







https://github.com/geometer/FBReaderJ
第八章、epub文件处理 -- 定位指定段落
上一章中我们介绍了用ZLTextPlainModel类里的char数组存储.xhtml文件中的文本信息以及标签信息的流程。
本章中我们将介绍从ZLTextPlainModel类里的char数组中定位指定段落的流程。
本章涉及的核心类是Processor类(ZLTextParagraphCursor类内部类)、EntryIteratorImpl类(ZLTextPlainModel类内部类)
定位到指定段落需要两个方法互相配合:ZLTextParagraphCursor类的cursor方法和ZLTextPage类的moveStartCursor方法
ZLTextParagraphCursor类的cursor方法负责填充代表指定段落的ZLTextParagraphCursor类。在这个过程中,char数组中代表指定段落的部分转换成一个由ZLTextElement类组成的ArrayList。其中,段落中的文本信息会被转换成ZLTextElement类的子类ZLTextWord,而段落中的标签信息会被转换成ZLTextElement类的子类ZLTextControlElement。
ZLTextPage类的moveStartCursor方法负责定位到指定的段落。定位的过程主要是维护ZLTextPage类中的StartCursor属性指向的ZLTextWordCursor类。ZLTextWordCursor类中的三个属性myParagraphCursor、myElementIndex、myCharIndex结合起来就完成来了定位到指定段落的流程。这三个属性中,myParagraphCursor属性指向的就是代表指定段落的ZLTextParagraphCursor类。
当定位流程完成之后,char数组中涉及当前段落的部分会被转换成一个由ZLTextElement子类组成的ArrayList中。这个ArrayList存储在ZLTextParagraphCursor类中的myElements属性中。而同时,ZLTextParagraphCursor这个类又存储在ZLTextPage类的StartCursor属性中。
PS:整个定位流程其实也可以看成ZLTextElement子类 -> ZLTextParagraphCursor类myElements属性 -> ZLTextPage类StartCursor属性不断上推的过程。
下面我们结合ZLTextView的setModel方法详细介绍下调用这两个方法定位到定段落的具体流程:
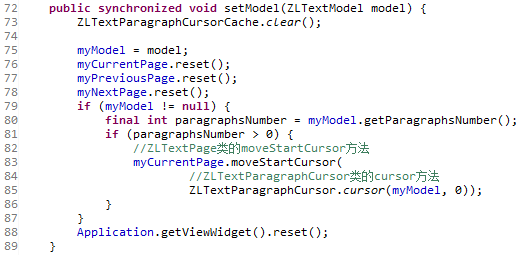
ZLTextParagraphCursor类 cursor方法:
cursor方法的第一个参数为解析xhtml文件得到的ZLTextPlainModel类(第七章中有详细介绍),第二个参数为当前要显示的段落的索引(初始时这个索引为0)
接着cursor方法以同样的参数调用了ZLTextParagraphCursor类的构造函数

ZLTextParagraphCursor类构造函数
ZLTextParagraphCursor类构造函数调用了本类的fill方法,这个方法首先调用了ZLTextPlainModel类的getParagraph方法,接着又调用了Processor类的fill方法

ZLTextPlainModel类的getParagraph方法:
这个方法的作用是初始化了一个ZLTextParagraphImpl类,并定义了这个类中的myModel属性(指向ZLTextPlainModel类)与myIndex属性(当前要显示的段落的索引)

Processor类(ZLTextParagraphCursor内部类)fill方法
这个方法将最终完成将char数组中代表当前段落的部分转换成一个元素为ZLTextElement类的ArrayList的工作。
方法大致流程是:首先通过EntryIteratorImpl类的构造方法获得正在处理的段落具体在char数组的哪个部分(67行)。然后,利用EntryIteratorImpl类next方法在char数组的这个部分里面不断读取内容并进行操作(71行)。操作分为针对文本信息(75行)和针对标签信息(84行)两种。线面在详细描述着两个方法。

EntryIteratorImpl类(ZLTextPlainModel内部类)构造函数
这个构造方法的作用就是利用当前段落的索引从ZLTextPlainModel类的三个属性指向的int数组中的当前段落在char数组的哪一部分中。
这三个属性我们已经在第七章中有介绍过了。
myStartEntryIndices属性指向的int数组记录了每个段落具体在CachedCharStorage类内部的哪一个char数组里面;
myStartEntryOffsets属性指向的int数组记录了每个段落从CachedCharStorage类内部char数组的哪个位置开始;
myParagraphLengths属性指向的int数组记录每个段落在CachedCharStorage类内部char数组中占据多少长度;
EntryIteratorImpl类(ZLTextPlainModel内部类)next方法
这个方法会在char数组的代表当前段落的部分里面不断读取内容并进行操作。
在读取的过程中首先会通过CachedCharStorage类的block方法获取对应需要显示的段落的char数组(125行),获取对应的char数组之后,代码就会利用不断递增的dataOffset变量,不断读取char数组中的内容。一旦代码读取到代表文本信息或标签信息的标示,就会进入不同的流程。
PS:我们曾在上一章中介绍过这两种标示,当时我们是这么介绍的:“每次调用addControl方法都会加入ZLTextParagraph.Entry.CONTROL(3)这个常量,这个常量是一种标示。类似的标示还有常量ZLTextParagraph.Entry.TEXT(1),我们会在下一章用到这两种变量”。

