




NameNode的功能:
NameNode通过执行以下任务来管理文件系统命名空间。
- 维护与文件系统相关的元数据,如文件层次结构和每个文件的块位置;
- 管理用户对数据文件的访问;
- 数据块和集群中存储节点的映射关系;
- 执行对文件系统的操作,如打开或关闭文件以及目录;
- 为集群中的DataNode成员提供注册服务并处理来自DataNode的周期性心跳;
- 确定哪些节点上的数据应该被复制,并删除超出的复制块;
- 处理DataNode发送的块报告并维护数据库的存放位置。
虽然Namenode知道HDFS块的所对应的DataNode节点信息,但是它不会直接存储块对应的位置,它只是根据在启动集群时datanode发送的信息来重构,之后将信息保存在内存中,用于快速访问。
来看看NameNode在hadoop集群中的作用,重点是metadata hdfs元数据的管理。如果单节点的namenode挂掉的话,试想hadoop集群还能启动的起来吗?
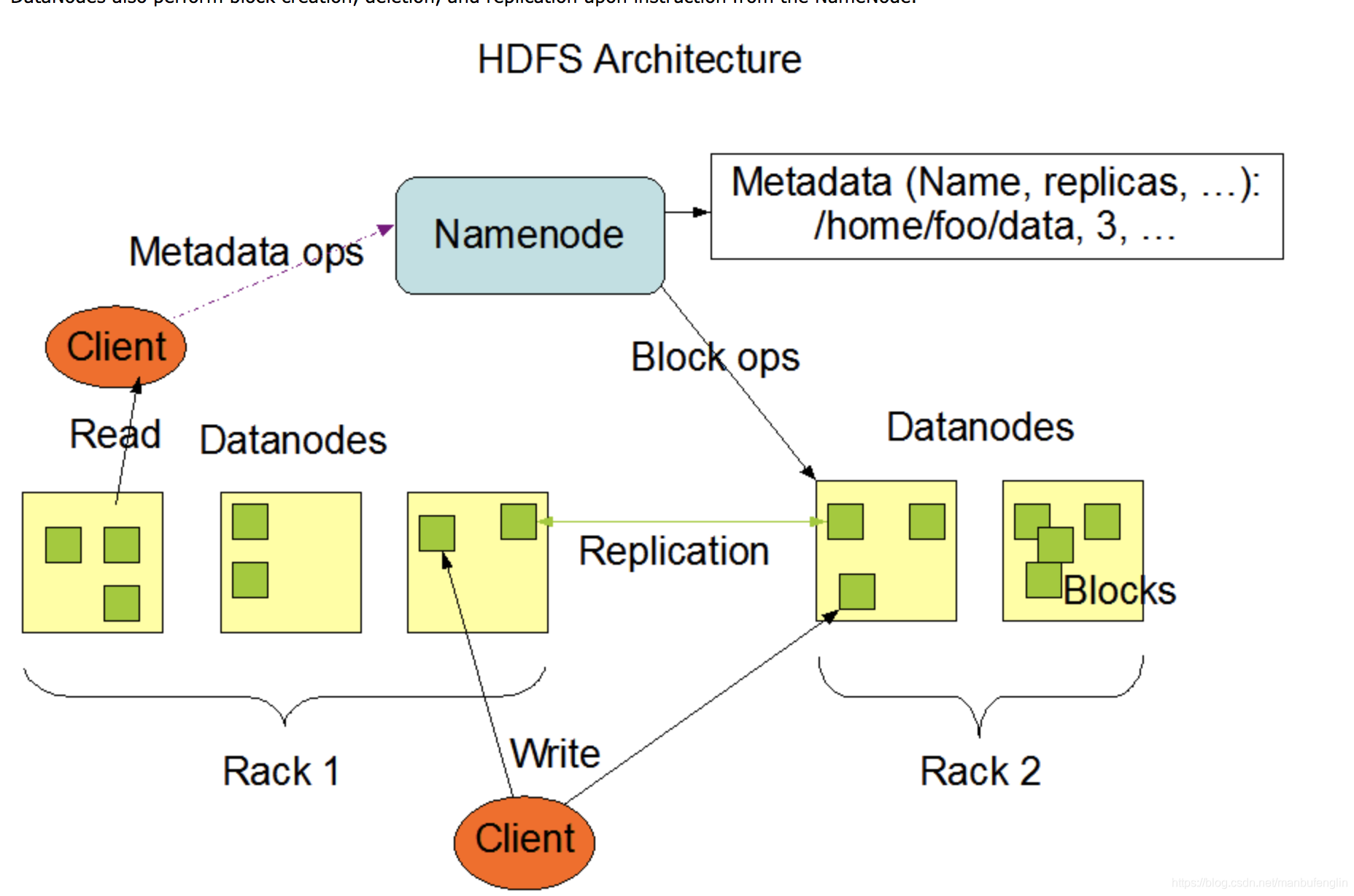
单节点的namenode宕机后,集群是不能正常启动的,更不会对外正常提供服务了。这让namenode显得尤为重要,所以namenode节点一般会有2个,一个namenode,第二个 namenode主要为活跃的namenode做 standby 的。
DataNode 的功能:
DataNode 根据NameNode发送的指令执行以下功能:
- 通过在本地文件系统上存储数据块提供存储功能;
- 完成客户端对DataNodes上存储的数据的读写请求;
- 创建和删除数据块;
- 在集群中复制数据;
- 通过定期发送块报告和心跳来保持与NameNode的联系。心跳确认DataNode是活的和健康的,块报告显示由DataNode管理的块信息。


















 6368
6368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









