






使用C/C++提升性能
现在你已经知道如何混合使用Java和C/C++代码,你可能会想C/C++会比Java更好达到最佳的性能。这是不正确的,使用native代码不是所有的性能问题的答案。实际上,有时候调用native代码可能会引起性能下降。这听起来很惊讶,从Java Space切换到native Space不是没有任何耗费的。Dalvik JIT编译器同样可以产生native代码,可能会等同或者比你的native代码更好。
让我们考虑第一章的Fibonacci.computeIterativelyFaster()方法和它的C实现,如Listing 2-16所示。
Listing 2-16 Fibonacci序列的C替代实现
uint64_t computeIterativelyFaster (unsigned int n)
{
if (n > 1) {
uint64_t a, b=1;
n--;
a = n & 1;
n /= 2;
while (n-- > 0) {
a += b;
b += a;
}
return b;
}
return n;
}就像你看到的,C实现和Java实现非常相像,除了使用到了unsigned类型。你可以同样观察在Listing 2-17的Dalvik字节码,看起来像Listing 2-18的ARM的本地代码,由NDK的objdump工具产生。除了其他事情外,objdump NDK工具允许你反汇编一个二进制文件(object文件、library或者可执行文件),给出汇编代码。工具很像dexdump,dexdump在.dex文件上做相同的操作。(比如,一个应用的classes.dex文件)
NOTE:使用objdump的-d选项去反汇编一个文件,比如,objdump –d libfibonacci.so。不带有任何选项或者参数执行objdump查看所有支持的选项。NDK存在不同版本的objdump:一个针对ARM ABI,一个针对x86 ABI。
Listing 2-17 Fibonacci.iterativeFaster的Dalvik字节码
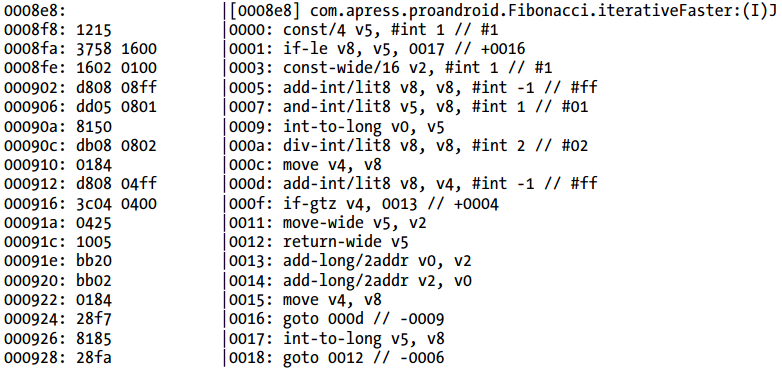
Listing 2-18 iterativeFaster的C实现的ARM汇编代码

