







关于朴素贝叶斯的理论,已在机器学习之朴素贝叶斯分类器中进行了详细说明,但是没有经历coding亲自见证效果,还是无法真正掌握。
本篇旨在理论的基础上灵活运用朴素贝叶斯进行分类。
再来回顾下朴素贝叶斯分类器的思想、算法流程,顺道把用到的Python函数罗列出来。
算法思想
比如我们想判断一个邮件是不是垃圾邮件,那么我们知道的是这个邮件中的词的分布,那么我们还要知道:垃圾邮件中某些词的出现是多少,就可以利用贝叶斯定理得到。
朴素贝叶斯最常见的分类应用是对文档进行分类,因此,最常见的特征条件是文档中,出现词汇的情况,通常将词汇出现的特征条件用词向量
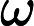 表示,由多个数值组成,数值的个数和训练样本集中的词汇表个数相同。朴素贝叶斯分类器中的一个假设是:每个特征同等重要,每个属性归属于此类的概率独立于其余所有属性。
表示,由多个数值组成,数值的个数和训练样本集中的词汇表个数相同。朴素贝叶斯分类器中的一个假设是:每个特征同等重要,每个属性归属于此类的概率独立于其余所有属性。
算法流程
1.数据准备:(收集数据+处理数据+提取数据特征)将数据预处理为数值型或者布尔型,如对文本分类,需要将文本解析为词向量 。
2.训练数据:根据训练样本集计算词项出现的概率,训练数据后得到各类下词汇出现概率的向量 。
3. 测试数据:评估对于测试数据集的预测精度作为预测正确率。
4.合并代码:使用所有代码呈现一个完整的、独立的朴素贝叶斯算法的实现。
使用朴素贝叶斯过滤垃圾邮件
文件夹spam和ham中各有25封txt文档形式的邮件正文,两个文件夹分别分类为1和0,如打开ham中2.txt文件,其内容为:
函数
loadDataSet()
创建数据集,这里的数据集是已经拆分好的单词组成的句子。
createVocabList(dataSet)
找出这些句子中总共有多少单词,以确定我们词向量的大小。
setOfWords2Vec(vocabList, inputSet)
将句子根据其中的单词转成向量,这里用的是伯努利模型,即只考虑这个单词是否存在。
bagOfWords2VecMN(vocabList, inputSet)
这个是将句子转成向量的另一种模型,多项式模型,考虑某个词的出现次数。
trainNB0(trainMatrix,trainCatergory)
计算P(i)和P(w[i]|C[1])和P(w[i]|C[0]),这里有两个技巧,一个是开始的分子分母没有全部初始化为0是为了防止其中一个的概率为0导致整体为0,另一个是后面乘用对数防止因为精度问题结果为0
classifyNB(vec2Classify, p0Vec, p1Vec, pClass1)
根据贝叶斯公式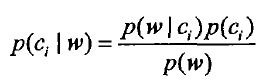 计算这个向量属于两个集合中哪个的概率高。
计算这个向量属于两个集合中哪个的概率高。
利用以上文档,进行朴素贝叶斯分类算法训练和测试:
1 对邮件的文本划分成词汇,长度小于2的默认为不是词汇,过滤掉即可。返回一串小写的拆分后的邮件信息。
def textParse(bigString): #input is big string, #output is word list
import re
listOfTokens = re.split(r'\W*', bigString) return [tok.lower() for tok in listOfTokens if len(tok) > 2]
2 文档词袋模型:使用数组代替集合数据结构,可以保存词汇频率信息。
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
3 输入为25封正常邮件和25封垃圾邮件。50封邮件中随机选取10封作为测试样本,剩余40封作为训练样本。
训练模型:40封训练样本,训练出先验概率和条件概率;
测试模型:遍历10个测试样本,计算垃圾邮件分类的正确率。
def spamTest():
docList=[]; classList = []; fullText =[]
for i in range(1,26):
wordList = textParse(open('email/spam/%d.txt' % i).read())
# print wordList
docList.append(wordList)
fullText.extend(wordList)
classList.append(1)
wordList = textParse(open('email/ham/%d.txt' % i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)#create vocabulary
trainingSet = range(50); testSet=[] #create test set
for i in range(10):
randIndex = int(random.uniform(0,len(trainingSet)))
testSet.append(trainingSet[randIndex])
del(trainingSet[randIndex])
trainMat=[]; trainClasses = []
for docIndex in trainingSet:#train the classifier (get probs) trainNB0
trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNB0(array(trainMat),array(trainClasses))
errorCount = 0
for docIndex in testSet: #classify the remaining items
wordVector = bagOfWords2VecMN(vocabList, docList[docIndex])
if classifyNB(array(wordVector),p0V,p1V,pSpam) != classList[docIndex]:
errorCount += 1
print "classification error",docList[docIndex]
print 'the error rate is: ',float(errorCount)/len(testSet)
#return vocabList,fullText
近期热文
分享 | 由0到1走入Kaggle-入门指导 (长文、干货)
... ...
迟做总比不做好;晚来总比不来强。

更多干货内容请关注微信公众号“AI 深入浅出”
长按二维码关注














 9928
9928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









