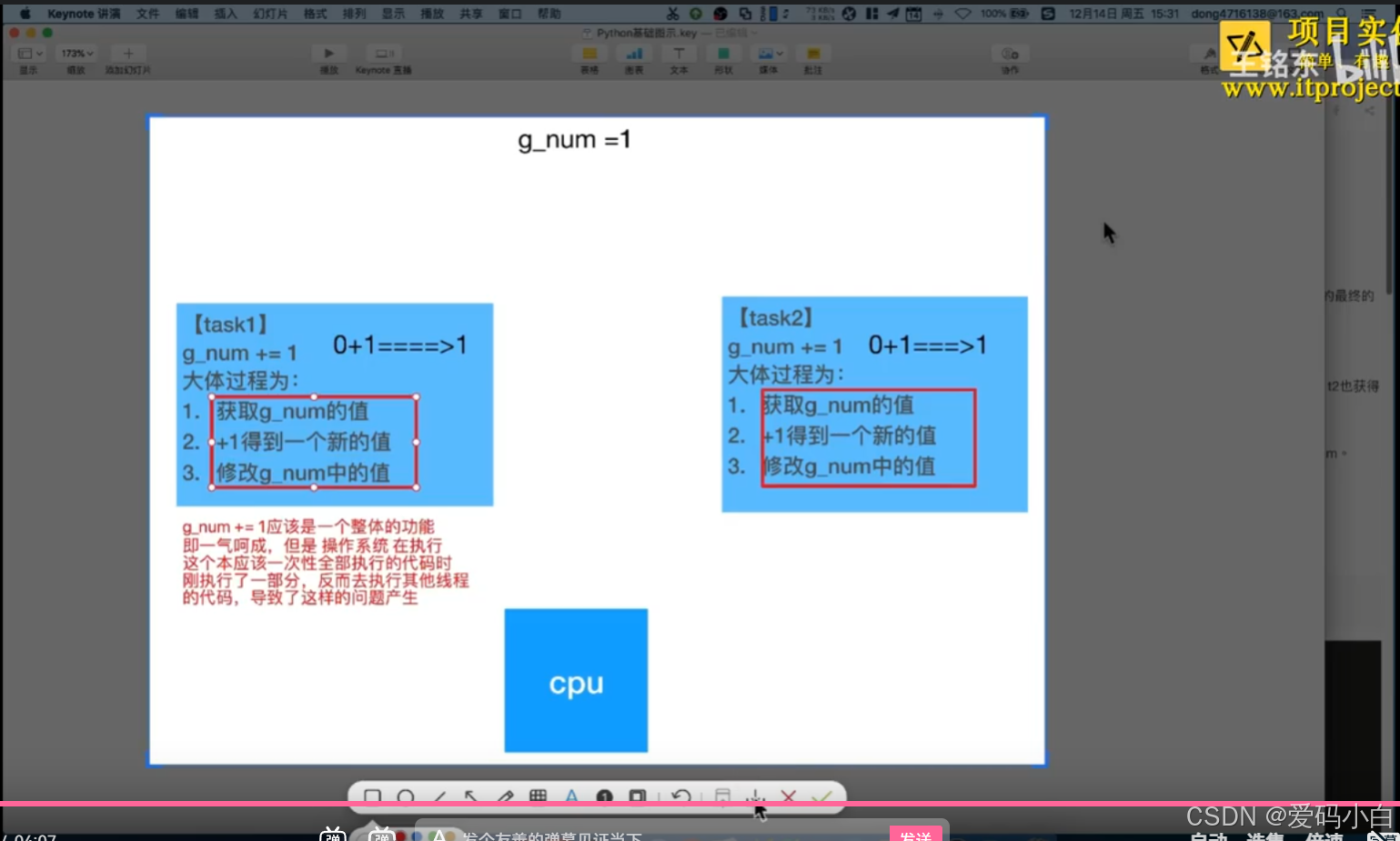
假设两个线程t1和t2都要对全局变量g_num(默认是0)进行加1运算,t1和t2都各对g_num加10次,g_num的最终的结果应该为20。
但是由于是多线程同时操作,有可能出现下面情况:
1.在g_num=0时,t1取得g_num=0。此时系统把t1调度为"sleeping”状态。把t2转换为"running”状态,2也获得g num=0。
2.然后t2对得到的值进行加1并赋给g_num,使得g_num=1。
3.然后系统又把t2调度为”sleeping”,把t1转为“running”·线程t1又把它之前得到的0加1后赋值给g_num。
4.这样导致虽然t1和t2都对g_num加1,但结果仍然是g_num=1。
2.验证问题1
自己写的代码:
import threading
import time
# 1.定义一个全局变量
g_num=0
#2.定义2个函数,用他们来充当线程要执行的代码
def task1(num):
global g_num
for i in range(num):
g_num+=1
print(f'在task1中g_num:{g_num}')
def task2(num):
global g_num
for i in range(num):
g_num+=1
print(f'在task1中g_num:{g_num}')
# 3.创建线程对象
t1=threading.Thread(target=task1,args=(1000000,))
t2=threading.Thread(target=task1,args=(1000000,))
# 4.调用start创建线程,让线程开始适行
t1.start()
t2.start()
04-分析出现资源竞争的问题 (听得懵逼)
05-分析出现资源竞争的问题2(听得懵逼)
06-互斥锁
互斥锁
1.为什么要用互斥锁
当多个线程几乎同时修改某一个共享数据的时候,需要进行同步控制线程同步能够保证多个线程安全访问竞争资源,最简单的同步机制是引入互斥锁。
2.互斥锁的作用
互斥锁为资源引入一个状态:锁定/非锁定
某个线程要更改共享致据时,先将其锁定,此时资源的状态为“锁定”,其他线程不能更改;直到该线程释放资源,将资源的状态变成”非锁定",其他的线程才能再次锁定该资源。互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的正确性。
 3. 使用互斥锁
3. 使用互斥锁
threading模块中定义了Lock类,可以方便的使用:
import threading
# 创建一个互斥锁
metex=threading.Lock()
# 上锁
metex.acquire()
# 解锁
metex.release()
注意:
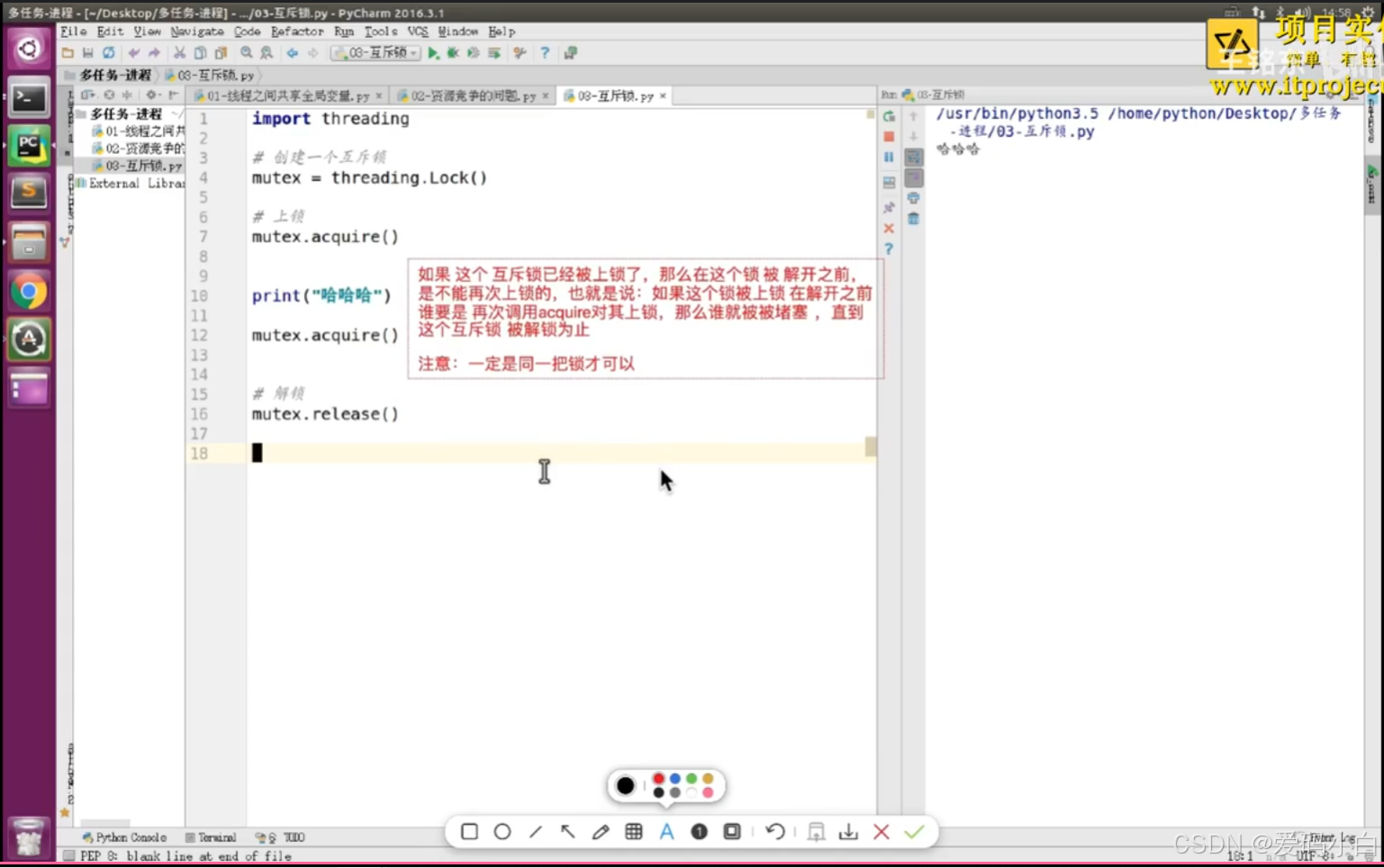
如果这个锁之前是没有上锁的,那么acquire不会堵塞(堵塞:理解为程序卡在这里等待某个条件满足)。
如果在调用acquire对这个锁上锁之前 它已经被 其他线程上了锁,那么此时acquire会堵塞,直到这个锁被解锁为止。
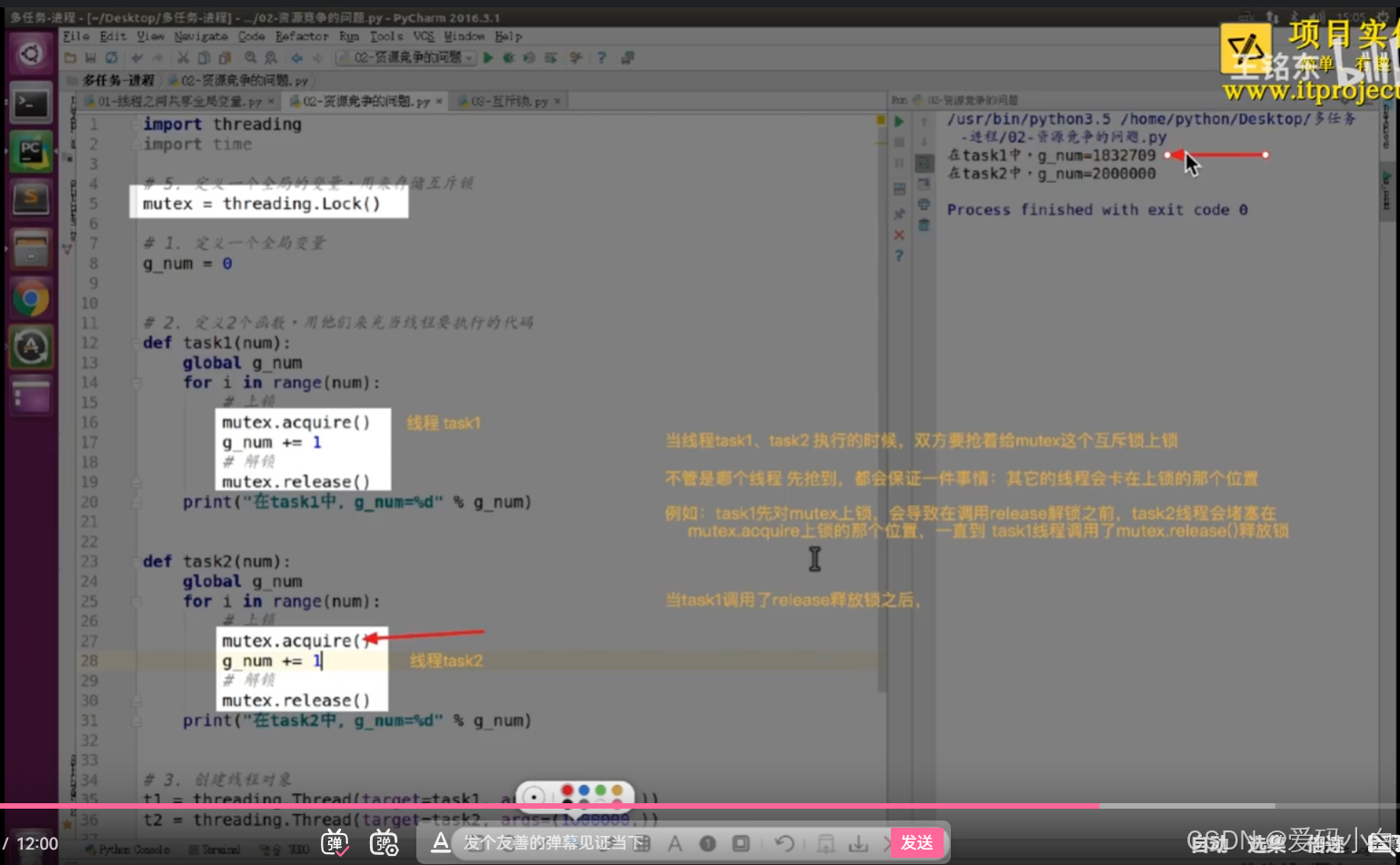
