







版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Jiny_li/article/details/86482112 </div>
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/ck_htmledit_views-f57960eb32.css">
<div class="htmledit_views" id="content_views">
<h3><a name="t0"></a><span>TaskManager与Slot介绍</span></h3>
Flink的每个TaskManager为集群提供solt。 solt的数量通常与每个TaskManager节点的可用CPU内核数成比例。一般情况下你的slot数是你每个节点的cpu的核数。
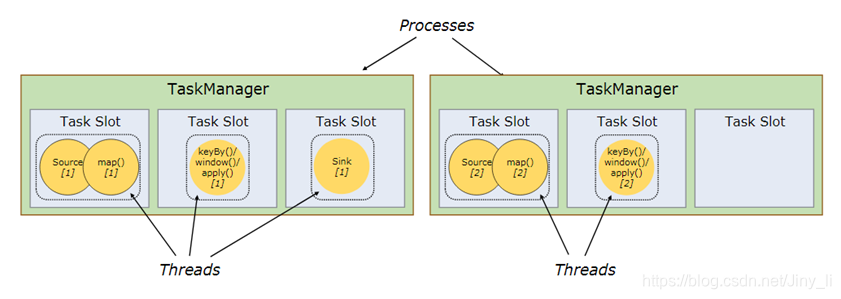
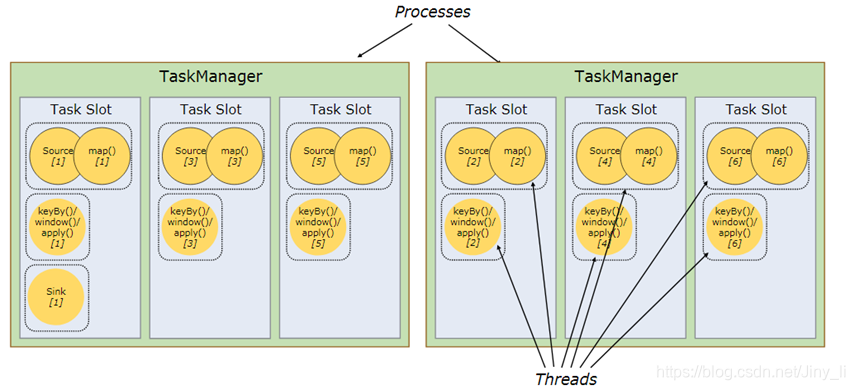
并行度(Parallel)
一个Flink程序由多个任务组成(source、transformation和 sink)。 一个任务由多个并行的实例(线程)来执行, 一个任务的并行实例(线程)数目就被称为该任务的并行度。
任务的并行度设置可以从多个层次指定
•Operator Level(算子层次)
•Execution Environment Level(执行环境层次)
•Client Level(客户端层次)
•System Level(系统层次)
并行度设置之Operator Level
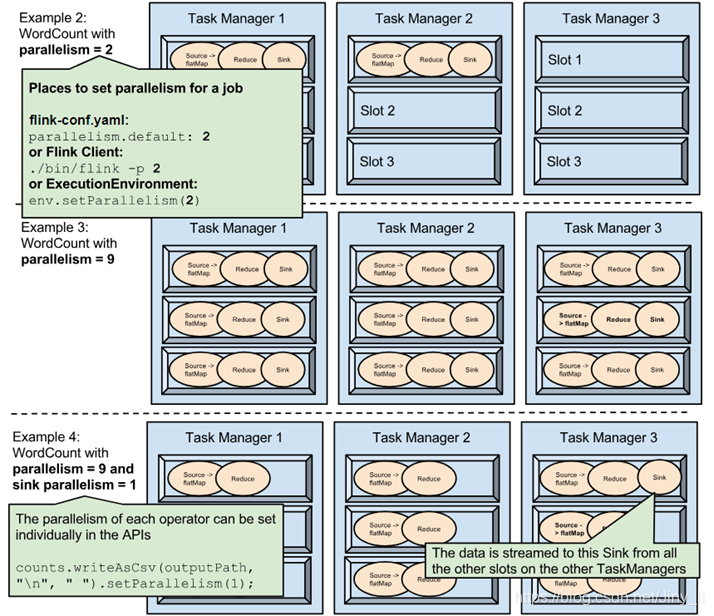
算子、数据源和sink的并行度可以通过调用 setParallelism()方法来指定
-
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
-
DataStream<
String>
text = [...]
-
DataStream<Tuple2<
String,
Integer>> wordCounts =
text
-
.flatMap(
new LineSplitter())
-
.keyBy(
0)
-
.timeWindow(Time.seconds(
5))
-
.sum(
1).setParallelism(
5);
-
-
wordCounts.print();
-
-
env.execute(
"Word Count Example");
并行度设置之Execution Environment Level
执行环境(任务)的默认并行度可以通过调用setParallelism()方法指定。为了以并行度3来执行所有的算子、数据源和data sink, 可以通过如下的方式设置执行环境的并行度:
-
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
-
env.setParallelism(
3);
-
-
DataStream<
String>
text = [...]
-
DataStream<Tuple2<
String,
Integer>> wordCounts = [...]
-
wordCounts.print();
-
-
env.execute(
"Word Count Example");
并行度设置之Client Level
并行度可以在客户端将job提交到Flink时设定。对于CLI客户端,可以通过-p参数指定并行度:
./bin/flink run -p 10 ../examples/*WordCount-java*.jar
并行度设置之System Level
在系统级可以通过设置flink-conf.yaml文件中的parallelism.default属性来指定所有执行环境的默认并行度
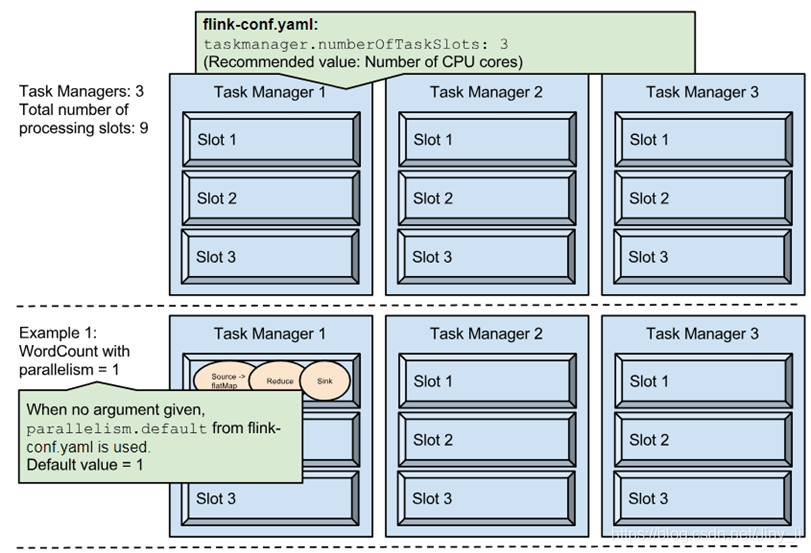
并行度设置的优先级














 694
694











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