CachedCharStorage类的block方法:
我们在上一章中介绍CachedCharStorage类的时候,曾经说过“char数组的长度最长不会超过这个长度(65536),一旦超过这个长度,代码就会新建一个char数组,同时旧的数组会被持久化以便以后再用。”所以当前在内存中的char数组不一定会包含需要显示的数组,如果不包含需要显示的数组就需要根据ZLTextWritablePlainModel类的myStartEntryIndices属性找到对应的char数组。(这个属性的具体介绍也可以在上一章中找到)
获取到包含需要显示的段落的char数组后,代码就会利用不断递增的dataOffset变量,不断读取char数组中的内容。一旦代码读取到代表文本信息或标签信息的标示,就会进入不同的流程。
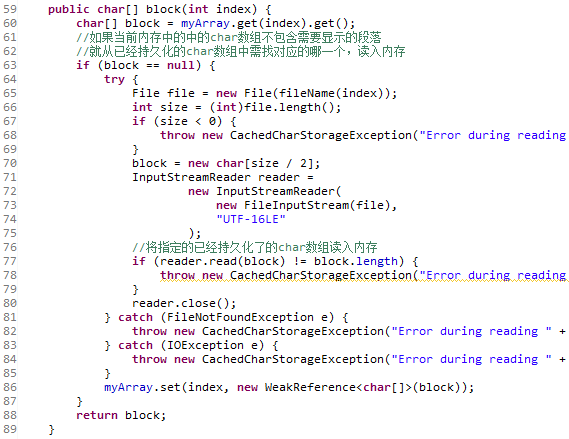
获取到包含需要显示的段落的char数组后,代码就会利用不断递增的dataOffset变量,不断读取char数组中的内容。一旦代码读取到代表文本信息或标签信息的标示,就会进入不同的流程。
文本信息(ZLTextParagraph.Entry.TEXT)
遇到代表文本的ZLTextParagraph.Entry.TEXT标示的情况:
这种情况下,代码会对分在这个标示之后的文本信息会进行两部分处理,一部分处理在EntryIteratorImpl类next方法中进行,一部分在Processor类的fill方法中进行
在EntryIteratorImpl类next方法中,会赋值两个EntryIteratorImpl类的两个变量。myTextLength属性记录文本信息的长度,myTextData属性存储当前char数组的引用。最后还通过赋值dataOffset,在char数组中向前跳过了涉及这段文本信息的部分。
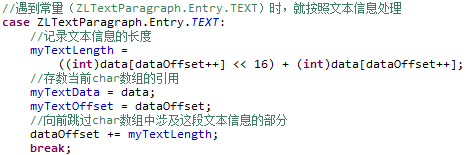
在Processor类fill方法会调用本类的processTextEntry方法

在processTextEntry方法中代码利用一个for循环,一个一个读取char数组中的元素,然后对每个元素调用Processor类的addWord方法。请注意,调用addWord方法时的参数。

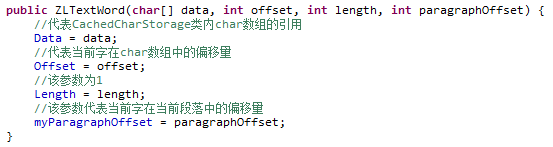
addWord方法会初始化一个ZLTextWord类,然后将这个类加入ZLTextParagraphCursor类myElements属性指向的ArrayList

请注意对比下ZLTextWord类构造函数与调用addWord方法时的参数
标签信息(ZLTextParagraph.Entry.CONTORL)
遇到代表文本的ZLTextParagraph.Entry.CONTORL标示的情况:
这种情况下,代码同样也会对跟在这个标示之后的标签信息会进行两部分处理,一部分处理在EntryIteratorImpl类next方法中进行,一部分在Processor类的fill方法中进行
EntryIteratorImpl类next方法会赋值三个属性,请尤其注意下myControlIsStart这个属性,我们会在处理样式的时候用到这个属性。

Processor类的fill方法会初始化一个ZLTextWord类,然后将这个类加入ZLTextParagraphCursor类myElements属性指向的ArrayList

当代码从ZLTextParagraphCursor类 cursor方法返回是,我们会得到新建的ZLTextParagraphCursor类,这个类中的myElements属性指向的ArrayList已经被填充了代表当前段落中文本信息的ZLTextWord类与标签信息的ZLTextControlElement类。接着就会进入ZLTextPage类的moveStartCursor方法。
ZLTextPage类的moveStartCursor方法
这个方法比较简单,其实就是将通过ZLTextParagraphCursor类的cursor方法填充好的ZLTextParagraphCursor类,赋值给ZLTextPage类内的StartCursor属性

同时,ZLTextPage类内的StartCursor属性指向的ZLTextWordCursor类进行下设置

完成moveStartCursor方法后,我们就完成“定位指定段落”的流程了。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