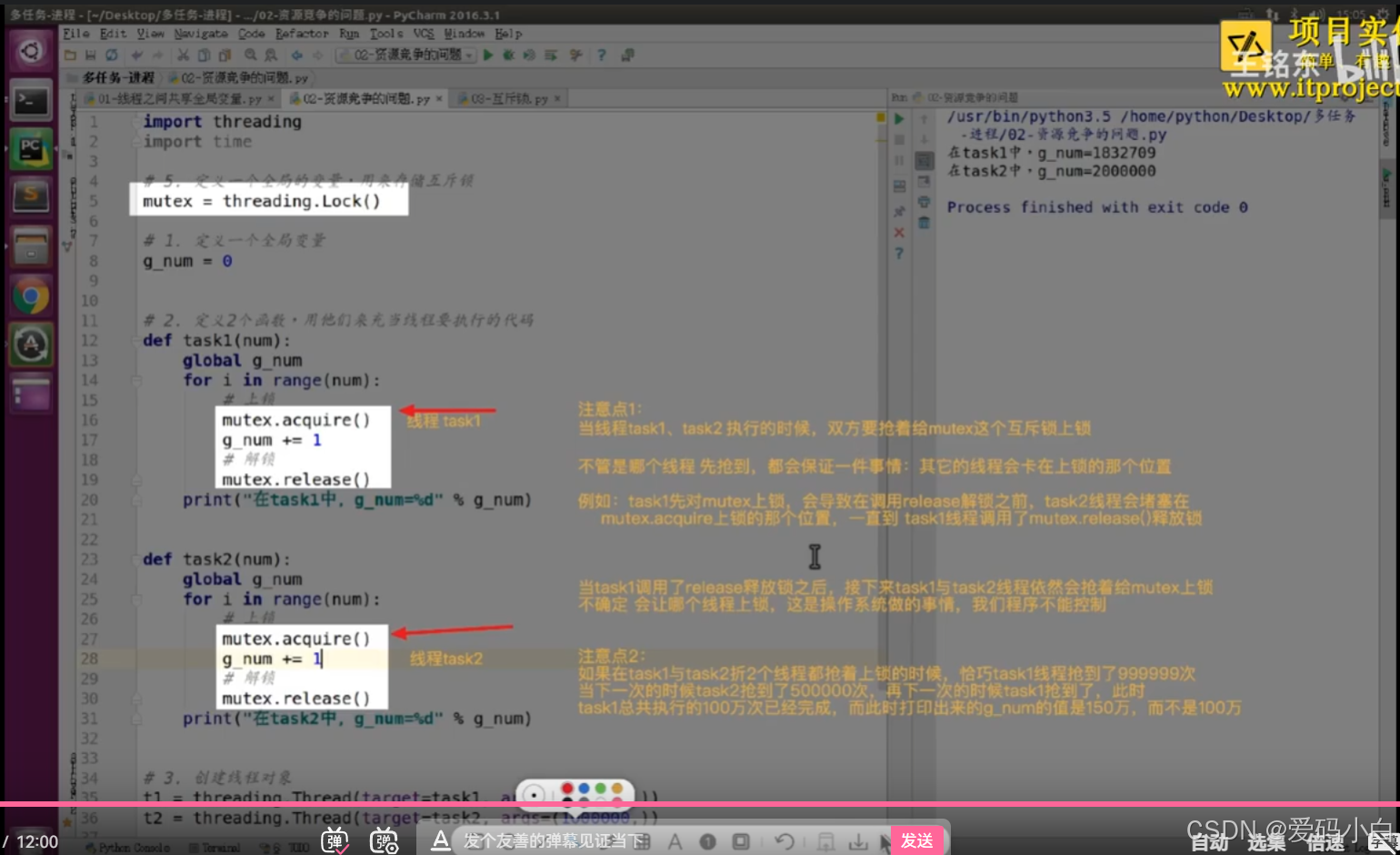
07-使用互斥锁解决:不是200万的问题
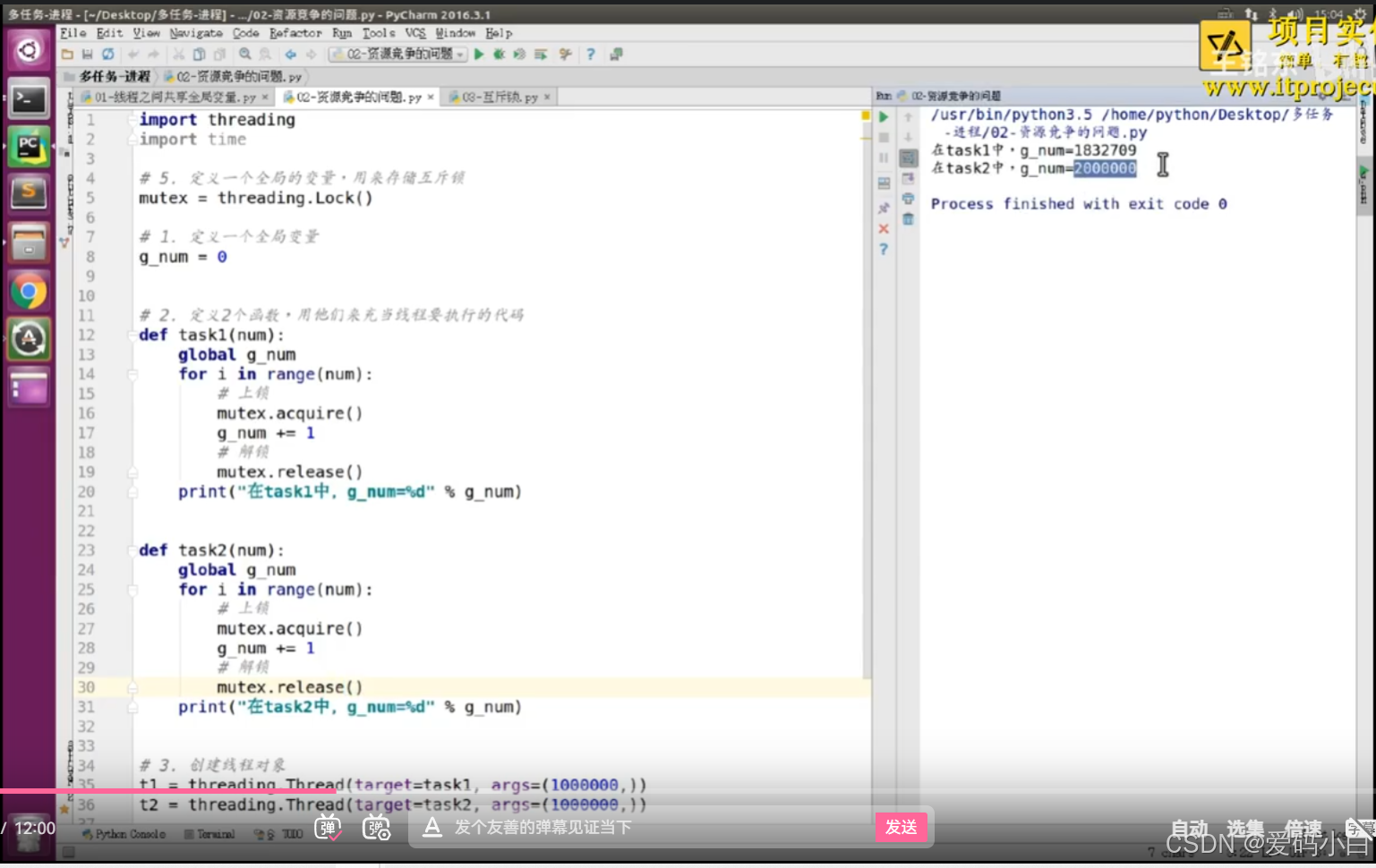
1.课堂练习代码
import threading
import time
metex=threading.Lock()
# 1.定义一个全局变量
g_num=0
#2.定义2个函数,用他们来充当线程要执行的代码
def task1(num):
global g_num
for i in range(num):
metex.acquire()
g_num+=1
metex.release()
print(f'在task1中g_num:{g_num}')
def task2(num):
global g_num
for i in range(num):
metex.acquire()
g_num+=1
metex.release()
print(f'在task1中g_num:{g_num}')
# 3.创建线程对象
t1=threading.Thread(target=task1,args=(1000000,))
t2=threading.Thread(target=task1,args=(1000000,))
# 4.调用start创建线程,让线程开始适行
t1.start()
t2.start()2.课堂截图
第四部分 进程
01-进程介绍
进程
1.程序
程序:例如xxx.exe是个程序,是一个静态的,是一堆代码的称呼。

2.进程
进程:一个程序运行起来后,代码+用到的资源 称之为进程,它是操作系统分配资源的基本单元。
 3.实现多任务
3.实现多任务
不仅可以使用线程实现多任务,使用进程依然可以实现多任务 。
在python中使用使用进程实现多任务的方式有3种:
1.创建Process对象(类似创建线程)
2.基础Process类,创建自己的对象,实现run翻番(类似创建线程)
3. 使用进程池
02-通过多进程实现多任务
创建进程方式1
回忆创建线程的方式
import threading
def task():
"""子线程要执行的代码"""
pass
t = threading.Thread(target=task)
t.start()
1.引入
multiprocessing模块是跨平台版本的多进程模块,提供了一个Process类来创建一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情。
2.示例代码
from multiprocessing import Process
import time
def test():
"""子进程单独执行的代码"""
while True:
print('---test---')
time.sleep(1)
if __name__ == '__main__':
p=Process(target=test)
p.start()
# 主进程单独执行的代码
while True:
print('---main---')
time.sleep(1)
小结
1.通过额外创建一个进程,可以实现多任务。
2.使用进程实现多任务的流程!
