







1. 论文思想
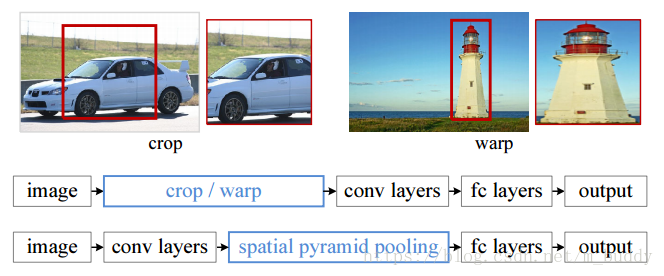
SPP-Net的提出首先是为了解决传统CNN网络对于输入图像尺寸具有严格的大小限制,其原因也就是最后的全连接层需要的输入尺寸是固定的。那么对于一副比较大的图像就需要进行剪裁了,如下图所示:
但是这样会造成数据失真以及数据的不完整。那么,要使CNN网络可以接受任意图像尺寸的输入,那就需要将提供给全连接层的参数量固定下来,这就需要SPP-Net了,也就是上图中下面的结构。其是在最后一个卷积的基础上增加一个SPP层,使得给卷积的数据固定,从而使得网络可以输入任意尺寸的图像。
对于分类问题,在Pascal VOC 2007和Caltech101数据集上,SPP-net使用单一的全图像表示,无需微调,就能实现较好的分类结果;对于目标检测问题上,使用SPP-net,网络只从整个图像计算特征映射一次,然后在任意区域(子图像)中汇集特征,生成固定长度的表示,以训练检测器,避免了重复计算卷积的特征,在Pascal VOC 2007取得了与RCNN一致甚至更好的检测结果,并且速度快于RCNN。
SPP-Net具有的特点
(1)不管输入的尺寸如何,网络输出的大小总是固定的
(2)在多个空间尺度上使用单个滑动窗,多尺度是为了提升性能
(3)由于输入尺度的灵活性,SPP可以在可变尺度下提取特征
2. SPP Layer
CNN网络中卷积层是对输入数据的尺寸不做要求的,但是后面接的全连接层就有要求了,论文里面借鉴了BOW模型的思想,目的就是让特征表达的数目或者维度固定下来。
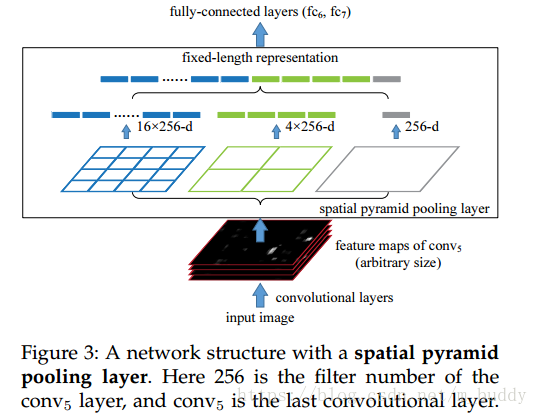
在这篇论文里面是采用空间金字塔的思想,限定输出的数据,其网络结构如下:
下面是一个典型3层结构的SP-Net结构:
在上图中网络包含了
3
∗
3
,
2
∗
2
,
1
∗
1
3*3, 2*2, 1*1
3∗3,2∗2,1∗1的bins(用
n
∗
n
n*n
n∗n表示),而需要计算的互动窗口
s
i
z
e
X
sizeX
sizeX与
s
t
r
i
d
e
stride
stride论文中是通过向上取整和向下取整实现的,对于输入的feature map大小为
a
∗
a
a*a
a∗a,则前面的两个参数可以通过如下计算得到:
s
i
z
e
X
=
a
/
n
[
向
上
取
整
]
sizeX = a/n[向上取整]
sizeX=a/n[向上取整]
s
i
z
e
X
=
a
/
n
[
向
下
取
整
]
sizeX = a/n[向下取整]
sizeX=a/n[向下取整]