NOTE: 参考http://infocenter.arm.com查看ARM指令的完整的文档。
汇编代码是被CPU执行的代码。因为Dalvik字节码看起来非常像汇编代码(尽管汇编代码更加紧凑),可能会发现JIT编译器生成的代码和Listing 2-18给出的本地代码非常的相像。同样的,即使字节码和本地代码显著的不同,Dalvik JIT编译器仍然会生成和NDK生成的汇编代码很相像的代码。
现在,为了能够比较这些方法,我们需要执行一些测试。实际的性能评估需要经验数据,我们测试比较4项:
(1) Java实现不通过JIT编译器
(2) Java实现通过JIT编译器
(3) Native实现(Debug)
(4) Native实现(Release)
测试骨架(Fibonacci.java中)在Listing 2-19给出,结果在图2-1和图2-2中给出。
Listing 2-19 测试骨架
static {
System.loadLibrary("fibonacci_release"); // 使用两个库
System.loadLibrary("fibonacci_debug");
}
private static final int ITERATIONS = 1000000;
private static long testFibonacci (int n)
{
long time = System.currentTimeMillis();
for (int i=0; i < ITERATIONS; i++) {
// 调用iterativeFaster(n), iterativeFasterNativeRelease(n) 或者intetrativeFasterNativeDebug(n)
callFibonacciFunctionHere(n);
}
time = System.currentTimeMillis() - time;
Log.i("testFibonacci", String.valueOf(n) + " >> Total time: " + time + "milliseconds");
}
private static void testFibonacci() {
for (int i = 0; i< 92;i++) {
testFibonacci(i);
}
}
private static native long iterativeFasterNativeRelease (int n);
private static native long iterativeFasterNativeDebug (int n);图2-1显示了上面4个实现的时间。图2-2给出了以Java带有JIT编译器的实现为参考4个实现的相对的性能。
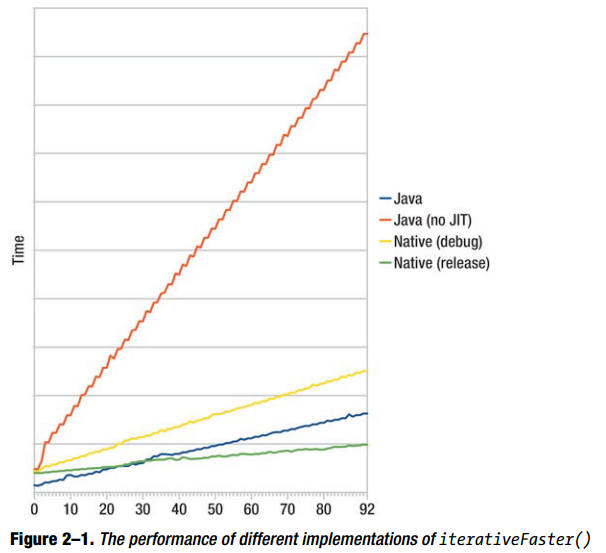
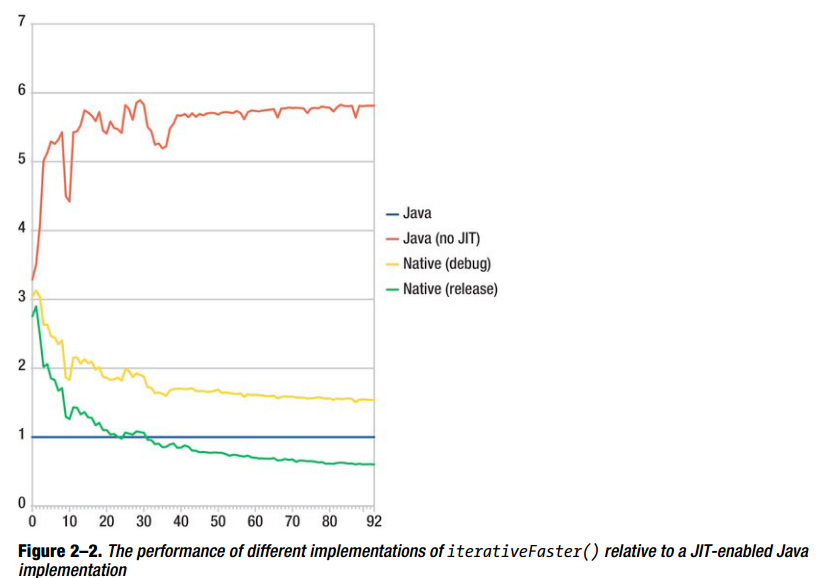
我们可以得到几个结论:
(1) Dalvik JIT编译器可以明显的提升性能。(JIT-enable的版本比JIT-disable的版本快3到6倍)
(2) native的实现不是总比JIT-enable的Java实现快
(3) 在native space花费越多的时间,Java/native转换的耗费越少
Google本身的测试显示Dalvik的JIT编译器可以通过使用CPU-intensive代码提升5倍性能,我们的结果也证实了。性能的提升依赖于代码,所以不可以总是假设有这个比例。如果你仍然期望运行一个缺少JIT的安卓版本(安卓2.1或者更早),这个测量是很重要的。某些情况下,在老的版本上为了达到可接受的用户体验使用native代码是唯一的选择。
More About JNI
我们使用的JNI glue layer是非常简单的,因为它所做的所有事情是调用另外一个C函数。不幸的是,随着事情变得复杂,它不总是简单的,当使用非原子类型或者native代码需要访问Java对象或者类的成员变量或者方法。另一方面说,你在JNI glue layer做的所有事情是非常机械的。















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