(1)创建一个Process对象,且在创建时通过target指定一个函数的引用。
(2)当调用start时,会真正的创建一个子进程。
3.进程PID(进程号)
from multiprocessing import Process
import os
import time
def run_proc():
"""子进程要执行的代码"""
print('子进程运行中,pid=%d...' % os.getpid()) # os.getpid获取当前进程的进程号
print('子进程将要结束...')
if __name__ == '__main__':
print('父进程pid: %d' % os.getpid()) # os.getpid获取当前进程的进程号
p = Process(target=run_proc)
p.start()
小结
1.每个进程都有1个数字来标记,这个数字称之为进程号
2.Linux系统中查看PID的命令是ps
3.(自己补充)获取进程ID号的方法是os中方法,而不是multiprocessing中的方法。
4.(自己补充)每次运行进程的ID号都不一样,应是系统分配的。
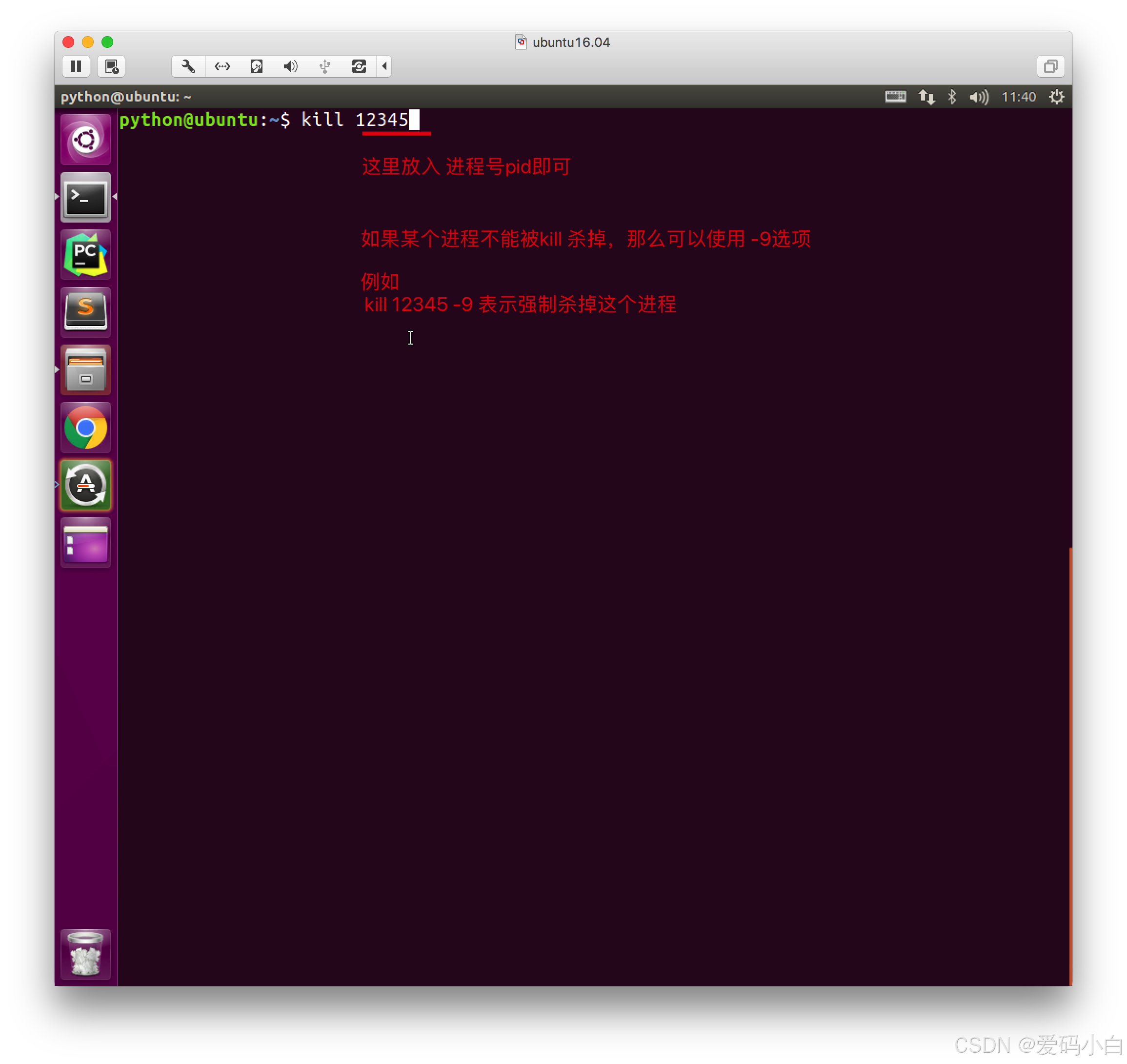
3.可以通过Linux命令kill pid的方式结束一个进程,如果进程结束了,就表示这个程序运行结束。
 4.Process创建的实例对象的常用方法
4.Process创建的实例对象的常用方法
下述方法中的p表示一个进程对象process 。示例代码均来自于豆包。
(1)p.start()
作用:启动子进程实例(创建子进程)
(2)p.is_alive()
语法:
p.is_alive() # 判断子进程是否还在活着
当使用 Python 的multiprocessing模块创建并启动进程后,is_alive()方法用于检
查该进程是否仍在运行。这在多进程编程中非常有用,例如,当你启动了多个工作进程来并
行处理任务,你可能需要检查某个进程是否已经完成任务或者意外终止。代码示例:
import multiprocessing
import time
def worker():
print("Worker process started")
time.sleep(5)
print("Worker process finished")
if __name__ == "__main__":
p = multiprocessing.Process(target = worker)
p.start()
print("Is the process alive right after start?", p.is_alive())
p.join()
print("Is the process alive after join?", p.is_alive())在这个示例中,首先创建了一个Process对象p,其目标函数是worker。然后启动这个进程p.start(),接着使用p.is_alive()检查进程是否在刚启动后是存活的,它会返回True。之后调用p.join()等待进程完成,再次检查p.is_alive(),此时会返回False,因为进程已经执行完毕。
(3)join(timeout=None)
作用:是否等待子进程执行结束,或等待多少秒。
在 Python 的多线程和多进程编程中,join()方法是一个重要的方法,它用于阻塞当前线程或进程,直到调用该方法的线程或进程执行完成。
这在需要协调多个线程或进程的执行顺序时非常有用,例如,当你希望主线程等待子线程完成后再继续执行后续操作,或者一个进程等待另一个进程结束后再进行下一步操作时。
语法:
p.join(timeout=None):
timeout是一个可选参数,用于指定等待的最长时间(以秒为单位)。
如果设置了timeout,join()方法将最多阻塞当前线程或进程timeout秒。示例代码:
import threading
import time
def worker():
time.sleep(5)
print("Worker thread finished")
if __name__ == "__main__":
t = threading.Thread(target=worker)
t.start()
print("Main thread is waiting for worker thread to finish with timeout")
t.join(3) # 最多等待 3 秒
print("Main thread continues after timeout")代码解释:
这里的t.join(3)会阻塞主线程最多 3 秒。如果线程t在 3 秒内完成,主线程会提前结束等待;如果 3 秒后线程t还未完成,主线程会继续执行后续代码,输出Main thread continues after timeout,而线程t会继续执行,最终输出Worker thread finished。
(4)terminate()
作用:不管任务是否完成,立即终止子进程
背景和用途:
当使用 Python 的multiprocessing模块创建并启动进程后,terminate()方法可用于强制终止该进程。这在某些情况下非常有用,例如,当进程陷入死循环或长时间无响应,或者根据某些条件需要提前终止进程时,可以使用terminate()方法来立即结束进程的执行。
import multiprocessing
import time
def worker():
while True:
print("正在运行Worker进行...")
time.sleep(1)
if __name__ == "__main__":
p = multiprocessing.Process(target=worker)
p.start()
print("启动进程:Worker")
time.sleep(3)
print("强制结束进程:Worker.")
p.terminate()
print("进程已经强制结束:Worker.")03-通过多进程实现多任务-总结
04-通过继承Process实现多进程
创建进程方式2
0.回忆线程创建的方式
import threading
class Task(threading.Thread):
def run(self):
"""子线程要执行的代码"""
pass
t = Task()
t.start()
1.示例代码
from multiprocessing import Process
import time
class MyNewProcess(Process):
def run(self):
while True:
print('---1---')
time.sleep(1)
if __name__=='__mian__':
p = MyNewProcess()
# 调用p.start()方法,p会先去父类中寻找start(),然后在Process的start方法中调用run方法
p.start()
while True:
print('---Main---')
time.sleep(1)
2.小结
1.此种创建多进程的流程
1.自定义一个类,继承Process类
2.实现run方法
3.通过自定义的类,创建实例对象
4.调用实例对象的start方法
2.对比1.自定义继承Process类的方式比 直接创建Process对象 要稍微复杂一些,但是可以用来实现更多较为复杂逻辑的功能。
3.建议:
1.如果想快速的实现一个进程,功能较为简单的话,可以直接创建Process的实例对象。
2.如果想实现一个功能较为完整、逻辑较为复杂的进程,可以自定义继承Process类来实现。
05-创建进程对象的时候传递参数
1.引入
为了在创建进程对象时,能够将不同的数据传递给进程,可以给Process类的init方法传递参数。
2.示例代码
from multiprocessing import Process
import os
from time import sleep
def run_proc(name, age, **kwargs):
for i in range(10):
print('子进程运行中,name= %s,age=%d ,pid=%d...' % (name, age, os.getpid()))
print(kwargs)
sleep(0.2)
if __name__=='__main__':
p = Process(target=run_proc, args=('test',18), kwargs={"m":20})
p.start()
sleep(1) # 1秒中之后,立即结束子进程
p.terminate()
p.join()
运行结果:
子进程运行中,name= test,age=18 ,pid=45097...
{'m': 20}
子进程运行中,name= test,age=18 ,pid=45097...
{'m': 20}
子进程运行中,name= test,age=18 ,pid=45097...
{'m': 20}
子进程运行中,name= test,age=18 ,pid=45097...
{'m': 20}
子进程运行中,name= test,age=18 ,pid=45097...
