







1、阿里开源软件:DataX
DataX 是一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。(摘自百科)
2、Apache开源软件:Sqoop
Sqoop(发音:skup)是一款开源的工具,主要用于在HADOOP(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。(摘自百科)
3、Kettle开源软件:水壶(中文名)
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,数据抽取高效稳定。(摘自百科)
上面三个开源ETL工具的简介都摘自百科内容,个人kettle用的比较多,其他两个用的比较少。其实不管是开源还是商用ETL工具都自带了作业调度,但其从使用的灵活性和简易性来说,那就不如第三方专业做批量作业调度的工具了。既然都是工具,是为了方便我们使用人员,那干嘛不使用更好的工具来减轻我们的工作量,从而让我们将精力更多的投入到业务本身去呢?这里就给大家分享一个第三方开源批量作业自动化工具TASKCTL(开源社区地址:https://www.oschina.net/p/taskctl),看TASKCTL如何轻松实现开源ETL工具Datax、Sqoop、Kettle等的作业批量调度。废话不多说,直接上干货。
TASKCTL采用任务插件驱动机制,因此,可支持各种存储过程、各种脚本、以及诸如Datastage\Informatica\kettle等各种ETL工具任务,可以完成串行、并行、依赖、互斥、执行计划、定时、容错、循环、条件分支、远程、负载均衡、自定义条件等各种不同的核心调度功能。
下面以调度DataX作业类型为例:
$ cd {YOUR_DATAX_DIR_BIN}
$ python datax.py ./mysql2odps.json
我们可以看到调用datax,实际上是调用python脚本。
因此我们可以直接在taskctl中配置作业的xml片段如下:
<python>
<name>datax_job</name>
<progname>datax.py</progname> -- 此处有可能需要定位到cd {YOUR_DATAX_DIR_BIN}
<para>./mysql2odps.json</para>
</python>
当然,如果要使datax作业类型看起来更加个性化点(或者在插件中适配点什么)。我们还可以datax配置单独的任务插件,步骤如下:
1、编写调用datax的脚本文件cprundataxjob.sh:
#!bin/bash if [ $# -ne 3 ] then echo "Param error !" echo "Usage: $0 progname para expara" exit 126 fi #------------------------------------------------------------------------------ # 第一步: 接收参数 #------------------------------------------------------------------------------ ProgName=$1 Para=$2 ExpPara=$3 #------------------------------------------------------------------------------ # 第二步: 运行JOB,并等待结果 #------------------------------------------------------------------------------ #cd {YOUR_DATAX_DIR_BIN} --相当于TASKCTL中的exppara环境参数 cd ${ExpPara} #python datax.py ./mysql2odps.json python datax.py ${ProgName} #收集datax.py执行结果 retinfo=$? #------------------------------------------------------------------------------ # 第四步: 插件返回 #------------------------------------------------------------------------------ #根据retinfo的信息,返回给TASKCTL if [ ${retinfo} -eq 0 ] then echo "" echo "Run job success !" else echo "" echo "Run job failed !" fi exit ${retinfo}
配置后,把cprundataxjob.sh放到TASKCTL服务端的$TASKCTLDIR/src/plugin/dataxjob/shell/目录下
2、在TASKCTL桌面软件admin中配置插件如下图:
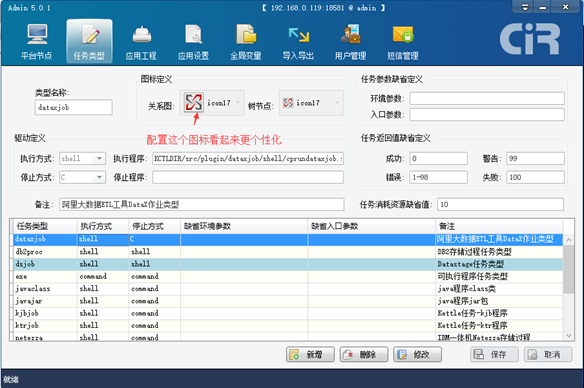
3、在designer中编写模块代码如下:
<dataxjob>
<name>MainModul_JobNode0</name>
<progname>./mysql2odps.json</progname>
<exppara>[你的datax安装路径]</exppara>
</dataxjob>
4、完成模块代码的编写后,如下:
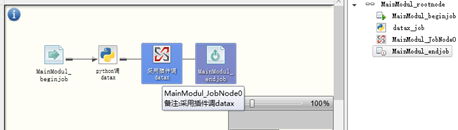















 1174
1174











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









