




 本文详细介绍了Linux及UNIX环境中强大的数据处理工具awk。阐述了其概念、工作流程,涵盖基本语法、程序执行方式、记录和域、变量、操作符、模式、控制语句、格式化输出、数组等内容,还给出了利用数组统计字符串出现次数等实战示例。
本文详细介绍了Linux及UNIX环境中强大的数据处理工具awk。阐述了其概念、工作流程,涵盖基本语法、程序执行方式、记录和域、变量、操作符、模式、控制语句、格式化输出、数组等内容,还给出了利用数组统计字符串出现次数等实战示例。
目录
1.1. 概念
awk是Linux以及UNIX环境中现有的功能最强大的数据处理工具,awk其名称得自于它的创始人 Alfred Aho 、Peter Weinberger 和 Brian Kernighan 姓氏的首个字母
awk是一种处理文本数据的编程语言,适合文本处理和报表生成,awk的设计使得它非常适合于处理由行和列组成的文本数据。
awk 还是一种编程语言环境,它提供了正则表达式的匹配,流程控制,运算符,表达式,变量以及函数等一系列的程序设计语言所具备的特性,它从C语言中获取了一些优秀的思想
1.2. 工作流程
1.2.1. 如图:
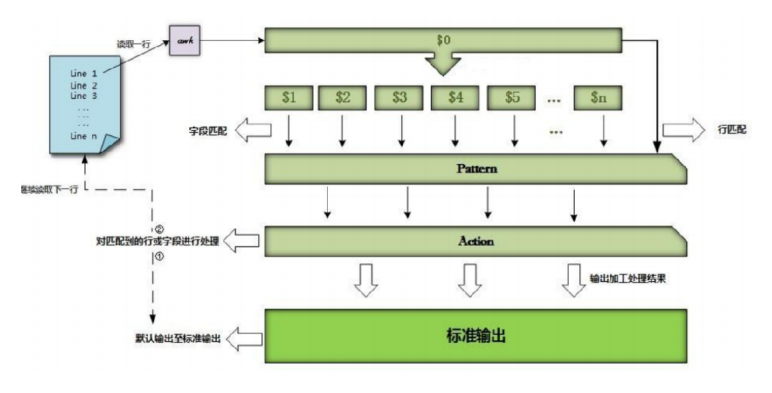
1.2.2. 流程:
第一步:自动从指定的数据文件中读取行文本。
第二步:自动更新awk的内置系统变量的值,例如列数变量NF、行数变量NR、行变量 以及各个列变量1、$2等等
第三步:依次执行程序中所有的匹配模式及其操作
第四步:当执行完程序中所有的匹配模式及其操作之后,
如果数据文件中仍然还有为读取的数据行,则返回到第
(1)步,重复执行(1)~(4)的操作。
1.3. awk命令的基本语法
任何awk语句都由模式( pattern )和动作( action )组成
(1)模式:由一组用于测试输入行是否需要执行动作的规则
(2)动作:包含语句,函数和表达式的执行过程
(3)简言之,模式决定动作何时触发和触发事件,动作执行对输入行的处理
1.3.1. 格式:
awk 'BEGIN{ commands } pattern{ commands } END{ commands }' [INPUTFILE…]
# 以上三部分可选1.3.2. BEGIN模式与END模式
BEGIN模式是一种特殊的内置模式,其执行的时机为awk程序刚开始执行,但是又尚未读取任何数据之前。因此,该模式所对应的操作仅仅被执行一次,当awk读取数据之后,BEGIN模式便不再成立。所以,用户可以将与数据文件无关,而且在整个程序的生命周期中,只需执行1次的代码放在BEGIN模式对应的操作中,一般用于打印报告的标题和更改内在变量的值
END模式是awk的另外一种特殊模式,该模式执行的时机与BEGIN模式恰好相反,它是在awk命令处理完所有的数据,即将退出程序时成立,在此之前,END模式并不成立。无论数据文件中包含多少行数据,在整个程序的生命周期中,该模式所对应的操作只被执行1次。因此,一般情况下,用户可以将许多善后工作放在END模式对应的操作中EN,一般用于打印总结性的描述或数值总和
例
[root@server ~]# awk 'BEGIN {print "BEGIN..."} {print $0} END {print "The End"}' /etc/fstab
[root@server ~]# awk 'BEGIN {print "line one \n line two \n line three"}'
[root@server ~]# awk 'BEGIN {print "this is test"}'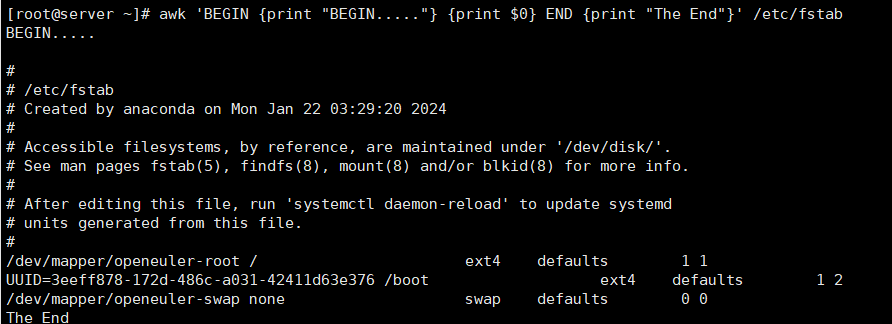

1.3.3. awk的输出
格式:
awk 'BEGIN{ commands } {print item1,item2,……} END{ commands }' [INPUTFILE…]各项目之间使用逗号隔开,而输出时则以空格字符分隔
输出的item可以为字符串或数值、当前记录的字段(如$1)、变量或awk的表达式;数值会先转换为字符串,然后再输出
1.4. awk程序执行方式
1.4.1. 通过命令行执行awk程序
[root@server ~]# vim input
