






零、学习目标
- 了解HDFS存储架构
- 理解HDFS文件读写原理
一、导入新课
- 通过上次学习,对HDFS有了一定的认识,如果想要更好地使用HDFS,就必须学习HDFS的架构和读写数据的原理。本次课将针对HDFS的架构和原理进行详细讲解。
二、新课讲解
(一)HDFS存储架构
HDFS是一个分布式的文件系统,相比普通的文件系统来说更加复杂,因此在学习HDFS的操作之前有必要先来学习一下HDFS的存储架构。
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点(NameNode)和若干个数据节点(DataNode)(如下图所示)。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。每个数据节点的数据实际上是保存在本地Linux文件系统中的。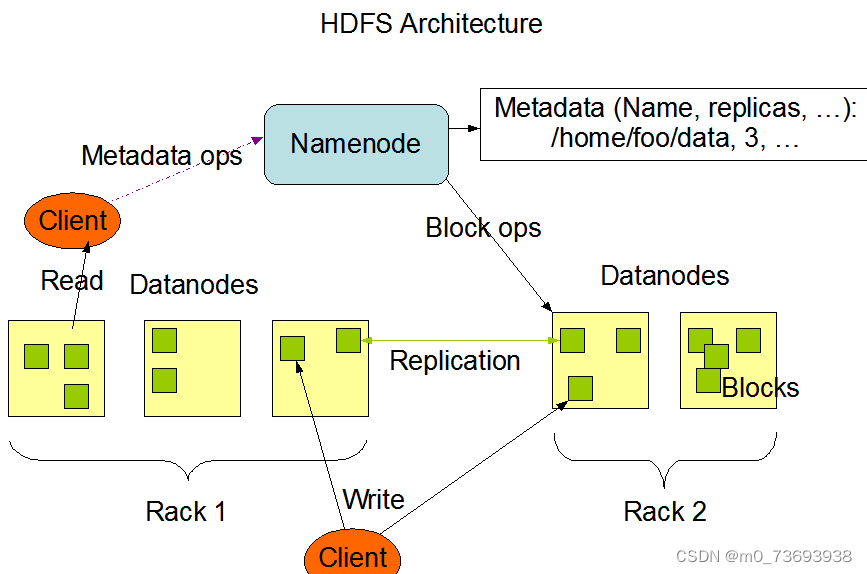
详情参看官网:Apache Hadoop 3.3.4 – HDFS Architecture
在名称节点启动的时候,它会将fsimage文件中的内容加载到内存中,之后再执行edits文件中的各项操作,使得内存中的元数据和实际的同步,存在内存中的元数据支持客户端的读操作。
一旦在内存中成功建立文件系统元数据的映射,则创建一个新的fsimage文件和一个空的edits文件。
名称节点起来之后,HDFS中的更新操作会重新写到edits文件中,因为fsimage文件一般都很大(GB级别的很常见),如果所有的更新操作都往fsimage文件中添加,这样会导致系统运行得十分缓慢,但是,如果往edits文件里面写就不会这样,因为edits要小很多。每次执行写操作之后,且在向客户端发送成功代码之前,edits文件都需要同步更新。
SecondaryNameNode会定期和NameNode通信,请求其停止使用edits文件,暂时将新的写操作写到一个新的文件edits.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别。
SecondaryNameNode通过HTTP GET方式从NameNode上获取到fsimage和edits文件,并下载到本地的相应目录下。
SecondaryNameNode将下载下来的fsimage载入到内存,然后一条一条地执行edits文件中的各项更新操作,使得内存中的fsimage保持最新;这个过程就是edits和fsimage文件合并。
SecondaryNameNode执行完上一步操作之后,会通过post方式将新的fsimage文件发送到NameNode节点上。
NameNode将从SecondaryNameNode接收到的新fsimage替换旧fsimage文件,同时将edits.new替换edits文件,通过这个过程edits就变小了。
在HDFS的设计中,并不支持把系统直接切换到辅助名称节点,从这个角度来讲,辅助名称节点只是起到了名称节点的“检查点”作用,并不能起到“热备份”作用。
(二)HDFS文件读写原理
1、HDFS写数据原理
- Client从HDFS中存储数据,即为Write(写)数据。
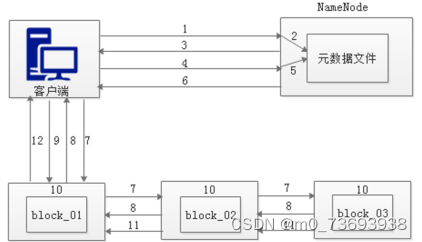
(1)客户端发起文件上传请求,通过RPC(远程过程调用)与NameNode建立通讯
(2)NameNode检查元数据文件的系统目录树
(3)若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件
(4)客户端请求上传第一个Block数据块以及数据块副本的数量
(5)NameNode检测元数据文件中DataNode信息池,找到可用的数据节点
(6)NameNode检查元数据文件的系统目录树
(7)若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件
(8)DataNode之间建立Pipeline后,逐个返回建立完毕信息
(9)客户端与DataNode建立数据传输流,开始发送数据包
(10)客户端向DataNode_01上传第一个Block数据块,当DataNode_01收到一个Packet就会传给DataNode_02,DataNode_02传给DataNode_03,DataNode_01每传送一个Packet都会放入一个应答队列等待应答。
(11)数据被分割成一个个Packet数据包在Pipeline上依次传输,而在Pipeline反方向上,将逐个发送Ack,最终由Pipeline中第一个DataNode节点DataNode_01将Pipeline的 Ack信息发送给客户端。
(12)DataNode返回给客户端,第一个Block块传输完成。客户端则会再次请求NameNode上传第二个Block块和第三块到服务器上,重复上面的步骤,直到3个Block都上传完毕。
2、HDFS读数据原理
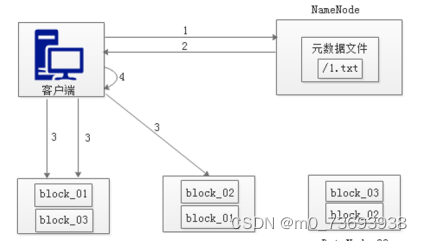
从HDFS中查找数据,即为Read(读)数据。
(1)客户端向NameNode发起RPC请求,来获取请求文件Block数据块所在的位置。
(2)NameNode检测元数据文件,会视情况返回Block块信息或者全部Block块信息,对于每个Block块,NameNode都会返回含有该Block副本的DataNode地址。
(3)客户端会选取排序靠前的DataNode来依次读取Block块,每一个Block都会进行CheckSum若文件不完整,则客户端会继续向NameNode获取下一批的Block列表,直到验证读取出来文件是完整的,则Block读取完毕。
(4)客户端会把最终读取出来所有的Block块合并成一个完整的最终文件(例如:1.txt)。















 4977
4977











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