{'m': 20}
3.小结
1.调用Process类创建进程对象时
1.target指明 创建进程后,进程指定的代码是哪个函数。
2.args、kwargs用来给那个函数指明传递的实参
1. args:元组
2.kwargs:字典
06-进程不共享全局变量、进程VS线程
进程不共享全局变量
1.进程不共享全局变量
(1)线程共同全局变量,代码演示:
import threading
import time
nums = []
def task1():
for i in range(3):
nums.append(i)
print("task1 中 nums:", nums)
print("task1 即将结束")
def task2():
print("task2 中 nums:", nums)
print("task2 即将结束")
t1 = threading.Thread(target=task1)
t2 = threading.Thread(target=task2)
t1.start()
time.sleep(2)
t2.start()
(2)进程不同享全局变量
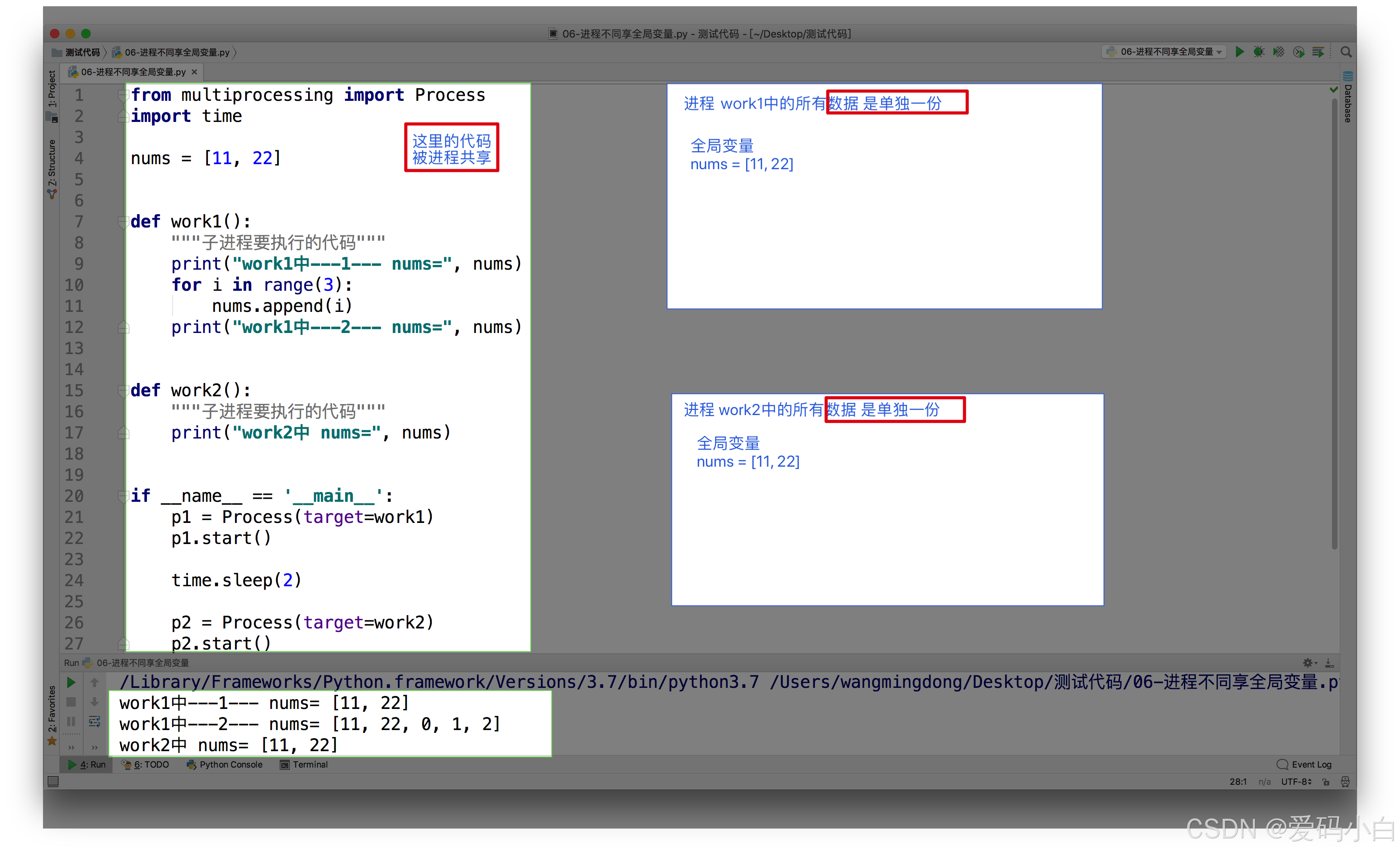
示例代码1(课件代码)
from multiprocessing import Process
import os
import time
nums = [11, 22]
def work1():
"""子进程要执行的代码"""
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
for i in range(3):
nums.append(i)
time.sleep(1)
print("in process1 pid=%d ,nums=%s" % (os.getpid(), nums))
def work2():
"""子进程要执行的代码"""
print("in process2 pid=%d ,nums=%s" % (os.getpid(), nums))
if __name__ == '__main__':
p1 = Process(target=work1)
p1.start()
time.sleep(2)
p2 = Process(target=work2)
p2.start()
运行结果:
示例代码2(老师课上演示)
import multiprocessing
import time
NUM=100
def task1():
global NUM
NUM=200
print(f'task1中NUM的值:{NUM}')
def task2():
print(f'task2中NUM的值:{NUM}')
if __name__=="__main__":
p1=multiprocessing.Process(target=task1)
p2=multiprocessing.Process(target=task2)
p1.start()
time.sleep(1)
p2.start()运行结果:
task1中NUM的值:200
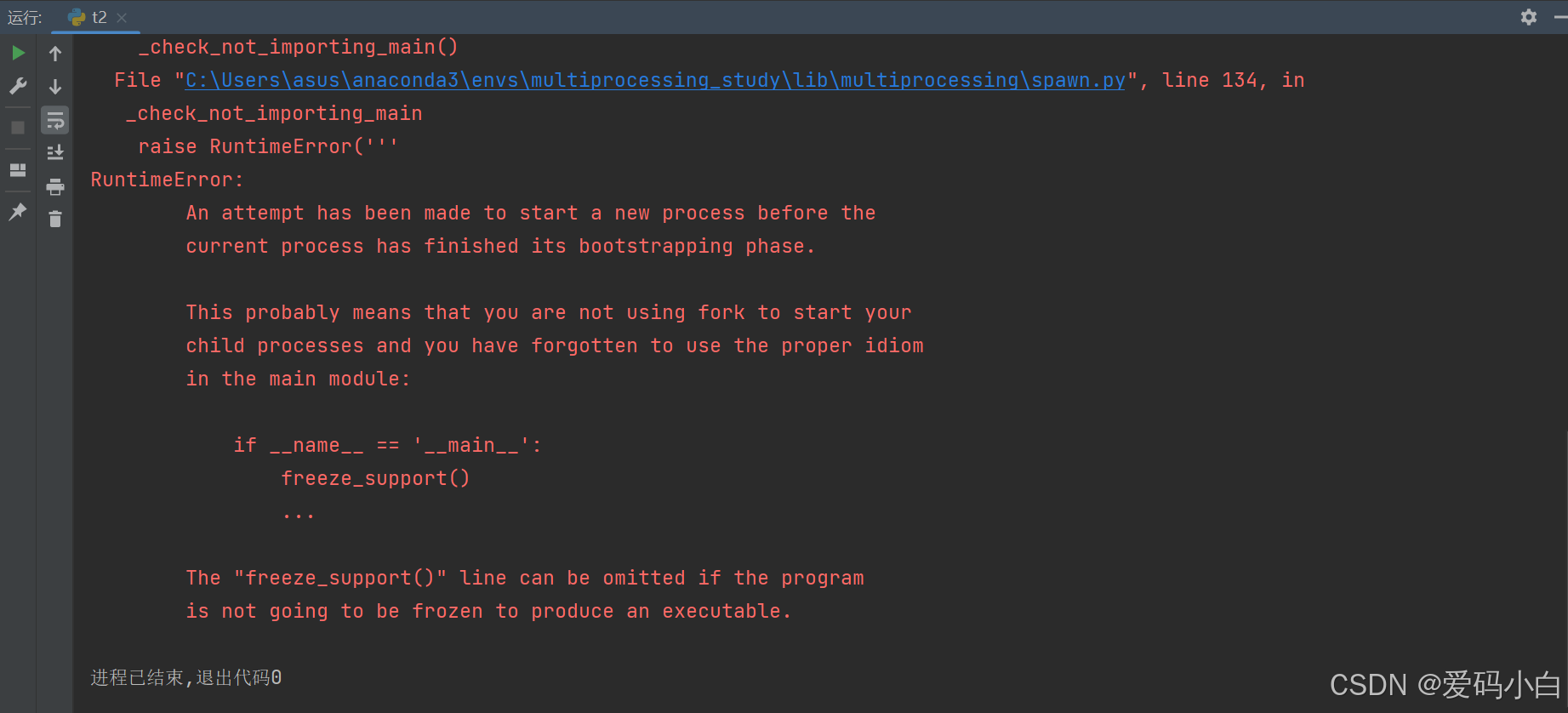
task2中NUM的值:100注意:
创建进程和启动进程必须放在if __name=="__main__" 语句中,否则会报错,报错信息如下图所示。而创建和启动线程则不需要。
示例代码3(自己结合本节课程线程共享全局变量改编而来):
import multiprocessing
import time
nums = []
def task1():
for i in range(3):
nums.append(i)
print("task1 中 nums:", nums)
print("task1 即将结束")
def task2():
print("task2 中 nums:", nums)
print("task2 即将结束")
if __name__=="__main__":
p1=multiprocessing.Process(target=task1)
p2=multiprocessing.Process(target=task2)
p1.start()
time.sleep(1)
p2.start()运行结果:
task1 中 nums: [0, 1, 2]
task1 即将结束
task2 中 nums: []
task2 即将结束
2.进程VS线程
(1)课堂截图
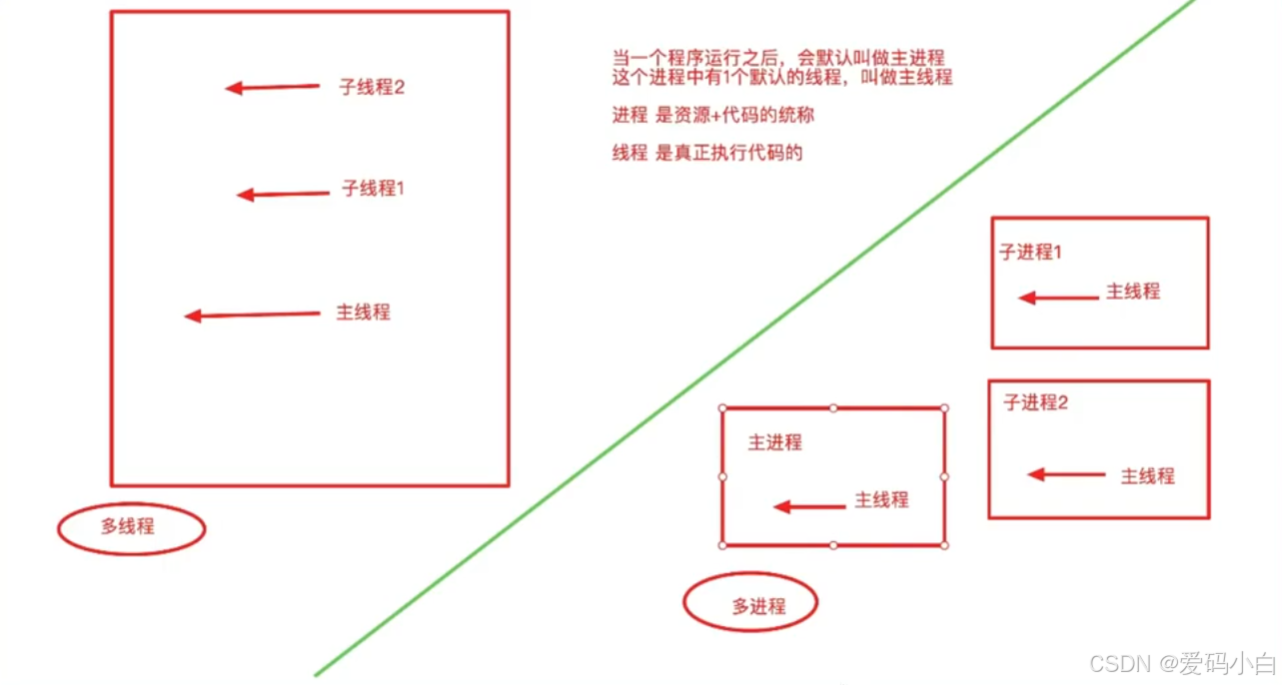
(2)老师的课堂小结
4.进程之间不共享全局变量
1、当创建一个子进程的时候,会复制父进程的很多东西(全局变量等)
2.子进程和主进程是单独的2个进程,不是一个
1.当一个进程结束的时候,不会对其他的进程产生影响
5.线程之间共享全局变量
1.所有的线程都在同一个进程中,这个进程是主进程
(3)扩展知识:进程和线程的区别
一、基本概念
进程: 进程是程序的一次执行过程,是系统进行资源分配和调度的一个独立单位。一个进程包含了程序代码、数据、堆、栈等资源,每个进程都有自己独立的内存空间,进程之间的数据不共享(除非使用特殊的进程间通信机制)。 进程可以看作是一个相对独立的应用程序实例,例如打开一个浏览器是一个进程,打开一个文本编辑器是另一个进程。
线程: 线程是进程中的一个执行流,是操作系统能够进行运算调度的最小单位。一个进程可以包含多个线程,这些线程共享进程的资源,包括代码、数据、堆等,但每个线程有自己的栈空间。 线程是轻量级的,创建和切换线程的开销比进程小得多,例如在一个浏览器进程中,可能有多个线程分别负责页面渲染、网络请求、用户交互等不同的任务。
二、资源使用
进程: 进程拥有独立的内存空间,包括代码段、数据段、堆等,进程之间的切换涉及到资源的重新分配和上下文切换,开销较大。 不同进程之间的数据隔离性好,一个进程的崩溃不会影响其他进程。
线程: 线程共享进程的资源,仅拥有自己的栈空间,因此线程间的切换开销相对较小。 但由于线程共享资源,需要通过同步机制(如互斥锁、信号量、条件变量等)来避免数据竞争和不一致性,例如多个线程同时操作一个共享变量时,可能会导致数据错误,需要加锁保护。
三、创建和销毁开销
进程: 创建一个新进程需要为其分配独立的资源,包括内存空间、文件描述符等,销毁进程也需要释放这些资源,开销较大。 操作系统需要为进程维护更多的信息,如进程表项、页表等,因此创建和销毁进程相对较慢。
线程: 线程的创建和销毁只需要分配和释放线程自身的栈空间,开销相对较小。 线程的创建和销毁速度比进程快很多,在需要频繁创建和销毁执行单元的场景下,使用线程更合适。
四、通信方式
进程: 进程间通信(IPC)通常使用管道、消息队列、信号量、共享内存、套接字等机制,因为进程间的内存空间是独立的,不能直接共享数据。 这些通信机制相对复杂,需要操作系统的支持,例如使用共享内存时,需要进行映射和同步操作。
线程: 线程之间可以直接访问共享的进程资源,通信相对简单,可以通过共享变量、队列等方式进行通信。 但如前所述,需要使用同步机制来确保数据的一致性,避免多个线程同时修改共享数据。
五、并发性和并行性
进程: 多个进程可以在多核处理器上实现真正的并行,因为它们拥有独立的资源,可以同时运行在不同的核心上。 不同进程之间的调度由操作系统决定,在多处理器系统中可以提高系统的吞吐量和性能。
线程: 在单核处理器上,多个线程通过时间片轮转等方式实现并发,看起来像是同时执行。 在多核处理器上,多个线程也可以实现并行,但可能会受到资源竞争和同步开销的影响,实际的性能提升可能不如多个进程。
六、适用场景
进程: 适合需要高度隔离、资源独立性高的场景,例如多个用户使用同一台服务器,每个用户的任务可以作为一个进程运行,相互之间不影响。 当需要在不同的环境中运行程序,或者程序可能会出现严重错误,不希望影响其他程序时,使用进程更合适。
线程: 适合需要大量共享数据、频繁通信的并发任务,如服务器的并发请求处理,使用多线程可以避免进程切换的高开销。 在性能要求较高、对资源消耗敏感的情况下,使用线程可以提高系统的响应速度和资源利用率。
07-进程间通信-Queue
1.引入
进程间是相互独立的,数据不共享,但有时需要致据共享,就需要请间通信(IPC)。
例如之前学习的网络编程udp、tcp,其实就是一种实现多进程间数据共京的方式,只是它通过套接字(socket)实现了不同电脑上的进程间通信如果在一台电脑上不同进程间通信,就可以用其它的方式实现(知道即可,不需要深入研究,研究操作系统时才需要深入研究它们)
1.文件。一个进程写入到文件,一个进程从文件中读取,但是这种方式效率很慢。
2 共享内存。
3. 管道。
等等
本小结我们用的队列来实现。
2.multiprocessing.Queue的使用
