







Hadoop 环境搭建(基于Hadoop 2.0)
1.上传Hadoop包
将包上传到/usr/lcoal目录下,并用tar -zxvf命令解压
2.1单节点配置
安装单节点的Hadoop不需要任何配置,这种方式经常用来调试
2.2伪分布式配置
所有的配置文件都在解压后的文件夹的/usr/local/hadoop/etc/hadoop目录下
- 修改hadoop-env.sh配置
因为hadoop依赖JDK,这里修改是为了配置JAVA_HOME

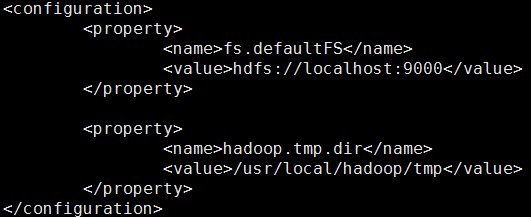
- 修改core-site.xml
配置HDFS的NameNode地址和Hadoop运行时产生文件的存放目录
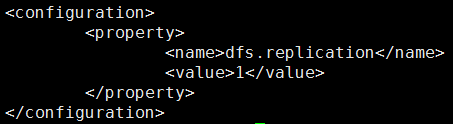
- 修改hdfs-site.xml
配置HDFS中副本的数量(既是,一个文件总共的数量)
因为我们搭建的伪分布式,只有一台机器,所以只保存一份。一般默认值是3
- 修改mapred-site.xml
如果没有mapred-site.xml,可以将mapred-site.xml.template的内容直接复制过来
指定Hadoop以后运行在yarn上
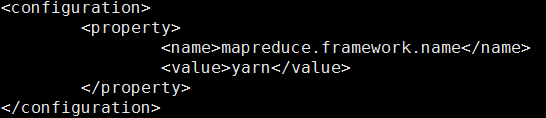
- 修改yarn-site.xml
指定NodeManager获取数据的方式是shuffle,指定resourcemanager的地址

3.运行hadoop
①将hadoop的bin添加到环境变量
修改/etc/profile文件,添加环境变量配置

接着,使用source /etc/profile命令让修改后的配置文件立即生效
②初始化HDFS(只有首次启动需要格式化)
hadoop namenode -format
现在使用:hdfs namenode -format

③启动hadoop
- 配置免密码登陆:
cd ~,然后cd .ssh/
输入ssh-keygen -t rsa,接着4个回车
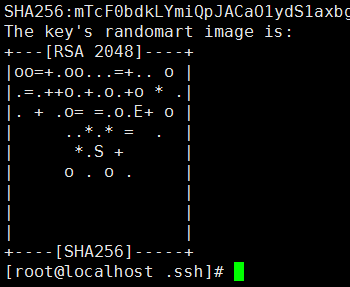
这样.ssh文件夹下就生成了公钥:id_rsa.pub私钥:id_rsa
将公钥拷贝到自己的指定目录下,实现自我免登录cp id_rsa.pub authorized_keys或者用命令ssh-copy-id 目的服务器IP
- 不配置免密码登陆,密码为服务器密码
/usr/local/hadoop/sbin目录下,进行启动
./start-all.sh
现在使用:./start-dfs.sh先启动HDFS,./start-yarn.sh再启动YARN
用jps命令可以看到已经启动的进程,验证是否成功
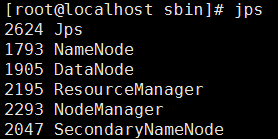
每次在关机之前记得关闭hadoop和yarn
./stop-all.sh
现在使用:./stop-dfs.sh和./stop-yarn.sh
4.测试Hadoop
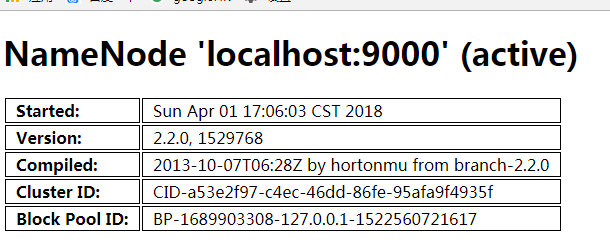
http://192.168.72.129:50070 (HDFS管理界面)
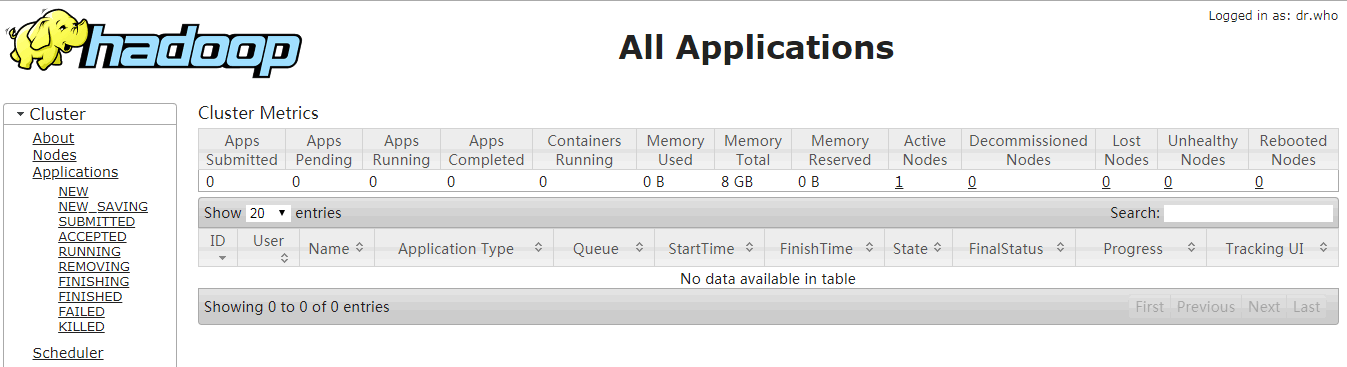
http://192.168.72.129:8088 (YARN管理界面)
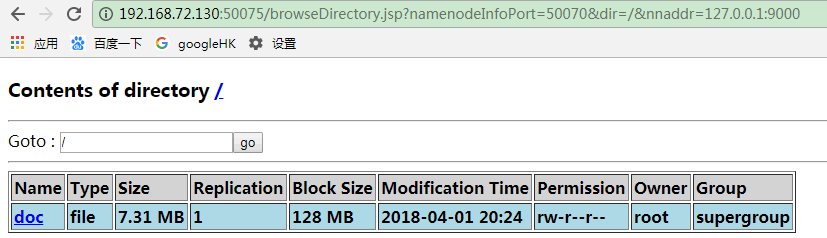
文件上传测试:
hadoop fs -put /usr/local/temp/hadoop入门实战手册.rar hdfs://localhost:9000/doc
附:可能遇到的问题
WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform
这个问题是因为:apache官网提供的二进制包,里面的native库,是32位的,而我们的服务器是64位的。
解决方案:在64位CentOS上编译 Hadoop源码,然后替换掉/usr/local/hadoop/lib/native文件夹- 如果发现节点没有启动,就去
hadoop/logs目录下去查看日志输出 - 访问HDFS出错
core-site.xml中配置ip:端口无法启动dataNode,而配置主机名:端口就可以。但是,问题在于如果配置主机名localhost,在访问HDFS Web时,域名为localhost就访问不到,需要手动填写IP(待后续探究。。。。)















 5435
5435

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









