






ARM指令
ARM指令是丰富的。Table 3-1给出了可用的ARM指令列表,每个给出了一个主要的描述,但不包括每个指令的详细信息。
如果你熟悉这些指令,你将了解到他们中的一些会比其他的使用更多,尽管不常用的那些指令经常是可以显著提升性能的。比如,ADD和MOV指令几乎是无处不在的,而SETEND指令不常用(当你需要去访问不通字节序的数据的时候,它是一个必须的指令)。
NOTE:比如,这些指令的详细信息,参考ARM编译器的Toolchain,在http://infocenter.arm.com。
Table 3-1 ARM指令
略。
ARM NEON
NEON是Cortex A处理器族的128位SIMD(单指令,多数据)扩展。如果你理解UHADD8指令在Listing 3-27做了什么,理解NEON将会很简单。
NEON寄存器被看做向量。比如,一个128位的NEON寄存器可以看做4个32位的整数,8个16位整数,甚至16个8位整数(同样的,UHADD8指令解释32位寄存器为4个8位数值)。一个NEON指令在所有的单元执行相同的操作。
NEON有几个重要的特性:
1)一个指令可以执行多个操作(毕竟,这是SIMD指令的本质)
2)独立的寄存器
3)独立的pipeline
很多NEON指令看起来像ARM指令。比如,VADD指令将两个向量对应元素相加,和ADD指令做的事情相似(尽管ADD指令简单的实现两个32位寄存器的加法,不将他们看做向量)。所有的NEON指令以字母V开头,识别他们很简单。
在你的代码中使用NEON有两个基本方式:
(1) 你可以在手写的汇编代码中使用NEON
(2) 你可以使用arm-neon.h(NDK的一个头文件)中定义的NEON函数,
NDK提供NEON的sample code(hello-neon), 所以你需要首先review这个代码。尽管NEON可以大幅提高你的性能,同样需也要你修改算法,去完全的利用矢量化。
使用NEON指令,保证你在Android.mk文件的LOCAL_SRC_FILES添加.neon扩展名。如果所有的文件编译都需要支持NEON,你可以在Android.mk设置LOCAL_ARM_NEON为true。
学习NEON的一个很好的方式是去学习安卓源代码。比如,SkBlitRow_opts_arm.cpp(在external/skia/src/opts目录)包含几个程序使用NEON指令,使用asm()或者函数。在同一个目录下,你同样可以看到SkBlitRow_opts_SSE2.cpp,包含使用x86 SIMD指令的优化程序。Skia源代码在http://code.google.com/p/skia。
CPU Features
就像你已经看到的,不是所有的CPU都是一样的。甚至同一family的处理器(比如,ARM的Cortex family),不是所有的处理器支持同样的features,因为有些是可选的。比如,不是所有的ARMv7处理器都支持NEON扩展或者VFP扩展。因为这个原因,安卓提供查询代码运行在什么样的平台上的函数。这些函数定义在cpu-featues.h,NDK提供的一个头文件。Listing 3-30给出了如何使用这些函数去决定是否一个函数可以被使用,或者利用NEON指令集。
Listing 3-30 检查CPU特性
#include <cpu-features.h>
static inline int has_features(uint64_t features, uint64_t mask)
{
return ((features & mask) == mask);
}
static void (*my_function)(int* dst, const int* src, int size); // 函数指针
extern void neon_function(int* dst, const int* src, int size); // 在某些文件中定义
extern void default_function(int* dst, const int* src, int size);