可以使用multiprocessing模块的Queue实现多进程之间的数据传递。
3.multiprocessing.Queue常用方法
(1)创建进程Queue对象
queue = multiprocessing.Queue(num)
参数num:参数值为正整数,如果参数值为空,则表示创建的队列可以放入的数据无数量限制。
如果参数num值为一个正整数,则表示队列中可以存放的数据最多为num个。(2) queue.full()
queue.full()
# 作用判断队列是否已满。
# 返回值,如果队列已满,返回值为True,否则为False(3)queue.empty()
queue.empty()
# 作用判断队列是否空。
# 返回值,如果队列为空,返回值为True,否则为False(4) queue.qsize()
queue.qsize()
# 作用:获取队列中数据的个数。
# 返回:返回一个int类型数字,表示队列中的数据的个数。(5) queue.put(data,timeout)
queue.put(data,timeout)
# 参数data:存入队列的数据,可以为任意类型。
# 参数timeout:如果队列中数据已满,存入数据等待的时间秒数。
如果不传入此参数,队列满时,存入数据时,程序会一直处于阻塞状态。
如果传入此参数一个正整数,队列满时,存入数据时,程序会等待timeout秒,
如果超时,则程序会报错,报错原因提示队列已满。
(6) queue.put_nowait(data)
queue.put_nowait(data)
# 参数data:表示要传入队列的数据,支持传入任意数据类型。
# 作用:要求传入数据时不需等待,如果队列中数据已满,则使用此方法传入时立即
报错。报错原因提示队列已满。(7) queue.get(block,timeout)
queue.get(block,timeout)
# 参数block:参数值为布尔值,如果传入True,则获取数据时,如果队列为空,则堵塞,传入False
不堵塞,其他方法中如果有block参数则用法同。
# 参数timeout:最多等待timeout秒内从队列中获取一个数据。如果timeout秒后队列仍为空,则报错。
报错原因提示队列为空。(8)queue.get_nowait()
queue.get_nowait()
# 返回值:返回一个数据。
# 作用:使用此方法,需要马从队列队列中获取数据,如果队列中数据为空,则运行时会报错。
报错原因提示队列为空。4.示例代码
代码(参考老师讲义编写,不完全一样,仅为了演示类方法用)1:
import multiprocessing
queue = multiprocessing.Queue(3)
# print(queue.get())
print(queue.empty())
# 存入数据
queue.put('消息1')
print(queue.get())
queue.put('消息2')
print(queue.qsize())
# 判断队列数据是否已满
print(queue.full())
queue.put('消息3')
print(queue.full())
#
# queue.put('消息4',timeout=2)
print(queue.qsize())
# queue.put_nowait('x')代码(课堂演示)2:
import random
from multiprocessing import Queue,Process
import time
# 写数据进程执行的代码
def task1(queue):
for value in ["A","B","C"]:
print(f"向队列queue中添加数据{value}")
queue.put(value)
time.sleep(random.random())
# 读取数据进程执行的代码
def task2(queue):
while True:
if not queue.empty():
value=queue.get()
print(f"从队列queue中获取数据:{value}")
time.sleep(random.random())
else:
break
if __name__=="__main__":
# 父进程创建queue并传递给各个子进程
queue=Queue()
write_p=Process(target=task1,args=(queue,))
read_p=Process(target=task2,args=(queue,))
# 启动写入子进程
write_p.start()
# 启动读取子进程
read_p.start()5.读代码的技巧
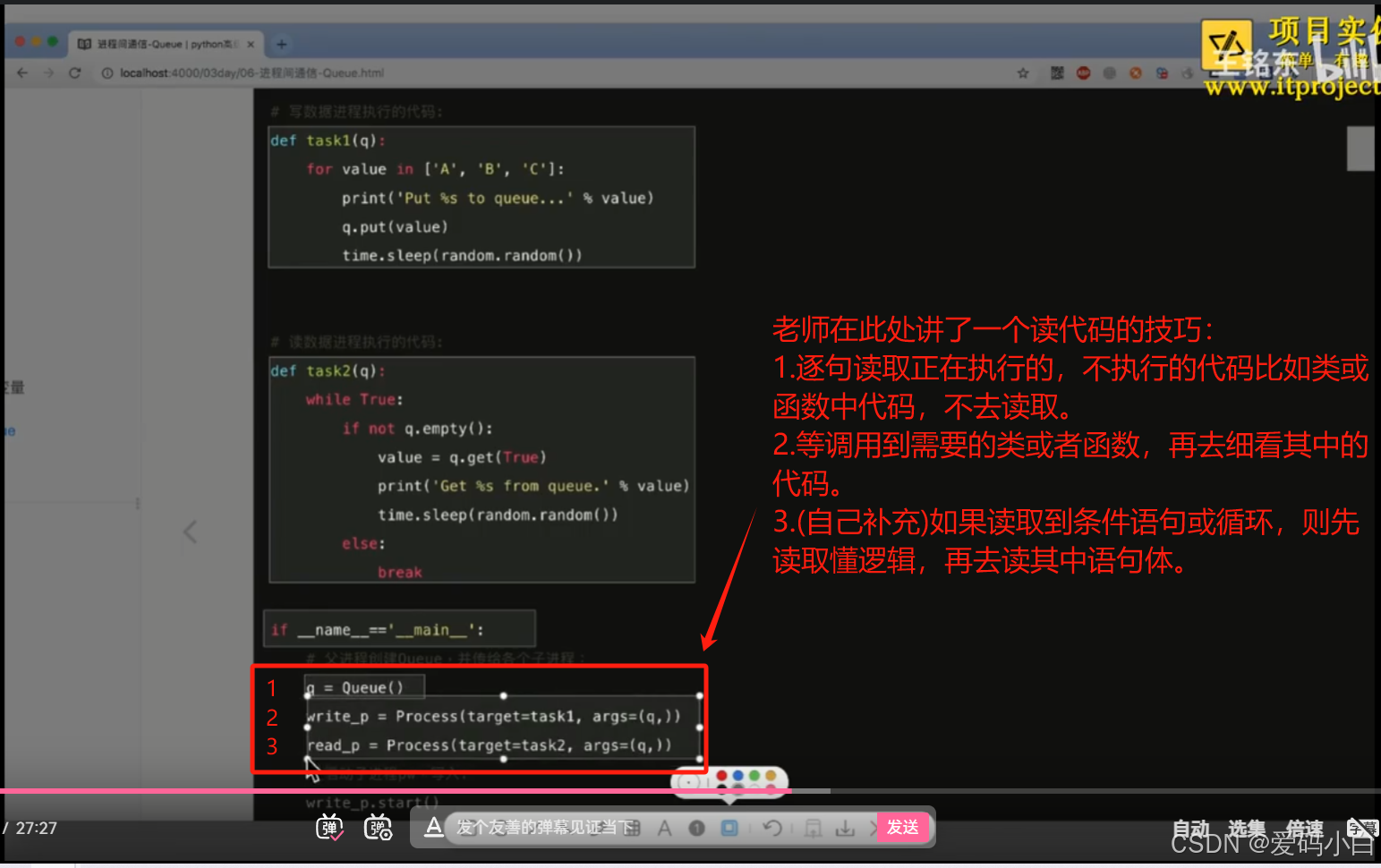
08-通过Queue完成进程间通信
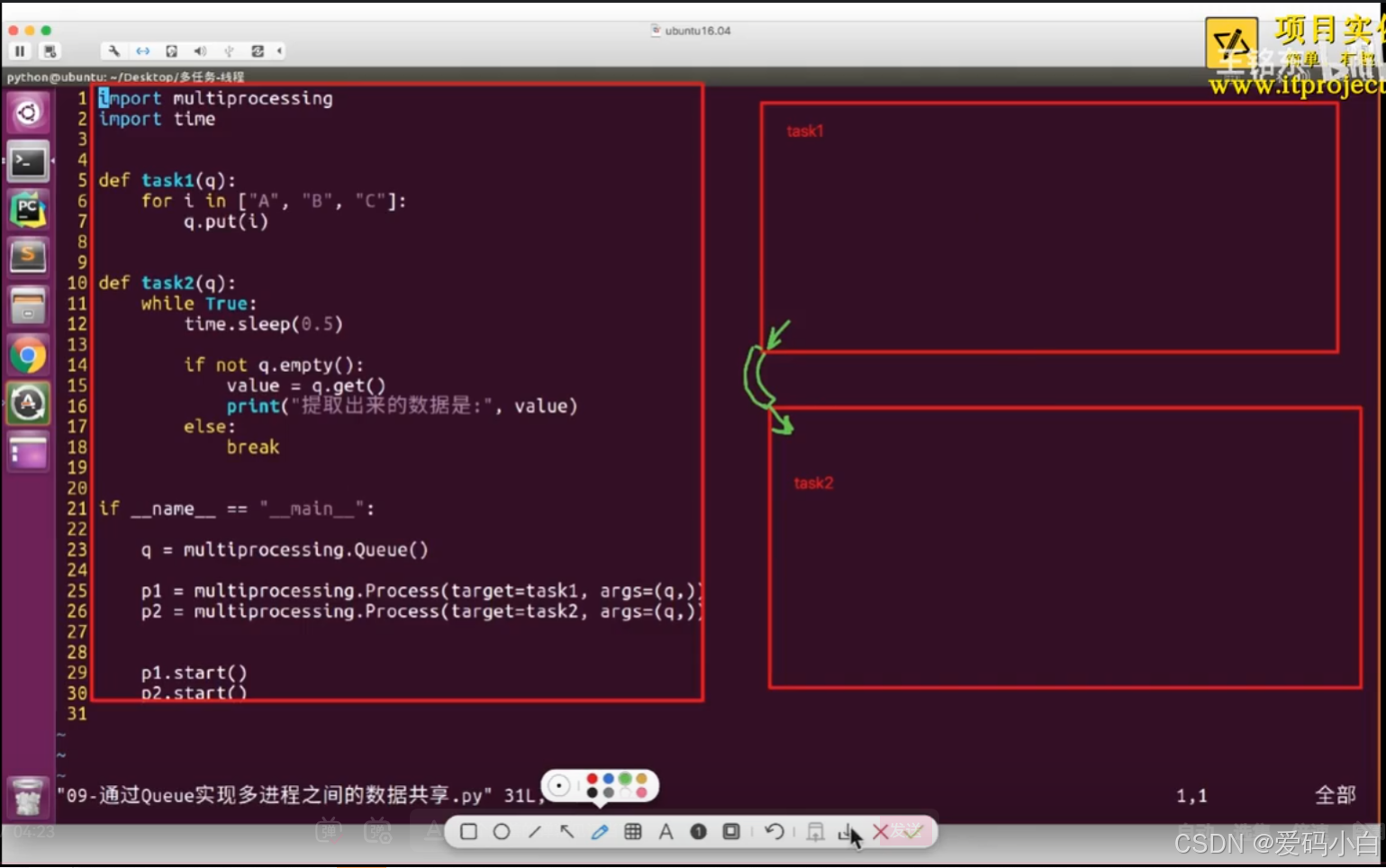
09-进程与线程的对比1
10-进程与线程的对比2
第五部分 线程池和进程池
该部分笔记:23-7 进程池_哔哩哔哩_bilibili
01-创建线程池
1.代码演示
(1)普通创建
import time
from concurrent.futures import ThreadPoolExecutor
def task(video_url,num):
print("开始执行任务",video_url,num)
time.sleep(1)
url_list=[f"www.xxx_{i}.com" for i in range(300)]
pool=ThreadPoolExecutor(10)
for url in url_list:
pool.submit(task,url,2)
pool.shutdown(True) # 有点类似线程中的join作用
print('end')(2)with创建
来自在豆包查资料时得到的知识点
import time
from concurrent.futures import ThreadPoolExecutor
def task(video_url,num):
print("开始执行任务",video_url,num)
time.sleep(1)
url_list=[f"www.xxx_{i}.com" for i in range(300)]
with ThreadPoolExecutor(max_workers=10) as pool:
for url in url_list:
pool.submit(task,url,2)
print('end')2.方法解析
(1)pool.submit(task,url,2) 添加线程(更详细讲解见下一节)
pool.submit(task,url,2)
#参数用法:
函数名称放置在第一个参数位置。
函数的参数按位置,依次放置在函数名称后面,用逗号间隔开。
# 作用:向线程池中提交线程,也可以理解为向线程池中添加线程(2)pool.shutdown(wait) 关闭线程
pool.shutdown(wait)
# 作用:关闭线程池
# 参数wait:当 wait=True 时,pool.shutdown() 会阻塞,直到所有已提交的任务
都完成。进程池中所有任务都执行完成后,代码才会向下执行。
02- submit用法
pool.submit() 是 ThreadPoolExecutor 对象的一个重要方法,用于向线程池提交任务以供执行。
1.用法
具体用法可以参阅下面的示例代码。
# 方法的作用:向线程池提交任务,并将任务函数的参数传递给 submit 方法
future = pool.submit(task_function, value1, value2)
# pool.submit() 方法会将 task_function 函数提交到线程池中,同时将
value1 和 value2 作为参数传递给该函数。
#该方法会返回一个 Future 对象,用于表示异步操作的结果,可以通过这个
对象来获取任务的执行状态和结果。2.示例代码
结合豆包搜索出来的相关知识编写而来的代码。
import random
import time
from concurrent.futures import ThreadPoolExecutor
def task(code,num1,num2):
# print(f"学号:{code},语文:{num1}分,数学:{num2}分")
time.sleep(1)
return f"{code}:{num1+num2}"
def sum(res):
print(res.result())
with ThreadPoolExecutor(10) as pool:
for i in range(300,400):