3. Caffe中的实现
3.1 Caffe中的运用
首先来看下在proto文件中SPP的定义:
#caffe.proto中的关于SPP层参数的定义
message SPPParameter {
enum PoolMethod {
MAX = 0;
AVE = 1;
STOCHASTIC = 2;
}
optional uint32 pyramid_height = 1;
optional PoolMethod pool = 2 [default = MAX]; // The pooling method
enum Engine {
DEFAULT = 0;
CAFFE = 1;
CUDNN = 2;
}
optional Engine engine = 6 [default = DEFAULT];
}
接下来是在Caffe的prototxt中该如何定义:
# SPP网络定义范例
#之前的Pooling层
#layer {
# name: "pool5"
# type: "Pooling"
# bottom: "conv5"
# top: "pool5"
# pooling_param {
# pool: MAX
# kernel_size: 3
# stride: 2
# }
#}
layer {
name: "spatial_pyramid_pooling"
type: "SPP"
bottom: "conv5"
top: "pool5"
spp_param {
pool: MAX
pyramid_height: 2 # SPP的level的数量
}
}
3.2 SPP-Net在Caffe中的实现
首先还是来看看SPP-Net在Caffe中的整体结构是什么样子的
for (int i = 0; i < pyramid_height_; i++) {
// pooling layer input holders setup 整个pooling结构的输入输出数据存放位置
pooling_bottom_vecs_.push_back(new vector<Blob<Dtype>*>);
pooling_bottom_vecs_[i]->push_back(split_top_vec_[i]);
// pooling layer output holders setup
pooling_outputs_.push_back(new Blob<Dtype>());
pooling_top_vecs_.push_back(new vector<Blob<Dtype>*>);
pooling_top_vecs_[i]->push_back(pooling_outputs_[i]);
// pooling layer setup
LayerParameter pooling_param = GetPoolingParam( //按照层获得Pooling的参数
i, bottom_h_, bottom_w_, spp_param);
//将得到的Pooling参数生成Pooling layer 再关联网络的输入与输出
pooling_layers_.push_back(shared_ptr<PoolingLayer<Dtype> > (
new PoolingLayer<Dtype>(pooling_param)));
pooling_layers_[i]->SetUp(*pooling_bottom_vecs_[i], *pooling_top_vecs_[i]);
// flatten layer output holders setup flatten 数据准备与参数设置,参数输入为Pooling之后的数据
flatten_outputs_.push_back(new Blob<Dtype>());
flatten_top_vecs_.push_back(new vector<Blob<Dtype>*>);
flatten_top_vecs_[i]->push_back(flatten_outputs_[i]);
// flatten layer setup
LayerParameter flatten_param;
flatten_layers_.push_back(new FlattenLayer<Dtype>(flatten_param));
flatten_layers_[i]->SetUp(*pooling_top_vecs_[i], *flatten_top_vecs_[i]);
// concat layer input holders setup 把flatten之后的数据concat起来
concat_bottom_vec_.push_back(flatten_outputs_[i]);
}
// concat layer setup 构建concat层
LayerParameter concat_param;
concat_layer_.reset(new ConcatLayer<Dtype>(concat_param));
concat_layer_->SetUp(concat_bottom_vec_, top);
从上面的代码中可以看到,SPP-Net在Caffe中的实现是通过Split_layer、Pooling_layer、Concat_layer实现的,其中会根据当前的pyramid level来设置当前Pooling的参数,那么它里面的参数计算是这样计算完成的。计算过程在GetPoolingParam函数中实现的。
//根据pyramid level确定Pooling的参数
template <typename Dtype>
LayerParameter SPPLayer<Dtype>::GetPoolingParam(const int pyramid_level,
const int bottom_h, const int bottom_w, const SPPParameter spp_param) {
LayerParameter pooling_param;
int num_bins = pow(2, pyramid_level); //按照2的幂设置Pooling的参数
// find padding and kernel size so that the pooling is
// performed across the entire image
int kernel_h = ceil(bottom_h / static_cast<double>(num_bins));
// remainder_h is the min number of pixels that need to be padded before
// entire image height is pooled over with the chosen kernel dimension
int remainder_h = kernel_h * num_bins - bottom_h;
// pooling layer pads (2 * pad_h) pixels on the top and bottom of the
// image.
int pad_h = (remainder_h + 1) / 2;
// similar logic for width
int kernel_w = ceil(bottom_w / static_cast<double>(num_bins));
int remainder_w = kernel_w * num_bins - bottom_w;
int pad_w = (remainder_w + 1) / 2;
pooling_param.mutable_pooling_param()->set_pad_h(pad_h);
pooling_param.mutable_pooling_param()->set_pad_w(pad_w);
pooling_param.mutable_pooling_param()->set_kernel_h(kernel_h);
pooling_param.mutable_pooling_param()->set_kernel_w(kernel_w);
pooling_param.mutable_pooling_param()->set_stride_h(kernel_h);
pooling_param.mutable_pooling_param()->set_stride_w(kernel_w);
switch (spp_param.pool()) {
case SPPParameter_PoolMethod_MAX:
pooling_param.mutable_pooling_param()->set_pool(
PoolingParameter_PoolMethod_MAX);
break;
case SPPParameter_PoolMethod_AVE:
pooling_param.mutable_pooling_param()->set_pool(
PoolingParameter_PoolMethod_AVE);
break;
case SPPParameter_PoolMethod_STOCHASTIC:
pooling_param.mutable_pooling_param()->set_pool(
PoolingParameter_PoolMethod_STOCHASTIC);
break;
default:
LOG(FATAL) << "Unknown pooling method.";
}
return pooling_param;
}
可以从开始就看到,Pooling参数是按照2的幂次为基础进行计算的。对于SPP-Net的前向传播与反向传播可以参考对应类型层的正反传,其内部也是调用这些层的前向与后向函数实现的。














 1020
1020











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