# 输入多个回车符
[root@server ~]# awk '/^$/{print "This is a blank line"}' input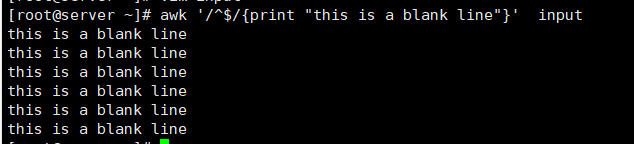
1.4.2. awk命令调用脚本执行
在awk程序语句比较多的情况下,用户可以将所有的语句写在一个脚本文件中,然后通过awk命令来解释并执行其中的语句。awk调用脚本的语法如下
awk -f program-file file-f选项表示从脚本文件中读取awk程序语句,program-file
表示awk脚本文件名称,file表示要处理的数据文件
例
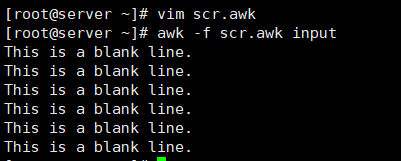
[root@server ~]# vim input # 新建awk脚本,输入以下内容
'/^$/{print "This is a blank line"}'
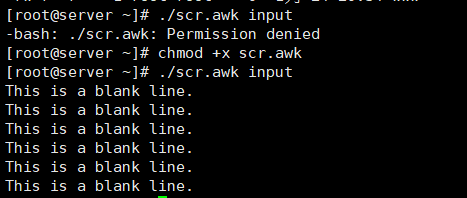
[root@server ~]# awk -f scr.awk input
1.4.3. 直接使用awk脚本文件调用
在上面介绍的两种方式中,用户都需要输入awk命令才能
执行程序。除此之外,用户还可以通过类似于Shell脚本的
方式来执行awk程序。在这种方式中,需要在awk程序中
指定命令解释器,并且赋予脚本文件的可执行权限。其中
指定命令解释器的语法如下
#!/bin/awk -f以上语句必须位于脚本文件的第一行
通过以下命令执行awk程序:
./awk-script.awk file例:
[root@server ~]# vim scr.awk
#!/bin/awk -f # 注意需要增加,表示使用什么解释器来执行
/^$/{print "This is a blank line."}
[root@server ~]# chmod o+x scr.awk
[root@server ~]# ./scr.awk input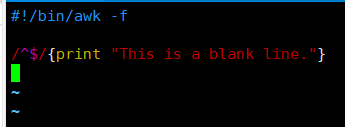
1.5. 记录和域
1.5.1. 概念
awk认为输入文件是结构化的,awk将每个输入文件行定义为记录,行中的每个字符串定义为域,域之间用空格,Tab键或其他符号进行分隔,分隔域的符号就叫做分隔符,默认为空格或tab
awk定义域操作符$来指定执行动作的域,域操作符$后面跟数字或变量来标识域的位置,每条记录的域从1开始编号,如$1表示第一个域 $0表示所有域
1.5.2. 例
# 准备示例文件
[root@server ~]# vim awk1.txt
# 输入以下内容
Li xiaoming xian 13311111111
zhang cuihua baoji 13322222222
wang xiaoer xianyang 13333333333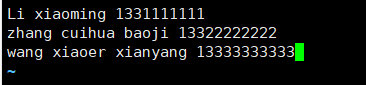
[root@server ~]# vim awk1.txt
[root@server ~]# awk '{print $0}' awk1.txt # 所有域
Li xiaoming xian 13311111111
zhang cuihua baoji 13322222222
wang xiaoer xianyang 13333333333
[root@server ~]# awk '{print $1}' awk1.txt # 第一个域,即第一列
Li
zhang
wang
[root@server ~]# awk '{print $2}'
awk1.txt
xiaoming
cuihua
xiaoer
[root@server ~]# awk '{print $3}' awk1.txt
xian
baoji
xianyang
[root@server ~]# awk '{print $4}' awk1.txt # 第4例
13311111111
13322222222
13333333333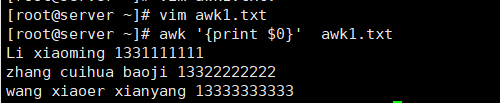

# 操作符$之后可以跟变量或表达式
[root@server ~]# awk 'BEGIN {one=1;two=2}
{print $(one+two)}' awk1.txt
xian
baoji