code=f"N000{i}"
num1=random.randint(60,100)
num2=random.randint(60,100)
future=pool.submit(task,code,num1,num2) # 返回值是concurrent.futures中的Future对象
future.add_done_callback(sum) # 将 Future对象future作为参数值传递给sum函数,并调用sum函数
print(type(future))
3.Future
当使用 Python 的 concurrent.futures 模块中的 ThreadPoolExecutor 或 ProcessPoolExecutor 中的 pool.submit() 方法提交任务时,会返回一个 Future 对象。这个 Future 对象代表了一个延迟的计算结果,它提供了一种方式来管理和操作这个尚未完成的任务。
Future 对象的主要特性和方法:
(1)表示异步操作: Future 对象表示一个正在进行或即将进行的任务,该任务在另一个线程或进程中执行,它允许你对任务的结果进行操作,而无需等待任务完成。
(2) 主要方法和属性:
1)done(): 该方法用于检查任务是否已经完成。返回值是布尔值。
from concurrent.futures import Future
future=Future()
result=future.done()
print(result)
if future.done():
print("任务已完成")
else:
print("任务仍在执行中")2)result(timeout=None): 该方法用于获取任务的结果。 如果任务已完成,它会立即返回结果;如果任务未完成,它会阻塞当前线程,直到任务完成或超时(如果设置了超时)。
from concurrent.futures import Future
future=Future()
try:
result = future.result(timeout=5) # 阻塞直到任务完成
print(f"任务结果是: {result}")
except TimeoutError:
print("任务超时")
except Exception as e:
print(f"任务执行出错: {e}") 设置 timeout 参数来指定等待的时间(以秒为单位),例如 future.result(timeout=5) 表示等待 5 秒,如果 5 秒内任务未完成,会抛出 TimeoutError。 如果不设置timeout参数,则会一直等待,即程序阻塞。
3) add_done_callback(fn): 该方法允许你添加一个回调函数 fn,当任务完成时,会调用这个回调函数。回调函数将 Future 对象作为其唯一的参数(传给调用函数fn)。下面的代码无任何运行结果,仅用于用法演示。
from concurrent.futures import Future
future=Future()
def callback(future):
try:
result = future.result()
print(f"任务完成,结果是: {result}")
except Exception as e:
print(f"任务出错: {e}")
future.add_done_callback(callback)回调函数可以用来执行一些后续操作,比如处理结果、更新状态等,并且可以添加多个回调函数,它们将按照添加的顺序依次执行。
4.参考资料
(1)python线程池pool.submit()的用法
pool.submit() 的用法:
在 Python 的 concurrent.futures 模块中,ThreadPoolExecutor 类提供了线程池的实现,而 pool.submit() 是 ThreadPoolExecutor 对象的一个重要方法,用于向线程池提交任务以供执行。以下是其详细的使用方法:
步骤:
-
导入所需模块:
收起
python
from concurrent.futures import ThreadPoolExecutor -
创建线程池对象:
收起
python
# 创建一个具有特定数量工作线程的线程池,max_workers 参数指定线程池中的线程数量 pool = ThreadPoolExecutor(max_workers=5)这里的
max_workers可以根据实际需求进行调整,它表示线程池中的最大线程数量。 -
定义任务函数:
任务函数是你想要在线程池中执行的函数,可以根据需要接收任意数量的参数。收起
python
def task_function(arg1, arg2): # 这里是任务函数的具体逻辑 print(f"Task is processing with arguments: {arg1}, {arg2}") # 可以进行一些计算、文件操作、网络请求等操作 return result # 可以根据需要返回结果 -
使用
pool.submit()提交任务:收起
python
# 向线程池提交任务,并将任务函数的参数传递给 submit 方法 future = pool.submit(task_function, value1, value2)pool.submit()方法会将task_function函数提交到线程池中,同时将value1和value2作为参数传递给该函数。- 该方法会返回一个
Future对象,用于表示异步操作的结果,可以通过这个对象来获取任务的执行状态和结果。
- 该方法会返回一个
使用 Future 对象:
- 检查任务是否完成:
收起
python
if future.done(): print("Task is completed.") else: print("Task is still running.") - 等待任务完成并获取结果:
收起
python
如果你不想让try: result = future.result() # 会阻塞当前线程,直到任务完成 print(f"Task result: {result}") except Exception as e: print(f"An error occurred: {e}")result()方法无限期阻塞,可以设置超时时间:收起
python
try: result = future.result(timeout=5) # 等待 5 秒 print(f"Task result: {result}") except TimeoutError: print("Task timed out.") except Exception as e: print(f"An error occurred: {e}") - 添加回调函数:
可以添加一个回调函数,当任务完成时自动调用。回调函数接收Future对象作为参数。收起
python
def callback(future): try: result = future.result() print(f"Callback received result: {result}") except Exception as e: print(f"Callback encountered an error: {e}") future.add_done_callback(callback)
完整示例代码:
收起
python
from concurrent.futures import ThreadPoolExecutor
def task_function(arg1, arg2):
print(f"Task is processing with arguments: {arg1}, {arg2}")
# 模拟任务执行时间
import time
time.sleep(2)
return arg1 + arg2
def callback(future):
try:
result = future.result()
print(f"Callback received result: {result}")
except Exception as e:
print(f"Callback encountered an error: {e}")
if __name__ == "__main__":
# 创建线程池
pool = ThreadPoolExecutor(max_workers=3)
# 提交任务
future = pool.submit(task_function, 10, 20)
# 检查任务是否完成
if future.done():
print("Task is completed.")
else:
print("Task is still running.")