int init()
{
AndroidCpuFamily cpu = android_getCpuFamily();
uint64_t features = android_getCpuFeatures();
int count = android_getCpuCount(); // 忽略这里
if (cpu == ANDROID_CPU_FAMILY_ARM) {
if (has_features(features, ANDROID_CPU_ARM_FEATURE_ARMv7 | ANDROID_CPU_ARM_FEATURE_NEON))
{
my_function = neon_function;
}
else
{
// 这里使用默认的函数
my_function = default_function; // generic function
}
}
else
{
my_function = default_function; // generic function
}
}
void call_function(int* dst, const int* src, int size)
{
// 我们假设之前已经调用init()去设置my_function指针
my_function(dst, src, size);
}为了使用CPU的Features函数,需要在Android.mk做两件事:
(1) 添加”cpufeatures”到链接的静态库里面(LOCAL_STATIC_LIBRARIES := cpufeatures)
(2) 通过在Android.mk的最后添加$(call import-module, android/cpufeatures),导入android/cpufeatures模块
通常,为了使用最好的可能的函数,探测平台的兼容性是你首先要做的一个任务。
如果你的代码依赖于VFP扩展的存在,需要检测NEON是否被支持。ANDROID_CPU_ARM_VFPv3标志是最小的配置,16个64位的浮点寄存器(D0到D15)。如果支持NEON,32个64位的浮点寄存器是可用的(D0到D31)。寄存器被NEON和VFP公用,并且都有别名:
(1) Q0(128位)是D0和D1(都是64位)的别名
(2) D0是S0和S1的别名(S是单精度32位的寄存器)
事实上,寄存器是公用的和存在别名是非常重要的细节,所以保证当手写汇编的时候仔细的使用的寄存器。
NOTE: 参考NDK的文档,尤其是CPU-FEAATURES.html关于API更多的信息。
C扩展
Android NDK带有GCC编译器(4.4.3版使用NDK 7)。结果,你可以使用C扩展GNU Compiler Collection。尤其关注性能相关的那些:
(1) Build-in 函数
(2) Vector 指令
NOTE:参考详细的GCC C扩展列表,http://gcc/gnu.org/onlinedocs/gcc/C-Extensions.html。
Built-in函数
Build-in函数,有时被称为intrinsics,是被编译器特殊方式处理的函数。Build-in函数经常用来允许语言不支持的结构,经常是inlined,即,编译器用一系列的目标独有的指令替换调用,通常是优化过的。比如,调用_builtin_clz()函数将会导致产生一个CLZ指令(如果代码被编译为ARM,CLZ指令是可用的)。如果没有build-function的优化版本,或者优化被关掉,编译器简单的调用通用实现的函数。
比如,GCC支持如下的built-in函数:
(1) _builtin_return_address
(2) _builtin_frame_address
(3) _builtin_expect
(4) _builtin_assume_aligned
(5) _builtin_prefetch
(6) _builtin_ffs
(7) _builtin_clz
(8) _builtin_ctz
(9) _builtin_clrsb
(10) _builtin_popcount