xianyang[root@server ~]# awk '/^[^#]/{print $3}' /etc/fstab
xfs
xfs
swap
# ^[^#]表示不以#开头的行#检索包含swap的第一列信息
[root@server ~]# awk '/swap/{print $1}' /etc/fstab1.5.3. 使用-F 参数指定域的间隔符
# 查询文件中的所有账户名
[root@server ~]# awk -F ":" '{print $1}' /etc/passwd # 指定冒号为分隔符
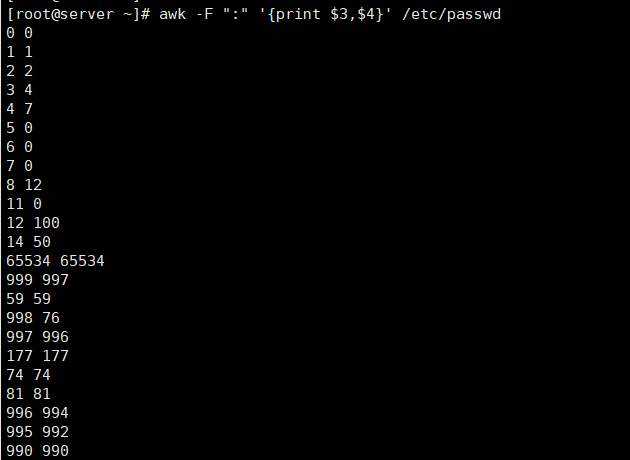
#查询文件中的UID与GID
[root@server ~]# awk -F ":" '{print $3,$4}' /etc/passwd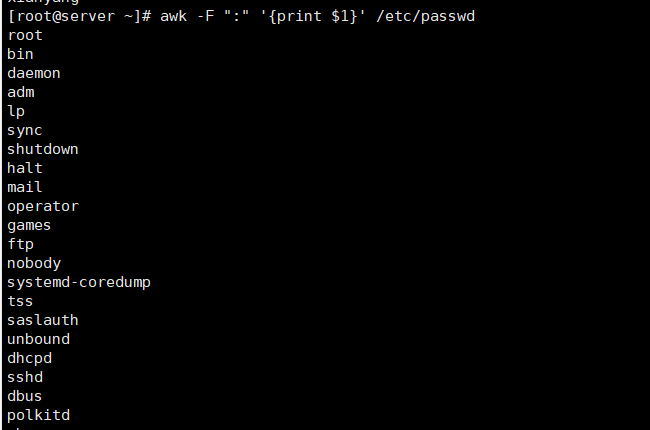
1.5.4. 通过系统变量FS改变分隔符
awk默认的分隔符存储在FS变量中,默认为空格或tab
[root@server ~]# awk 'BEGIN {print $FS}'设置FS变量改变域分隔符
[root@server ~]# awk 'BEGIN {FS=":"} {print $2}' /etc/passwd1.5.5. NR、NF、FILENAME量
概念:
NR变量表示记录数,即被处理过的行数
NF变量表示记录的域数量
FILENAME:处理的文件名
示例
[root@server ~]# awk '{print NF,NR,$0} END {print FILENAME}' awk1.txt
4 1 Li xiaoming xian 13311111111
4 2 zhang cuihua baoji 13322222222
4 3 wang xiaoer xianyang 13333333333
awk1.txt
[root@server ~]# awk '{print
"第",NR,"行","有",NF,"域" > "/root/t1.txt"}'
awk1.txt
[root@server ~]# cat t1.txt
第 1 行 有 4 域
第 2 行 有 4 域
第 3 行 有 4 域

1.6. awk的变量
1.6.1. 概念
与其他的程序设计语言一样,awk本身支持变量的相关操作,包括变量的定义和引用,以及参与相关的运算等。此外,还包含了许多内置的系统变量
变量的作用是用来存储数据。变量由变量名和值两部分组成,其中变量名是用来实现变量值的引用的途径,而变量值则是内存空间中存储的用户数据
awk的变量名只能包括字母、数字和下划线,并且不能以数字开头。例如abc、a、z以及a123都是合法的变量名,而123abc则是非法的变量名。另外,awk的变量名是区分大小写的,因此,X和x分别表示不同的变量
awk中的变量类型分为两种,分别为字符串和数值。但是在定义awk变量时,毋需指定变量类型,awk会根据变量所处的环境自动判断。如果没有指定值,数值类型的变量的缺省值为0,字符串类型的变量的缺省值为空串
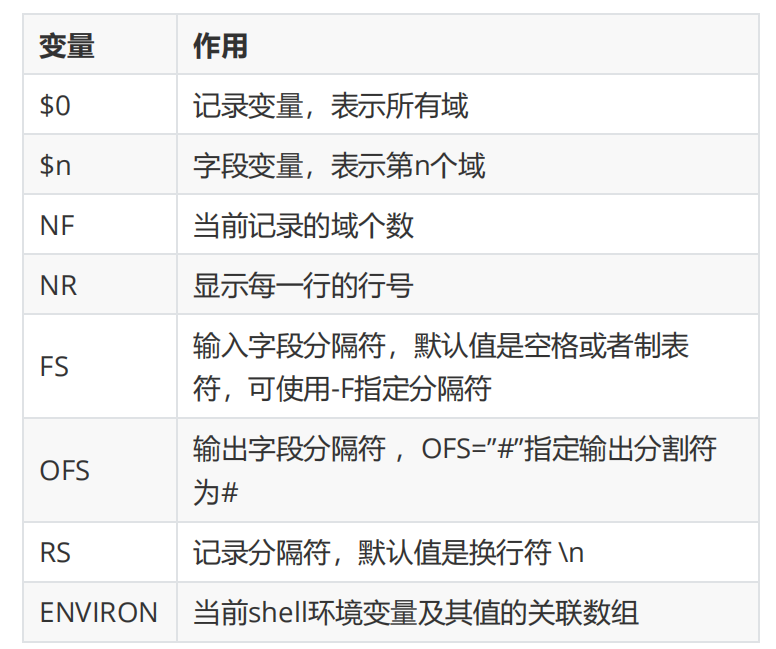
1.6.2. 内置变量
示例
# 准备数据文件
[root@server ~]# vim awk2.txt # 输入以下内容
zhangsan 68 88 92 45 71
lisi 77 99 63 52 84
wangwu 61 80 93 77 81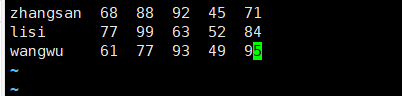
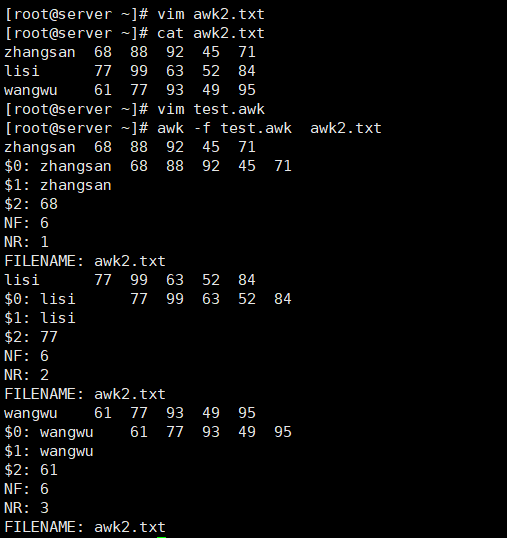
[root@server ~]# vim test.awk
{
print
print "$0:",$0
print "$1:",$1
print "$2:",$2
print "NF:",NF
print "NR:",NR
print "FILENAME:",FILENAME
}
# awk命令调用脚本
[root@server ~]# awk -f test.awk awk2.txt
# OFS设置输出结果的间隔符为\t
[root@server ~]# awk -F ":" 'BEGIN{OFS="\t"} {print $1,$2}' /etc/passwd# 京东面试题:查看文件中所有空白行的行号