# 添加回调函数
future.add_done_callback(callback)
# 等待任务完成
try:
result = future.result()
print(f"Task result: {result}")
except Exception as e:
print(f"An error occurred: {e}")
代码解释:
- 首先,导入
ThreadPoolExecutor类。 - 定义
task_function函数,它接收两个参数并打印它们,模拟任务执行时间后返回它们的和。 - 定义
callback函数,它尝试从Future对象获取结果并打印,处理可能出现的异常。 - 在
if __name__ == "__main__":部分:- 创建一个最大线程数为 3 的线程池。
- 向线程池提交
task_function任务,并传递参数 10 和 20。 - 检查任务是否完成。
- 添加回调函数。
- 等待任务完成并打印结果,处理异常。
使用 pool.submit() 的优势:
- 提高程序性能:对于可以并行处理的任务,使用线程池可以避免频繁创建和销毁线程的开销。
- 资源管理:通过线程池可以更好地管理线程资源,避免创建过多线程导致资源耗尽。
- 方便的结果处理:使用
Future对象可以方便地处理任务的结果,包括等待结果、添加回调函数等。
使用 pool.submit() 可以方便地将任务提交到线程池中,同时通过 Future 对象对任务的执行结果进行管理和处理,是 Python 中实现并发编程的一种有效方式。根据任务的特性和资源情况,可以调整线程池的大小,以达到最佳性能。
(2)python线程池pool.submit()的返回的Future对象
pool.submit() 返回的 Future 对象解释:
当使用 Python 的 concurrent.futures 模块中的 ThreadPoolExecutor 或 ProcessPoolExecutor 中的 pool.submit() 方法提交任务时,会返回一个 Future 对象。这个 Future 对象代表了一个延迟的计算结果,它提供了一种方式来管理和操作这个尚未完成的任务。
Future 对象的主要特性和方法:
-
表示异步操作:
Future对象表示一个正在进行或即将进行的任务,该任务在另一个线程或进程中执行,它允许你对任务的结果进行操作,而无需等待任务完成。
-
主要方法和属性:
-
done():- 该方法用于检查任务是否已经完成。
收起
python
if future.done(): print("任务已完成") else: print("任务仍在执行中")调用
done()会立即返回结果,不会阻塞当前线程。 -
result(timeout=None):- 该方法用于获取任务的结果。
- 如果任务已完成,它会立即返回结果;如果任务未完成,它会阻塞当前线程,直到任务完成或超时(如果设置了超时)。
收起
python
try: result = future.result() # 阻塞直到任务完成 print(f"任务结果是: {result}") except TimeoutError: print("任务超时") except Exception as e: print(f"任务执行出错: {e}")可以通过设置
timeout参数来指定等待的时间(以秒为单位),例如future.result(timeout=5)表示等待 5 秒,如果 5 秒内任务未完成,会抛出TimeoutError。 -
add_done_callback(fn):- 该方法允许你添加一个回调函数
fn,当任务完成时,会调用这个回调函数。回调函数将Future对象作为其唯一的参数。
收起
python
def callback(future): try: result = future.result() print(f"任务完成,结果是: {result}") except Exception as e: print(f"任务出错: {e}") future.add_done_callback(callback)回调函数可以用来执行一些后续操作,比如处理结果、更新状态等,并且可以添加多个回调函数,它们将按照添加的顺序依次执行。
- 该方法允许你添加一个回调函数
-
示例代码:
收起
python
from concurrent.futures import ThreadPoolExecutor
def task(arg):
import time
print(f"开始执行任务,参数是 {arg}")
time.sleep(2) # 模拟任务执行时间
return arg * 2
if __name__ == "__main__":
pool = ThreadPoolExecutor(max_workers=3)
future = pool.submit(task, 5) # 提交任务,返回 Future 对象
# 检查任务是否完成
if future.done():
print("任务已完成")
else:
print("任务未完成")
# 添加回调函数
future.add_done_callback(lambda f: print(f"回调函数收到的结果: {f.result()}"))
# 等待任务完成
try:
result = future.result()
print(f"最终结果是: {result}")
except Exception as e:
print(f"执行任务出错: {e}")
代码解释:
- 首先,从
concurrent.futures模块导入ThreadPoolExecutor。 - 定义了一个
task函数,它接收一个参数,模拟任务执行时间为 2 秒,然后返回参数的两倍。 - 在
if __name__ == "__main__部分:- 创建一个最大工作线程数为 3 的线程池。
- 调用
pool.submit(task, 5)提交任务并得到一个Future对象。 - 使用
done()方法检查任务是否完成。 - 使用
add_done_callback()方法添加一个回调函数,它将在任务完成时打印结果。 - 使用
result()方法等待任务完成并获取结果,同时处理可能的异常。
Future 对象的重要性:
- 非阻塞操作:允许你在等待任务完成的同时继续执行其他操作,通过使用回调函数或在适当的时候调用
result()方法,可以避免阻塞主线程,提高程序的并发性能。 - 结果管理:提供了一种统一的方式来管理任务的结果,无论任务是否已经完成,都可以方便地获取结果或处理异常。
- 异步编程的基础:在 Python 的并发编程中,
Future对象是实现异步操作的基础,为更复杂的并发编程模式提供了基础,例如与async/await语法的结合,或者在更高级的并发库中使用。
通过使用 Future 对象,可以有效地管理线程池或进程池中的任务,在任务完成时进行相应的操作,并确保资源的合理利用和程序的并发性能。
03 进程池
04 参考资料:王铭东老师进程池的讲解
01-进程池的引入
1.引入
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满那么就会创建一个新的进程用来执行该请求:但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
2.示例代码
from multiprocessing import Pool
import os
import random
import time
def worker(num):
for i in range(5):
print('===pid=%d==num=%d='%(os.getpid(),num))
time.sleep(1)
# 3表示进程池中最多有三个进程一起执行
pool=Pool(3)
for i in range(10):
print('---%d---'%i)
# 向进程中添加任务
# 注意:如果添加的任务数量超过了进程池中进程的个数的话,那么就不会接着往进程池中添加,
# 如果还没有执行的话,他会等待前面的进程结束,然后在往
# 进程池中添加新进程
pool.apply_async(worker,(i,))
pool.close() # 关闭进程池
pool.join() # 主进程在这里等待,只有子进程全部结束之后,在会开启主线程
3.常用函数解析
apply_async(func[,args[,kwds]]):1使用非阻塞方式调用func(并行执行,堵塞方式必须等待上一个进程退出才能执行下一个进程),args为传递给func的参数列表,kwds为传递给func的关键字参数列表。
close():关闭Pool,使其不再接受新的任务。
terminate():不管任务是否完成,立即终止。
join():主进程阻塞,等待子进程的退出,必须在close或terminate之后使用。
02-使用进程池的过程讲解
03-使用进程池的过程讲解2
04-join的作用
05-进程池间的进程通信
进程池中的Queue
如果要使用Pool创建进程,就需要使用multiprocessing.Manager()中的Queue(),而不是
multiprocessing.Queue(),否则会得到一条如下的错误信息:
RuntimeError: Queue objects should only be shared between processes throughinheritance.
下面的实例演示了进程池中的进程如何通信:
# -*- coding:utf-8 -*-
# 修改import中的Queue为Manager
from multiprocessing import Manager,Pool
import os,time,random
def reader(q):
print("reader启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in range(q.qsize()):
print("reader从Queue获取到消息:%s" % q.get(True))
def writer(q):
print("writer启动(%s),父进程为(%s)" % (os.getpid(), os.getppid()))
for i in "itcast":
q.put(i)
if __name__=="__main__":
print("(%s) start" % os.getpid())
q = Manager().Queue() # 使用Manager中的Queue
po = Pool()
po.apply_async(writer, (q,))
time.sleep(1) # 先让上面的任务向Queue存入数据,然后再让下面的任务开始从中取数据
po.apply_async(reader, (q,))
po.close()
po.join()
print("(%s) End" % os.getpid())
运行结果:
(11095) start
writer启动(11097),父进程为(11095)
reader启动(11098),父进程为(11095)
reader从Queue获取到消息:i
reader从Queue获取到消息:t
reader从Queue获取到消息:c
reader从Queue获取到消息:a
reader从Queue获取到消息:s
reader从Queue获取到消息:t
(11095) End
06-案例:文件夹copy器(多进程版1)
07-案例:文件夹copy器(多进程版2)
第六分部 协程
王铭东老师,在协程这一块讲得很透彻。但是精华部分都在第4小节gevent,可能是老师为了让学生更多的理解协程,在前面又讲了yield和greenlet两种实现协程的方法。但是这两种实现协程的方法不实用,因此,在以后使用协程的时候,只需要了解这两种方法,读别人代码时,知道这两种方法是实现协程的方法即可。因此将王铭东老师讲得其他关于协程的内容,降级为参考资料。
01-协程介绍
协程,又称微线程,纤程。英文名Coroutine.
