








原视频链接:不存在的网站,翻译此视频并发布已获得原作者同意。
Java进程的内存占用[译] Part 2 - AndreiPangin
JVM运行时 - JIT 编译器
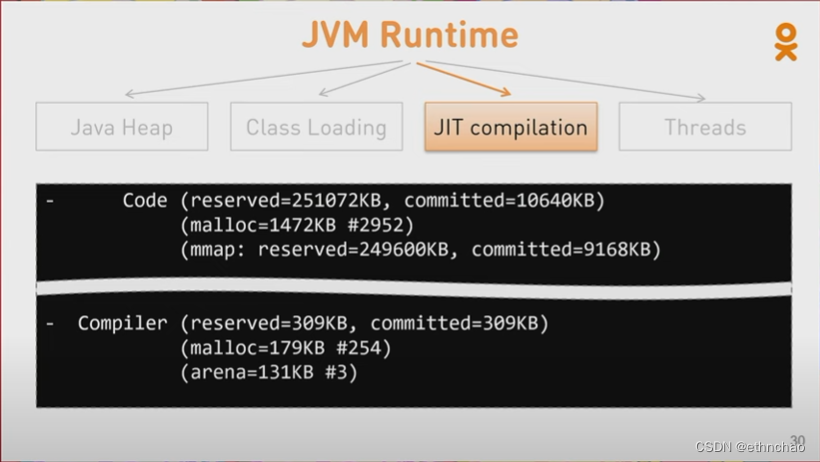
还有什么其他JVM内存占用部分?JIT编译器!又分为两部分:专门用于 JIT 编译的代码和编译器。

Code Cache(代码缓存)存放了编译后的代码,不只是method,所以即使你完全打开了JIT编译,解释器和一些运行时stubs(这部分知识我没接触过)也放在Code Cache。有两个选项用于控制初始化(-XX:InitialCodeCacheSize)和最大(-XX:ReservedCodeCacheSize)Code Cache 大小。
同样的,类似GC,这儿也有另外的一个部分,许多的JIT 编译算法也需要额外的内存,用来构建IR Graph,基本上运行编译算法需要一部分内存。此内存大致与编译器线程数成正比。
这里给大家一个问题,GraalVM(属于JVM的一种,是OpenJDK其中的一种实现)是否也需要Code Cache、Compiler Arenas?你们是怎么认为的呢?事实上,GraalVM是用Java写的,运行的时候就像一个普通的Java应用,所以它在Java堆中构建了自己的结构,而不是堆外内存(off-heap memory)。
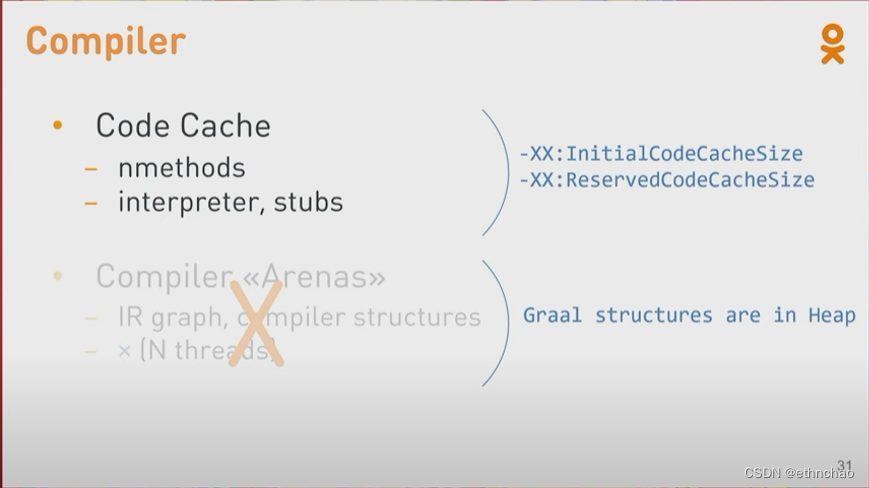
所以Graal是没有Compiler Arenas的,但是编译后的代码仍然放在Code Cache中。

Code Cache有多大呢?HotSpot有两个JIT编辑器:C1和C2,或者C1和Graal。为了编译更多的代码,默认的Code Cache大小的增长因子是5,反过来也一样,所以如果由于何种原因,禁用了TieredCompilation(-XX:-TieredCompilation,分层编译),CodeCache大小会小很多,所以会变成48M,对于编译大型项目是不够的,有时候240M都不够。有一天我们发现我们一个服务发生了性能下降,是由于Code Cache的问题,当Code Cache增长到限制值,HotSpot开始丢弃早期编译的代码,但因为这些代码属于刚刚编译,所以重新编译了一次,您猜怎么着,这些代码经历了编译、丢弃、再编译、再丢弃,如此循环,浪费了很多时间、CPU资源。
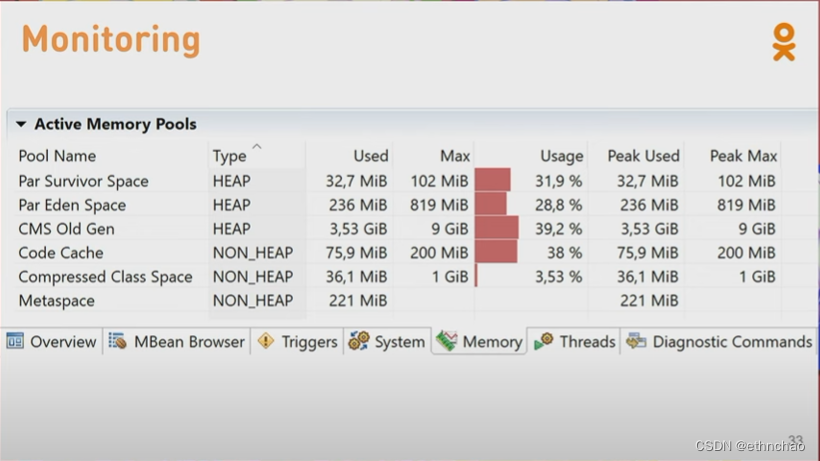
所以在这次异常事件后,我们开始监控Code Cache 内存池,和其他内存池一样,这些统计信息是可以很容易获取到的,都是些标准的MX Bean,可以通过JMX获取。例如我们用Java Mission Controll连上后,切换到内存选项卡,你就能看到Code Cache、Metaspace等等使用的内存总量。不过并非所有的内存池都是这么简单就能监控到的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