[root@server ~]# awk '/^$/{print NR}' /root/anaconda-ks.cfg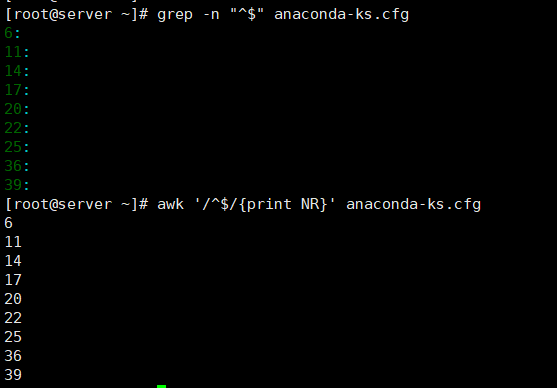
1.6.3. 用户自定义变量:
awk允许用户自定义自己的变量以便在程序代码中使用
变量名命名规则与大多数编程语言相同,只能使用字母、
数字和下划线,且不能以数字开头
awk变量名称区分字符大小写
例
[root@server ~]# awk 'BEGIN {test="hello world";print test}'
hello world
[root@server ~]# awk -v test="china" 'BEGIN{print test}'
china![]()
![]()
1.7. awk操作符
awk是一种编程语言环境,因此,它也支持常用的运算符以及表达式,例如算术运算、逻辑运算以及关系运算等
1.7.1. 算术运算符
示例
[root@server ~]# awk 'BEGIN{x=2;y=3;print x+y,x-y,x/y,x%y,x^y,x**y}'
5 -1 0.666667 2 8 8
# 统计某个文件目录内容文件占用字节数
[root@server ~]# ll | awk 'BEGIN{size=0} {size=size+$5} END{print "size is",size}'
size is 1308
[root@server ~]# ll /etc | awk 'BEGIN{size=0} {size=size+$5} END{print "size is",size}'
size is 1058127
[root@server ~]# ll /etc | awk 'BEGIN{size=0} {size=size+$5} END{print "size is",size/1024,"KB"}'
size is 1033.33 KB![]()
1.7.2. 赋值运算符
= += -= /= *= %= ^=[root@server ~]# awk 'BEGIN{a=5;a+=5;print a}'
# 截取IP地址
[root@server ~]# ifconfig ens160 | awk 'NR==2 {print $2}'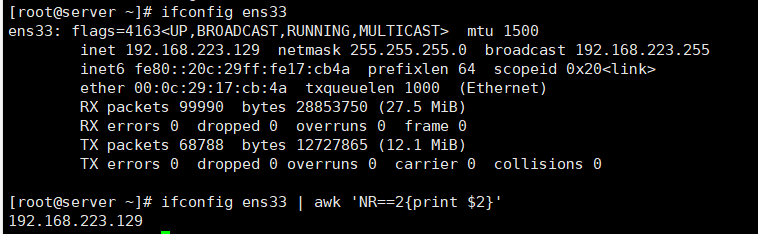
1.7.3. 条件运算符:三目
格式
expression?value1:value2是一种三目运算符,原则:表达expression成立时,value1作为整个表达式结果,否则为value2作为整个表达式结果
例
[root@server ~]# vim awk2.txt
3 6
10 9
3 3
[root@server ~]# awk '{max=$1>$2?$1:$2 ; print NR ,"max=",max}' awk2.txt

1.7.4. 逻辑运算符
符号:&& || !
1.7.5. 关系运算符
符号:> < >= <= == != ~ (匹配) !~ (不匹配)
示例
# 查询/etc/passwd 文件第三列小于10以下的数据,且仅列出账号与第三列
[root@server ~]# cat /etc/passwd | awk -F : '$3<10 {print $1 "\t" $3}'
[root@server ~]# awk 'BEGIN{a=1;b=2;print (a>2&&b>1,a=1||b>1)}'
0 11.7.6. 其它运算符
++ -- + - 等# awk中操作数为非数值时会自动转为数值0
[root@server ~]# awk 'BEGIN{a="b";print
a++,++a}'
0 2
[root@server ~]# awk 'BEGIN{a="hello";print a++,++a}'
0 2
[root@server ~]# awk
'BEGIN{a="AAAAAAAAAAAAAAA";print a++,++a}'
# count计算行数,但未赋初始值,会自动转为数值0
[root@server ~]# awk '{++count;print $0}
END{print "user count is :",count}' /etc/passwd1.8. awk的模式