协程是python个中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的资源)。
python中要以实现协和的方法不止一种,如:
(1)使用yield实现协程。
(2)使用greenlet实现协程。
(3)使用gevent实现协程。
上述三种方法中,gevent最方法实用。其是当一个gevent遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的gevent,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证了高效运行,而不是等待IO 。
本节内容我们以gevent为例学习协程,有关yield和greenlet,仅作为了解内容即可,遇到别人的代码出现此部分内容,能看懂即可。这三种方法均在王铭东老师的讲得中有详细讲解,需要叶可看查即可。
02-gevent
1.安装gevent库
pip3 install gevent
2.gevent的使用
import gevent
def f1(n):
for i in range(n):
print("-----f1-----", i)
def f2(n):
for i in range(n):
print("-----f2-----", i)
def f3(n):
for i in range(n):
print("-----f3-----", i)
g1 = gevent.spawn(f1, 5)
g2 = gevent.spawn(f2, 5)
g3 = gevent.spawn(f3, 5)
g1.join() # join会等待g1标识的那个任务执行完毕之后 对其进行清理工作,其实这就是一个 耗时操作
g2.join()
g3.join()
运行结果
-----f1----- 0
-----f1----- 1
-----f1----- 2
-----f1----- 3
-----f1----- 4
-----f2----- 0
-----f2----- 1
-----f2----- 2
-----f2----- 3
-----f2----- 4
-----f3----- 0
-----f3----- 1
-----f3----- 2
-----f3----- 3
-----f3----- 4
可以看到,3个greenlet是依次运行而不是交替运行。
3.gevent切换执行
import gevent
def f1(n):
for i in range(n):
print("-----f1-----", i)
gevent.sleep(1)
def f2(n):
for i in range(n):
print("-----f2-----", i)
gevent.sleep(1)
def f3(n):
for i in range(n):
print("-----f3-----", i)
gevent.sleep(1)
g1 = gevent.spawn(f1, 5)
g2 = gevent.spawn(f2, 5)
g3 = gevent.spawn(f3, 5)
g1.join() # join会等待g1标识的那个任务执行完毕之后 对其进行清理工作,其实这就是一个 耗时操作
g2.join()
g3.join()
# 使用gevent来实现多任务的时候,有一个很特殊的地方
# 它可以自行切换协程指定的任务,而且切换的前提是:当一个任务用到耗时操作(例如延时),它就会把这个时间拿出来去做另外的任务
# 这样做最终实现了多任务 而且自动切换
想要让gevent自动切换任务,就需要有耗时操作,只要有耗时操作,gevent就是自动进行切换
4.给程序打补丁
import gevent
import time
def f1(n):
for i in range(n):
print("-----f1-----", i)
# gevent.sleep(1)
time.sleep(1)
def f2(n):
for i in range(n):
print("-----f2-----", i)
# gevent.sleep(1)
time.sleep(1)
def f3(n):
for i in range(n):
print("-----f3-----", i)
# gevent.sleep(1)
time.sleep(1)
g1 = gevent.spawn(f1, 5)
g2 = gevent.spawn(f2, 5)
g3 = gevent.spawn(f3, 5)
g1.join() # join会等待g1标识的那个任务执行完毕之后 对其进行清理工作,其实这就是一个 耗时操作
g2.join()
g3.join()
# 使用gevent来实现多任务的时候,有一个很特殊的地方
# 它可以自行切换协程指定的任务,而且切换的前提是:当一个任务用到耗时操作(例如延时),它就会把这个时间拿出来去做另外的任务
# 这样做最终实现了多任务 而且自动切换
可以看到上面的代码,是一行行打印出来的,也就是说time.sleep直接让整个程序”慢“了下来,我们应该利用好本任务中的耗时的这个时间,去执行其他的任务,从而实现多任务,
但是,如果一个程序在之前已经写了很多次的time.sleep,如果每次都把它改为gevent.sleep的话,就麻烦了,所以我们可以用一个特殊的方式,打补丁。
import gevent
import time
from gevent import monkey
monkey.patch_all() # 这句话一定要放到 使用time等耗时操作的前面,它最后的的效果是 将time模块中的延时全部替换为 gevent中的演示
# time模块中的延时是不具备 自动切换任务的功能,而gevent中的延时 具备,因此我们需要将time全部改为gevent,
# 为了更快速的让本.py中的所有time变为gevent所以我们需要执行 monkey.patch_all()
def f1(n):
for i in range(n):
print("-----f1-----", i)
# gevent.sleep(1)
time.sleep(1)
def f2(n):
for i in range(n):
print("-----f2-----", i)
# gevent.sleep(1)
time.sleep(1)
def f3(n):
for i in range(n):
print("-----f3-----", i)
# gevent.sleep(1)
time.sleep(1)
g1 = gevent.spawn(f1, 5)
g2 = gevent.spawn(f2, 5)
g3 = gevent.spawn(f3, 5)
g1.join() # join会等待g1标识的那个任务执行完毕之后 对其进行清理工作,其实这就是一个 耗时操作
g2.join()
g3.join()
# 使用gevent来实现多任务的时候,有一个很特殊的地方
# 它可以自行切换协程指定的任务,而且切换的前提是:当一个任务用到耗时操作(例如延时),它就会把这个时间拿出来去做另外的任务
# 这样做最终实现了多任务 而且自动切换
可以看到通过添加monkey.patch_all()能够让程序中看上去的time.sleep也具备了自动切换任务的功能,实际上它会悄悄的修改程序中time.sleep为gevent.sleep从而实现功能。
5. 使用joinall
import gevent
import random
import time
from gevent import monkey
monkey.patch_all()
def coroutine_work(coroutine_name):
for i in range(10):
print(coroutine_name, i)
time.sleep(random.random())
def coroutine_work2(coroutine_name):
for i in range(10):
print(coroutine_name, i)
time.sleep(random.random())
gevent.joinall([
gevent.spawn(coroutine_work, "work1"),
gevent.spawn(coroutine_work2, "work2")
])
运行结果
work1 0
work2 0
work2 1
work1 1
work2 2
work1 2
work2 3
work1 3
work2 4
work1 4
work2 5
work1 5
work2 6
work1 6
work2 7
work1 7
work2 8
work1 8
work2 9
work1 9
为了更简单的使用gevent实现相似的多任务,可以使用gevent.joinall,只要将得到的协程对象放到里面即可。
适合做相似的功能。
6.方法解析
(1)gevent.spawn(f,a,b)
gevent.spawn(f,a,b)
# 作用:创建线程对象。
# 参数:第一个参数是函数名称,其所所有参数,依次为函数的位置参数。(2)gevent.join(timeout)
gevent.join(timeout)
# 参数timeout:阻塞当前程序运行的时间为timeout秒。如果不传入timeout参数值,则
方法会一直阻塞当前程序,直到相应的协程执行完毕。
# 作用:阻塞当前程序(3)gevent.getcurrent()
gevent.getcurrent()
# 作用:获取当前协和对象。(4)gevent.sleep(seconds)
gevent.sleep(seconds)
# 让当前协程暂停 seconds 秒,同时允许 gevent 调度器切换到其他可执行的协程,以实现并发执行。(5)gevent.joinall(greenlets)
gevent.joinall(greenlets)
# 作用:函数会启动传入的协程列表,并等待它们全部执行完成。
# 参数greenlets:参数值是一个协和对象列表。(6) monkey.patch_all()
monkey.patch_all()
# 这是 gevent 中非常重要的一个操作,它会将 Python 标准库中的一些阻塞式系统调
用(如 socket、threading 等)替换为 gevent 中的非阻塞式版本,这样可以
让 gevent 库更好地发挥其协程的优势,实现高并发的效果。
# 老师说:添加此句话后,相当于将代码中time.sleep(1)执行时等同于
genvent.sleep(1)的运行效果。具体用法可以见相应示例代码。03 参考资料:王铭东老师其他关于协程的笔记
01-协程介绍,计算密集型、I0密集型
1.协程
协程,又称微线程,纤程。英文名Coroutine.协程是python个中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的资源)。
python中要以实现协和的方法不止一种,如:
(1)使用yield实现协程。
(2)使用greenlet实现协程。
(3)使用gevent实现协程。
上述三种方法中,gevent最方法实用。其是当一个gevent遇到IO(指的是input output 输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的gevent,等到IO操作完成,再在适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent为我们自动切换协程,就保证了高效运行,而不是等待IO 。
本节内容我们以gevent为例学习协程,有关yield和greenlet,仅作为了解内容即可,遇到别人的代码出现此部分内容,能看懂即可。这三种方法均在王铭东老师的讲得中有详细讲解,需要叶可看查即可。
2.协程是啥
{% em color="#2ff700"%}协程是python个中另外一种实现多任务的方式{% endem %},只不过比线程更小占用更小执行单元(理解为需要的资源)。 为啥说它是一个执行单元,因为它自带CPU上下文。这样只要在合适的时机,我们可以把一个协程切换到另一个协程。 只要这个过程中保存或恢复 CPU上下文那么程序还是可以运行的。
{% em color="#2ff700"%}通俗的理解:在一个线程中的某个函数,可以在任何地方保存当前函数的一些临时变量等信息,然后切换到另外一个函数中执行,注意不是通过调用函数的方式做到的,并且切换的次数以及什么时候再切换到原来的函数都由开发者自己确定{% endem %}。
3.协程和线程差异
在实现多任务时,线程切换从系统层面远不止保存和恢复 CPU上下文这么简单。 操作系统为了程序运行的高效性每个线程都有自己缓存Cache等等数据,操作系统还会帮你做这些数据的恢复操作。所以线程的切换非常耗性能。但是协程的切换只是单纯的操作CPU的上下文,所以一秒钟切换个上百万次系统都抗的住。
4.简单实现协程
import time
def work1():
while True:
print("----work1---")
yield
time.sleep(0.5)
def work2():
while True:
print("----work2---")
yield
time.sleep(0.5)
def main():
w1 = work1()
w2 = work2()
while True:
next(w1)
next(w2)
if __name__ == "__main__":
main()
运行结果:
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
----work1---
----work2---
...省略...
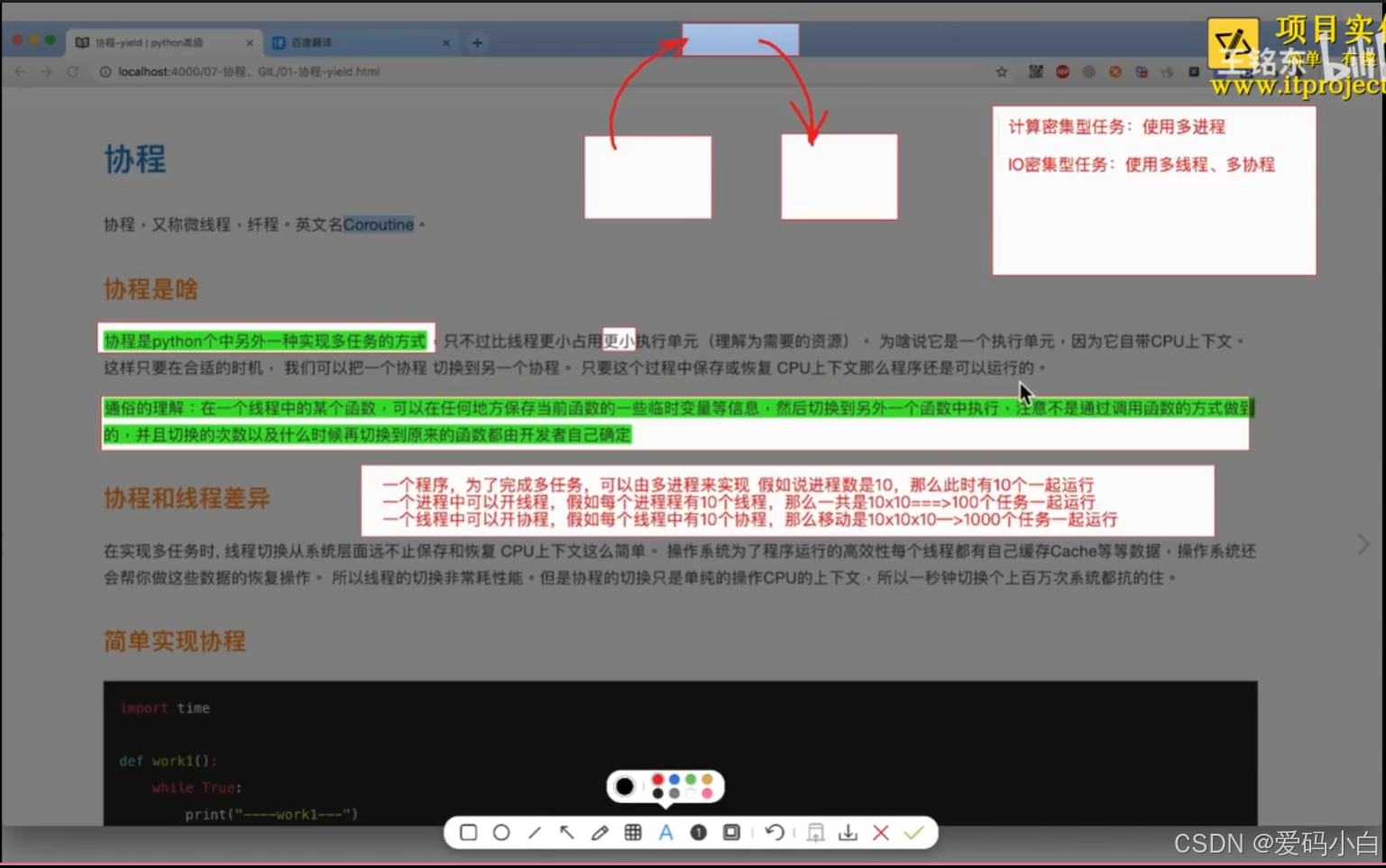
02-使用yield实现协程
03-使用greenlet实现协程
greenlet
安装方式使用如下命令安装greenlet模块:
sudo pip3 install greenlet
from greenlet import greenlet
import time
def test1():
while True:
print("---A--")
gr2.switch()
time.sleep(0.5)
def test2():
while True:
print("---B--")
gr1.switch()
time.sleep(0.5)
gr1 = greenlet(test1)
gr2 = greenlet(test2)
#切换到gr1中运行
gr1.switch()
# 协程与进程、线程的不同
# 1. 进程、线程 创建完之后,到底是哪个进程、线程执行 不确定,这要让操作系统来进行计算(调度算法,例如优先级调度)
# 2. 协程是可以人为来控制的
运行效果
---A--
---B--
---A--
---B--
---A--
---B--
---A--
---B--
...省略...
04-使用gevent实现协程
已经将本小内容放置在第02小节中。

















 2642
2642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