(11) _builtin_parity
(12) _builtin_bswap32
(13) _builtin_bswap64
使用built-in函数使代码更加通用,同时可以利用一些平台可用的优化。
Vector指令
Vector指令在C代码中不怎么普遍。然而,随着越来越多的CPU支持SIMD指令,在算法中使用vector可以明显的加速代码。
Listing 3-31展示了怎么样使用vector_size变量定义你自己的vector类型,怎么可以添加两个vector。
Listing 3-31 Vectors
typedef int v4int _attribute_ ((vector_size(16)); // 4个整数的向量(16字节)
void add_buffers_vectorized (int* dst, const int* src, int size)
{
v4int * dstv4int = (v4int*) dst;
const v4int* srcv4int = (v4int*)src;
int i;
for (i = 0;i<size/4;i++) {
*dstv4int++ += *srcv4int++;
}
// leftovers
if (size & 0x3) {
dst = (int*) dstv4int;
src = (int*) srcv4int;
switch (size & 0x3) {
case 3: *dst++ += *src++;
case 2: *dst++ += *src++;
case 1:
default: *dst += *src;
}
}
}
// 简单的实现
void add_buffers(int* dst, const int* src, int size)
{
while(size--)
{
*dst++ += *src++;
}
}这段代码将如何被编译取决于目标是否支持SIMD指令和编译器是否被告知去使用这些指令。告知编译器使用NEON指令,只要在Android.mk的LOCAL_SRC_FILES简单的添加.neon后缀到文件名。或者,如果所有的文件都需要支持NEON,你可以定义LOCAL_ARM_NEON为true。
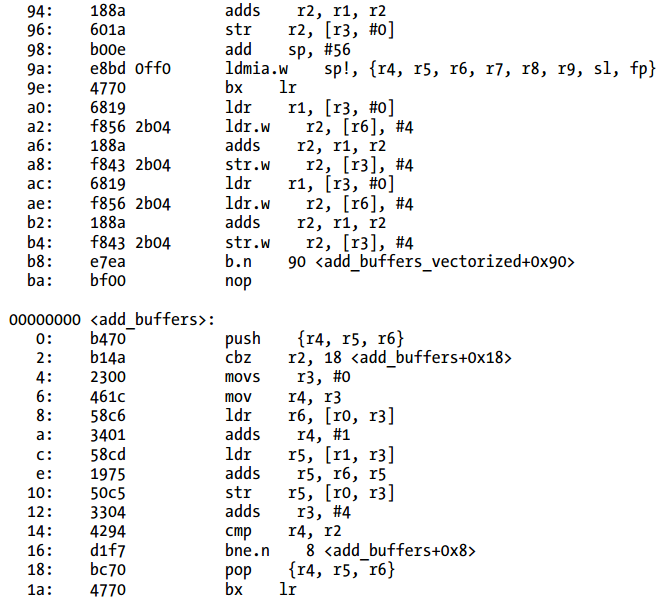
Listing 3-32给出了编译器不支持ARM SIMD指令(NEON)情况下的汇编代码,Listing 3-33给出了使用NEON指令的版本。(add_buffers函数在同样的方式下被编译,所以在第二个listing中没有给出。)loop在两个listing中用粗体字表示。
Listing 3-32 不使用NEON指令



Listing 3-33 使用NEON指令
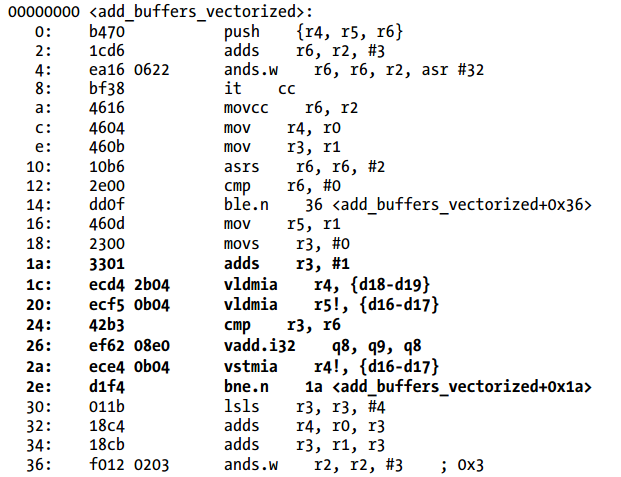

你可以看到当使用NEON的时候,loop被编译成更少的指令。作为事实,vldmia指令从内存加载4个整数,vadd.i32指令执行4次加,vstmia指令保存4个整数到内存。这些结果是更加紧凑,更加有效。
使用Vector是一把双刃剑:
(1) 当可以用的时候允许你使用SIMD指令,同时维护着一份可以针对任何ABI的通用代码,忽略是否支持SIMD指令。(在Listing3-31中的代码仅支持x86 ABI,因为他不是NEON特有)
(2) 当平台不支持SIMD指令的时候会产生低性能的代码。(add_buffers函数比它的vectorized等更加简单,结果是更加简单的汇编代码:当SIMD指令没有使用的情况下,看多少次数据是从栈中读取和写入的,在add_buffers_vectoreized)
NOTE:参考http://gcc.gnu.org/onlinedocs/gcc/Vector-Extensions.html。















 3878
3878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