awk支持关系表达式、正则表达式、混合模式、BEGIN模式、END模式等
1.8.1. 关系表达式
新建示例文件
例
[root@server ~]# awk '$2>80 {print}'
awk3.txt
liming 85
wangwei 99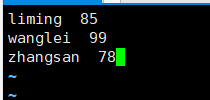
1.8.2. 正则表达式
与sed一样awk的正则表达式必须放置在两个/之间(/正则表达式/)
[root@server ~]# awk '/^l/{print}' awk3.txt
[root@server ~]# awk '/^l|z/{print}' awk3.txt
[root@server ~]# awk '/root/{print $0}' /etc/passwd
[root@server ~]# awk -F : '$5~/root/{print $0}' /etc/passwd1.8.3. 混合模式
awk支持关系表达式或正则表达式,还支持逻辑运算符&&、|| 、!组成的混合表达式
[root@server ~]# awk '/^l/ && $2 > 80 {print}' awk3.txt
liming 851.8.4. BEGIN模式与END模式
1.9. awk控制语句
1.9.1. if语句
格式:与C语言类似
if (expression)
{
语句1
语句2
……
}
else
{
语句3
语句4
……
}示例
[root@server ~]# vim if.awk
#!/bin/awk -f
{
if($2>=90)
{
print $1,"A"
}
else
{
if($2>=80)
{
print $1,"B"
}
else
{
print $1,"C"
}
}
}
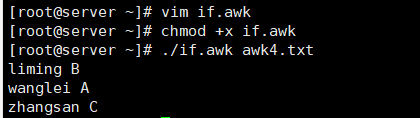
[root@server ~]# chmod +x if.awk
[root@server ~]# ./if.awk awk4.txt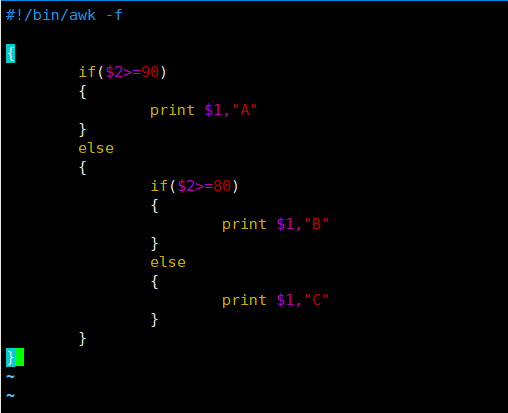
[root@server ~]# awk 'BEGIN{FS=":"} {if($3<$4) print $0}' /etc/passwd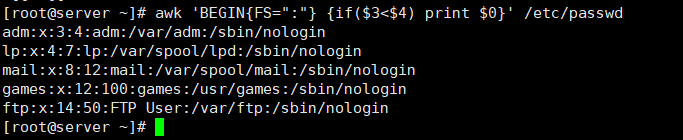
# ~为模糊匹配
[root@server ~]# awk 'BEGIN{FS=":"} {if($3~1 || $4~10) print $0}' /etc/passwd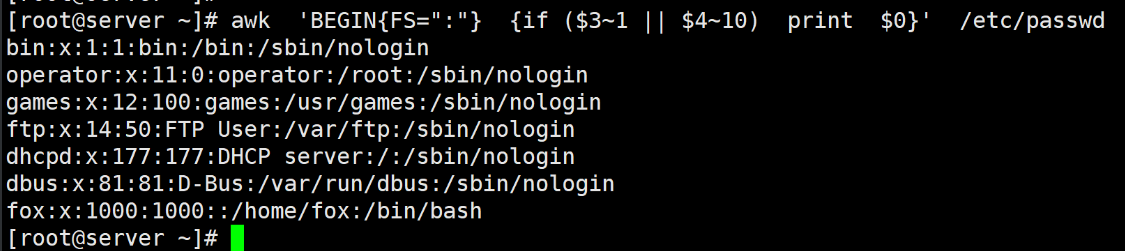
# 查询cpu占用虑大于指定数值的信息
[root@server ~]# ps -eo user,pid,pcpu,comm | awk '{if($3>=0.1) print $0}'
# 统计系统账户数
[root@server ~]# awk -F ":" '{if($3<1000) {x++} else {y++}} END{print "系统账户数:",x,"\n","普通账户数:",y}' /etc/passwd1.9.2. fox循环
格式与c语言格式相同
例1
[root@server ~]# awk 'BEGIN{for(i=1;i<=100;i++) {sum=sum+i} print "sum=",sum}'
sum= 5050![]()
例2:
[root@server ~]# vim for.awk
#!/bin/awk -f
BEGIN{
for(i=1;i<=9;i++)
{
for(j=1;j<=i;j++)
{
if(i*j<10)
{
row=row" "i*j
}
else
{
row=row" "i*j
}
}
print row
row=""
}
}
[root@server ~]# chmod +x for.awk
[root@server ~]# ./for.awk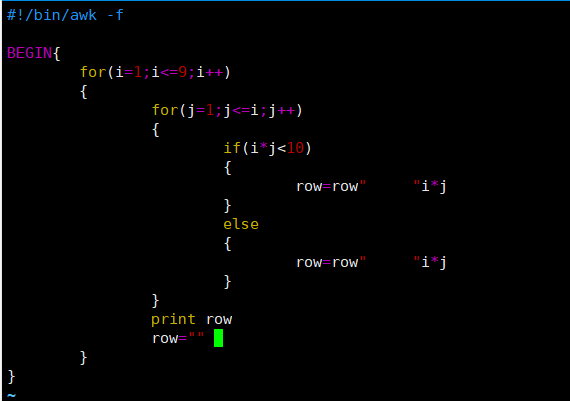
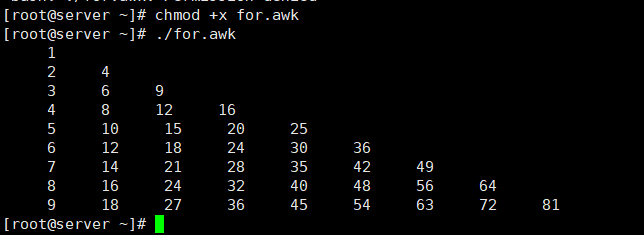
1.9.3. while循环
格式1
while(expression)
{
循环语句1
循环语句2
……
}格式2
do{
循环语句1
循环语句2
……
}while(expression)示例
[root@server ~]# awk 'BEGIN{while(i<=100) {sum+=i;i++} print "sum=",sum}'
sum= 5050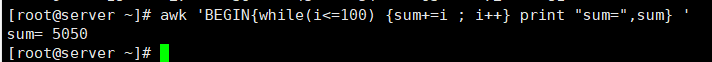
1.9.4. break、continue语句
1.9.5. next语句
next语句并不是用在循环结构中,而是用于awk整个执行过程中,当awk程序执行时,若遇到next语句则提前结束本行处理,会继续读取下一行
例
# 访问UID值为奇数行的内容
[root@server ~]# awk -F : '{if($3%2==0) next;print $1,$3}' /etc/passwd
1.9.6. exit
作用:终止awk程序执行
1.10. 格式化输出
1.10.1. 格式
与c语言格式相同
printf("format\n",输出列表项)1.10.2. format
format是一种控制输出格式的字符串,以%开头,后跟上
一个字符,如:
%c:字符
%d,%i:十进制整数
%u:无符号整数
%f:浮点数
%e,%E:科学计数法
%s:字符串
%%:显示一个%format说明符有修饰符
N:数字
-:左对齐
+:显示数值符号1.10.3. 注意
printf语句不会打印\n
字符串一般使用双引号作为定界符
1.10.4. 示例
[root@server ~]# awk 'BEGIN{printf("%d,%c\n","A",97)}'
0,a
[root@server ~]# awk 'BEGIN{printf("%5d\n",12345)}'
12345
[root@server ~]# awk 'BEGIN{printf("%5d\n",123456789)}'
123456789
[root@server ~]# awk 'BEGIN{printf("%5d\n",123)}'
123
[root@server ~]# awk 'BEGIN{printf("%-5d,%d\n",123,456)}'
123 ,456
[root@server ~]# awk 'BEGIN{printf("%10.2f\n",123.4567)}'
123.46
[root@server ~]# awk 'BEGIN{printf("%.2f\n",123.4567)}'
123.46
[root@server ~]# awk 'BEGIN{printf("%e\n",123.4567)}'
1.234567e+02
[root@server ~]# awk 'BEGIN{printf("%E\n",123.4567)}'
1.234567E+02
[root@server ~]# awk 'BEGIN{printf("%-10s\t%-10s\n","name","score")} {printf("%-10s\t%-10s\n",$1,$2)}' awk3.txt
name score
liming 85
wangwei 99
zhangsan 68





![]()


# 计算内存的使用率
[root@server ~]# free | awk 'NR==2 {printf("内存使用率:%%%.2f\n",($3/$2)*100)}'
内存使用率:%72.43
1.11. awk数组
1.11.1. 索引数组
索引数组以数字作为下标
通过数组的下标(索引)引用数组中所有元素,下标一般
从0开始
例
[root@server ~]# awk 'BEGIN{a[0]="a";a[1]="b";a[2]="c";a[3]="d";print a[0],a[1],a[2],a[3]}'
awk中元素设置为“空字符串”是合法的,注意:空格不是空
[root@server ~]# awk 'BEGIN{a[0]="a" ; a[2]="c" ; a[3]="d" ; print a[0],a[1],a[2],a[3]}'
当一个元素不存在于数组时,若此时引用该不存在的数值,awk会自动创建该元素,若为空字符串
[root@server ~]# awk 'BEGIN{a[0]="a";a[1]="";a[2]="c";a[3]="d";print a[4]}'
# 注意:a[4]不存在时会自动创建1.11.2. 关联数组
原则:数组的索引以字符串作为下标
[root@server ~]# awk
'BEGIN{a["zero"]="a";a["one"]="";a["tow"]="c" ; a["three"]="d";print a["tow"]}'
c
注意:
awk数组本质是一种使用字符串作为下标的关联数组
awk数组中的数字下标最终会转为字符串
1.11.3. 循环遍历数组
格式1
for(初始化;条条件表达式;步长)
{
循环体语句
}格式2
for(变量 in 数组)
{
循环体语句
}例1:利用for循环中变量i与数组下标都是“数字”的这一特
性,按顺序输出数组的元素
[root@server ~]# awk 'BEGIN{a[0]="a" ; a[1]="b" ; a[2]="c" ; a[3]="d" ; for(i=0;i<4;i++) {print i,a[i]}}'
0 a
1 b
2 c
例2:数组中下标为“无规律的字符串”时,使用for循环的in访问
[root@server ~]# awk 'BEGIN{a["zero"]="a";a["one"]="b";a["three"]="c" ; for(i in a) {print i,a[i]}}'
three c
zero a
one b
注意:awk数组本质是一种“关联数组”,默认打印的顺序是无序的,例1中时借助for循环中循环变量i的值实现输出有序的,由于i的值是数值并递增的,且刚好与数组下标相等,则使得使用数值作为数组下标时,for循环访问是按一定顺序的。
1.11.4. 利用数组统计字符串出现次数
awk中可以利用数值进行运算,如:
[root@server ~]# awk 'BEGIN{a=1;print ++a}'
2变量值为字符串的自增运算
[root@server ~]# awk 'BEGIN{a="test" ; print a,++a}'
test 1注意
awk中字符串参与运算时会被当做数值0
当应用一个不存在的元素时,元素被赋值为空字符串,
若该空字符串参与运算会被当做数值0
例1:统计文本中IP出现次数
# 准备文本
[root@server ~]# vim iptest.txt
192.168.48.1
192.168.48.2
192.168.48.5
192.168.48.1
192.168.48.3
192.168.48.1
192.168.48.5
192.168.48.2
192.168.48.4
192.168.48.1[root@server ~]# awk '{count[$1]++} END{for(i in count) {print i,"次数:",count[i]}}' iptest.txt
192.168.48.1 次数: 4
192.168.48.2 次数: 2
192.168.48.3 次数: 1
192.168.48.4 次数: 1
192.168.48.5 次数: 2分析创建一个count数组,并将文件中ip地址行作为元素的下标,所以执行第一行时,引用的数组为count["192.168.48.1"]
count["192.168.48.1"]++相当于存储的数据为0并自增1
继续下一行处理,运算过程同上当再次遇到192.168.48.1IP地址时,会使用上一次的数组存储数据参与自增运算
直到所有行遍历结束,执行END模式完成打印
例2:查看服务器连接状态并汇总
[root@server ~]# netstat -an | awk '/^tcp/{++s[$NF]} END{for(i in s) {print i,s[i]}}'
LISTEN 8
ESTABLISHED 2分析
netstat -an:查看连接
/^tcp/ : 通过正则过滤
$NF:过滤结果的第6行
1.12. 实战
<1>输出当前系统所有用户的UID:
# awk –F : '{print $3}' /etc/passwd
注释:-F :
指定分隔符为:
$3指定第三段
<2>输出当前系统所有用户的UID,在首行加入UserUid:
# awk -F : 'BEGIN{print "UserUid"}{print $3}' /etc/passwd
<3>输出当前系统shell为/bin/bash的用户名,在最后一行加入END That is last line!!!
# awk -F : /bash$/'{print $1}END{print "END That is last line!!!"}' /etc/passwd
<4>输出当前系统上GID为0的用户的用户名
# awk -F : '$4==0{print $1}' /etc/passwd
<5>输出当前系统上GID大于500的用户的用户名
# awk -F : '$4>500{print $1}' /etc/passwd
<6>输出当前系统上的所有用户名和UID,以“ # # ”为分隔符
# awk -F : 'OFS=" # # "{print $1,$3}' /etc/passwd
<7>输出/etc/passwd文件中以“:”为分隔符的最后一段。
# awk -F : '{print $NF}' /etc/passwd
<8>对/etc/passwd文件中输出的每一行计数
# awk '{print NR,$0}' /etc/passwd
<9>对/etc/passwd、/etc/fstab文件中输出的每一行分别计数。
# awk '{print FNR,$0}' /etc/passwd /etc/fstab
<10>自定义变量
# awk -v var="Linux.com.cn" BEGIN'{print var}'
<11>以printf格式输出用户名,UID、GID
# awk -F : '{printf "%-15s %d %8i\n",$1,$3,$4}' /etc/passwd
<12>检测当前系统上所有用户,如果用户名为root输出:Admin
如果用户名不为root输出:Common User
# awk -F : '{if ($1=="root") printf "%-15s: %s\n", $1,"Admin"; else printf "%-15s: %s\n", $1, "Common User"}' /etc/passwd
<13> 统计当前系统上UID大于500的用户的个数
# awk -F : -v sum=0 '{if ($3>=500) sum++}END{print sum}' /etc/passwd
<14>读取/etc/passwd文件中的每一行的每一个字段,输出每个字段中字符个数大于等于四的字段。
# awk -F : '{i=1;while (i<=NF) { if(length($i)>=4) {print $i}; i++ }}' /etc/passwd
<15>使用do-while语句输出/etc/passwd中每一行中的前三个字段
# awk -F: '{i=1;do {print $i;i++}while(i<=3)}' /etc/passwd
<16>使用for语句输出/etc/passwd中每一行中的前三个字段
# awk -F: '{for(i=1;i<=3;i++) print $i}' /etc/passwd
<17>统计/etc/passwd文件中各种shell的个数
# awk -F : '$NF!~/^$/{BASHsum[$NF]++}END{for(A in BASHsum){printf "%-15s:%i\n",A,BASHsum[A]}}' /etc/passwd
注释:
$NF!~/^$/:最后一个字段非空
BASHsum[$NF]++:最后一个字段相同的加一
<18> 显示当前系统上UID号为偶数的用户名和UID
# awk -F : '{if($3%2==1) next;{printf "%-15s%d\n",$1,$3}}' /etc/passwd
<19> 统计当前系统上以tcp协议工作的各端口的状态数
# netstat -ant | awk '/^tcp/ {++STATE[$NF]} END {for(a in STATE) print a, STATE[a]}'
<20>输出/etc/passwd中的每一行以||||隔开,默认不换行
# awk -F : 'BEGIN{ORS="||||"}{print $0}' /etc/passwd
















 67
67

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









